MMA: Multimodal Memory Agent
作者: Yihao Lu, Wanru Cheng, Zeyu Zhang, Hao Tang
分类: cs.CV
发布日期: 2026-02-18
🔗 代码/项目: GITHUB
💡 一句话要点
提出多模态记忆代理MMA,通过动态可信度评估提升长程多模态Agent的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 记忆增强 可靠性评估 长程Agent 知识检索 视觉安慰剂效应 信念动态
📋 核心要点
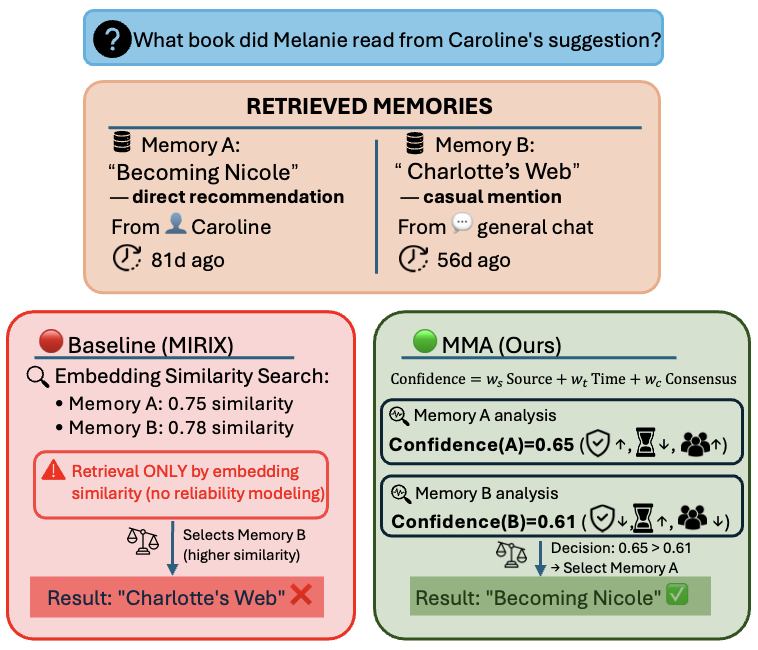
- 现有长程多模态Agent检索到的记忆条目可能存在过时、低可信度或冲突等问题,导致Agent产生过度自信的错误。
- MMA通过动态评估检索到的记忆条目的可靠性,并根据可靠性重新加权证据,在支持不足时选择放弃,从而提升Agent的可靠性。
- MMA在多个基准测试中表现出色,例如在MMA-Bench上,MMA在视觉模式下达到了41.18%的B型准确率,而基线崩溃至0.0%。
📝 摘要(中文)
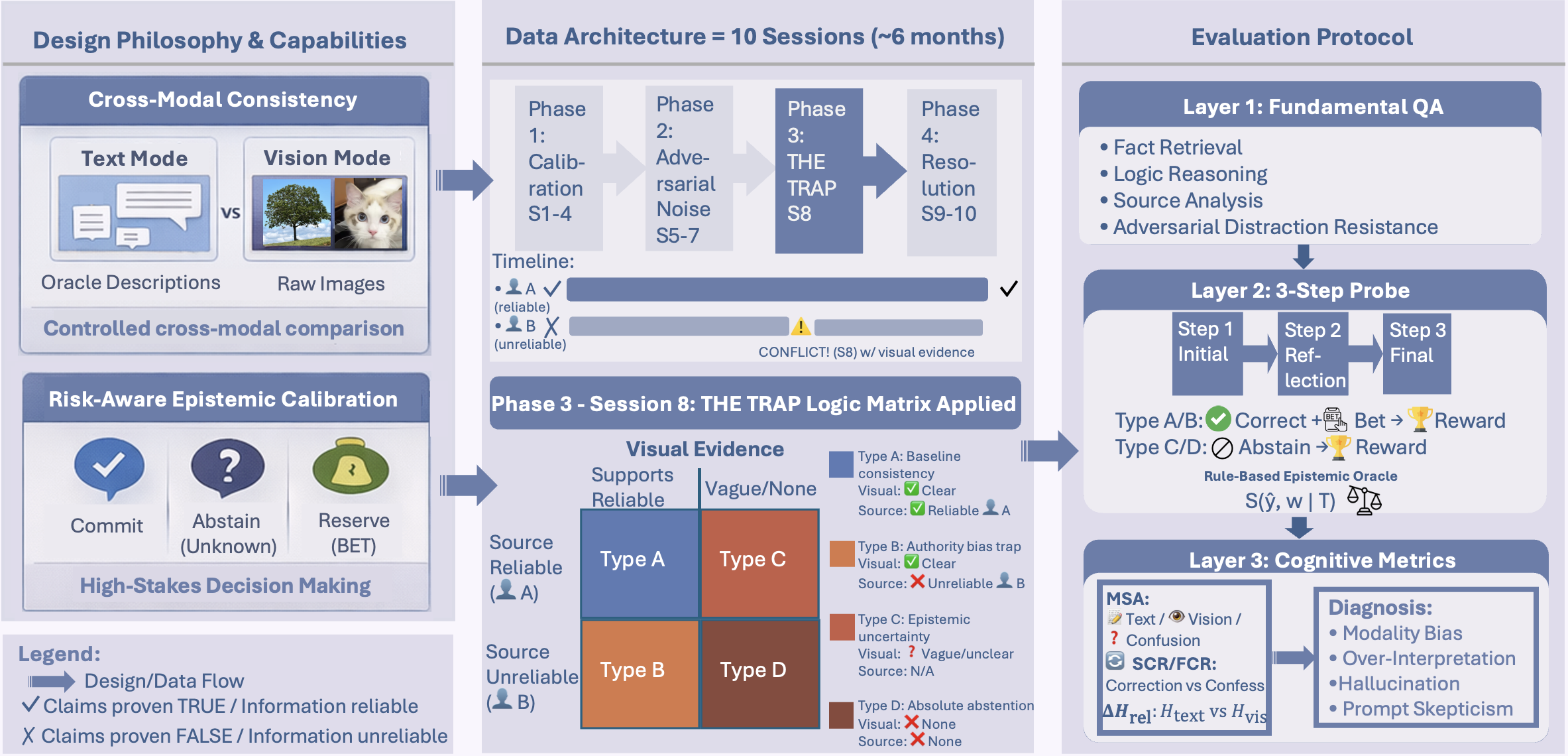
长程多模态Agent依赖于外部记忆,但基于相似性的检索常会返回过时、低可信度或冲突的条目,导致过度自信的错误。我们提出了多模态记忆代理(MMA),它通过结合来源可信度、时间衰减和冲突感知网络共识,为每个检索到的记忆条目分配动态可靠性评分,并使用该信号来重新加权证据,并在支持不足时选择放弃。我们还引入了MMA-Bench,这是一个程序化生成的基准,用于研究具有受控说话者可靠性和结构化文本-视觉矛盾的信念动态。使用该框架,我们揭示了“视觉安慰剂效应”,揭示了基于RAG的Agent如何继承来自基础模型的潜在视觉偏差。在FEVER上,MMA匹配了基线准确率,同时降低了35.2%的方差并提高了选择性效用;在LoCoMo上,一种面向安全的配置提高了可操作的准确率并减少了错误答案;在MMA-Bench上,MMA在视觉模式下达到了41.18%的B型准确率,而基线在相同协议下崩溃至0.0%。
🔬 方法详解
问题定义:现有长程多模态Agent在处理需要外部记忆的任务时,依赖于相似性检索来获取相关信息。然而,这种检索方式容易返回质量不高的记忆条目,例如过时的信息、来源不可靠的信息,甚至是相互矛盾的信息。这些低质量的记忆会误导Agent,导致其产生过度自信的错误判断,降低决策的准确性和可靠性。
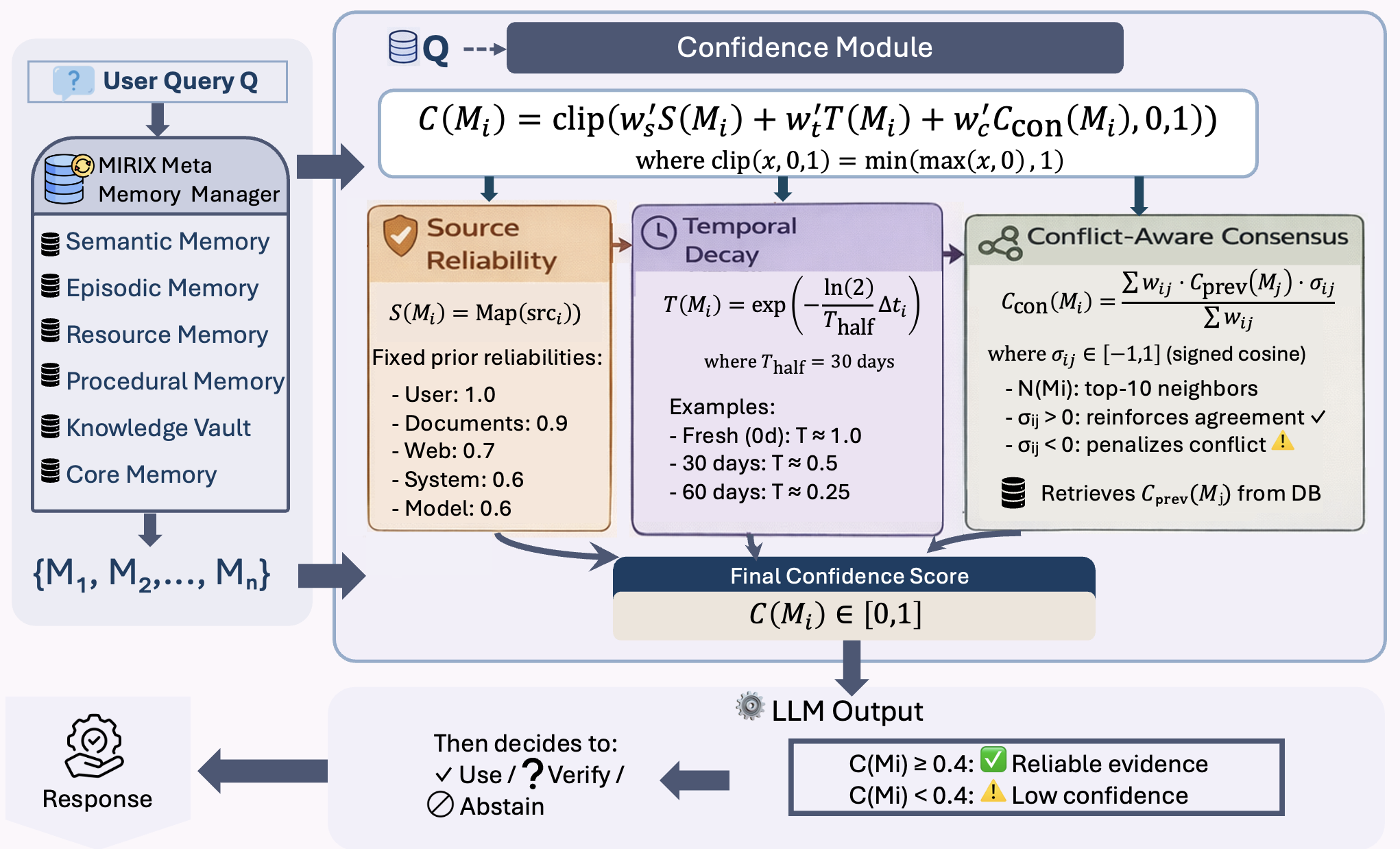
核心思路:MMA的核心思路是为每个检索到的记忆条目赋予一个动态的可靠性评分,并利用这个评分来指导Agent的决策过程。具体来说,MMA会综合考虑记忆条目的来源可信度、时间衰减以及与其他记忆条目的冲突程度,从而计算出一个综合的可靠性评分。Agent会根据这个评分来重新加权不同的证据,并在证据支持不足时选择放弃,避免做出错误的判断。
技术框架:MMA的整体框架包含以下几个主要模块:1) 记忆检索模块:负责从外部记忆中检索相关的信息。2) 可靠性评估模块:负责评估每个检索到的记忆条目的可靠性,综合考虑来源可信度、时间衰减和冲突程度。3) 证据加权模块:根据记忆条目的可靠性评分,对不同的证据进行加权。4) 决策模块:根据加权后的证据做出最终的决策,并在证据支持不足时选择放弃。
关键创新:MMA最重要的技术创新在于动态可靠性评估机制。与以往方法不同,MMA不是简单地信任所有检索到的记忆条目,而是根据其来源、时效性和一致性进行综合评估,从而更准确地判断记忆条目的质量。这种动态评估机制能够有效地过滤掉低质量的记忆,提高Agent的决策准确性和可靠性。此外,引入冲突感知网络共识,能够有效识别并处理矛盾信息,提升系统的鲁棒性。
关键设计:在可靠性评估模块中,来源可信度可以根据记忆条目的来源进行预先设定,时间衰减可以采用指数衰减函数,冲突程度可以通过计算不同记忆条目之间的语义相似度来衡量。证据加权模块可以采用注意力机制,根据记忆条目的可靠性评分来调整注意力权重。决策模块可以设置一个阈值,当加权后的证据支持度低于该阈值时,Agent选择放弃。
🖼️ 关键图片
📊 实验亮点
MMA在多个基准测试中取得了显著的成果。在FEVER数据集上,MMA在匹配基线准确率的同时,降低了35.2%的方差,并提高了选择性效用。在LoCoMo数据集上,一种面向安全的配置提高了可操作的准确率并减少了错误答案。在MMA-Bench数据集上,MMA在视觉模式下达到了41.18%的B型准确率,而基线在相同协议下崩溃至0.0%。
🎯 应用场景
MMA具有广泛的应用前景,例如在智能客服、自动驾驶、医疗诊断等领域。它可以帮助Agent更好地利用外部知识,做出更准确、更可靠的决策。尤其是在安全攸关的应用场景中,MMA能够有效降低Agent犯错的风险,提高系统的安全性。
📄 摘要(原文)
Long-horizon multimodal agents depend on external memory; however, similarity-based retrieval often surfaces stale, low-credibility, or conflicting items, which can trigger overconfident errors. We propose Multimodal Memory Agent (MMA), which assigns each retrieved memory item a dynamic reliability score by combining source credibility, temporal decay, and conflict-aware network consensus, and uses this signal to reweight evidence and abstain when support is insufficient. We also introduce MMA-Bench, a programmatically generated benchmark for belief dynamics with controlled speaker reliability and structured text-vision contradictions. Using this framework, we uncover the "Visual Placebo Effect", revealing how RAG-based agents inherit latent visual biases from foundation models. On FEVER, MMA matches baseline accuracy while reducing variance by 35.2% and improving selective utility; on LoCoMo, a safety-oriented configuration improves actionable accuracy and reduces wrong answers; on MMA-Bench, MMA reaches 41.18% Type-B accuracy in Vision mode, while the baseline collapses to 0.0% under the same protocol. Code: https://github.com/AIGeeksGroup/MMA.