3D Scene Rendering with Multimodal Gaussian Splatting
作者: Chi-Shiang Gau, Konstantinos D. Polyzos, Athanasios Bacharis, Saketh Madhuvarasu, Tara Javidi
分类: cs.CV, cs.AI, cs.RO
发布日期: 2026-02-19
💡 一句话要点
提出基于多模态高斯溅射的3D场景渲染方法,提升恶劣环境下的重建质量。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 三维场景重建 高斯溅射 多模态融合 射频传感 自动驾驶
📋 核心要点
- 传统视觉GS方法依赖大量相机视图,在恶劣环境下性能下降,初始化成本高。
- 提出多模态框架,融合射频传感与GS渲染,利用射频信号的鲁棒性提升性能。
- 通过射频深度预测初始化高斯函数,实现高质量3D点云,提升渲染保真度。
📝 摘要(中文)
三维场景重建和渲染是计算机视觉中的核心任务,广泛应用于工业监控、机器人和自动驾驶等领域。近年来,三维高斯溅射(GS)及其变体在保持高计算和内存效率的同时,实现了令人印象深刻的渲染保真度。然而,传统的基于视觉的GS流程通常依赖于足够数量的相机视图来初始化高斯基元并训练其参数,这通常会在初始化期间产生额外的处理成本,并且在视觉线索不可靠的情况下(例如恶劣天气、低照度或部分遮挡)效果不佳。为了应对这些挑战,并受到射频(RF)信号对天气、光照和遮挡的鲁棒性的启发,我们引入了一种多模态框架,该框架将射频传感(例如车载雷达)与基于GS的渲染相结合,作为一种更有效和更鲁棒的视觉GS渲染替代方案。所提出的方法能够仅从稀疏的基于射频的深度测量中进行有效的深度预测,从而产生高质量的3D点云,用于在各种GS架构中初始化高斯函数。数值测试表明,明智地将射频传感纳入GS流程的优点,实现了由射频信息结构精度驱动的高保真度3D场景渲染。
🔬 方法详解
问题定义:现有基于视觉的三维高斯溅射(GS)方法在恶劣天气、低光照或存在遮挡等视觉信息不足的情况下,难以准确重建三维场景。这些方法依赖于大量的相机视图进行初始化和训练,导致计算成本高昂,且在视觉线索不可靠时性能显著下降。
核心思路:论文的核心思路是利用射频(RF)传感技术(如车载雷达)对环境的感知能力,弥补视觉信息的不足。射频信号对天气、光照和遮挡具有更强的鲁棒性,可以提供可靠的深度信息,用于初始化高斯基元,从而改善GS渲染的质量和效率。
技术框架:该多模态框架主要包含两个阶段:首先,利用射频传感器获取稀疏的深度测量数据。然后,基于这些深度数据预测高质量的三维点云,并将其作为GS算法的初始化。最后,使用标准GS训练流程优化高斯参数,实现高保真度的三维场景渲染。该框架可以灵活地应用于不同的GS架构。
关键创新:该论文的关键创新在于将射频传感技术与三维高斯溅射渲染相结合,提出了一种多模态的三维场景重建方法。与传统的纯视觉方法相比,该方法在恶劣环境下具有更强的鲁棒性,并且可以利用稀疏的射频深度信息进行有效的初始化,从而降低了计算成本。
关键设计:论文的关键设计在于如何有效地利用稀疏的射频深度信息来初始化高斯函数。具体的技术细节包括:如何从稀疏的射频深度数据中生成高质量的三维点云;如何将这些点云转换为高斯基元;以及如何设计损失函数来优化高斯参数,从而实现高保真度的渲染效果。论文可能还涉及了射频数据与视觉数据的校准和融合策略。
🖼️ 关键图片
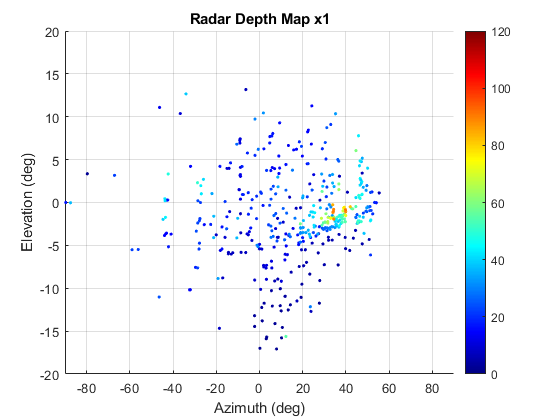
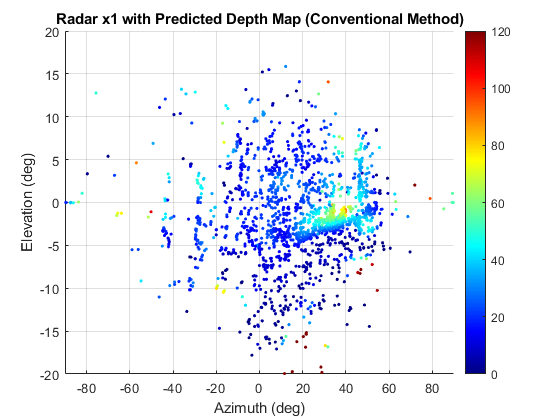
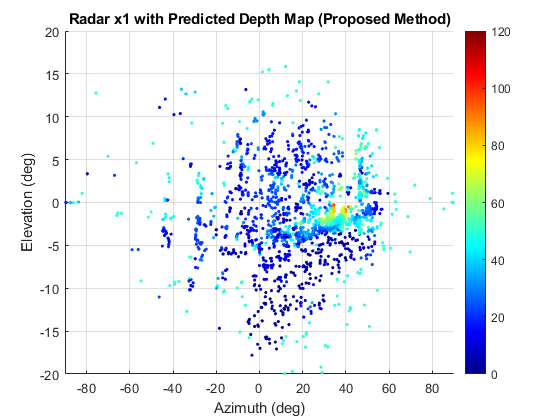
📊 实验亮点
论文通过数值实验验证了所提出方法的有效性。实验结果表明,与传统的基于视觉的GS方法相比,该方法在恶劣环境下能够显著提高三维场景渲染的保真度。具体性能提升数据未知,但强调了射频信息在结构精度上的贡献。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、机器人导航、工业监控等领域。在自动驾驶中,即使在雨雾天气或光照不足的情况下,也能利用射频信息辅助视觉感知,提高环境感知的可靠性。在机器人导航中,可以帮助机器人在复杂环境中进行更准确的定位和路径规划。在工业监控中,可以实现对生产过程的实时三维重建和监控。
📄 摘要(原文)
3D scene reconstruction and rendering are core tasks in computer vision, with applications spanning industrial monitoring, robotics, and autonomous driving. Recent advances in 3D Gaussian Splatting (GS) and its variants have achieved impressive rendering fidelity while maintaining high computational and memory efficiency. However, conventional vision-based GS pipelines typically rely on a sufficient number of camera views to initialize the Gaussian primitives and train their parameters, typically incurring additional processing cost during initialization while falling short in conditions where visual cues are unreliable, such as adverse weather, low illumination, or partial occlusions. To cope with these challenges, and motivated by the robustness of radio-frequency (RF) signals to weather, lighting, and occlusions, we introduce a multimodal framework that integrates RF sensing, such as automotive radar, with GS-based rendering as a more efficient and robust alternative to vision-only GS rendering. The proposed approach enables efficient depth prediction from only sparse RF-based depth measurements, yielding a high-quality 3D point cloud for initializing Gaussian functions across diverse GS architectures. Numerical tests demonstrate the merits of judiciously incorporating RF sensing into GS pipelines, achieving high-fidelity 3D scene rendering driven by RF-informed structural accuracy.