ReMoRa: Multimodal Large Language Model based on Refined Motion Representation for Long-Video Understanding
作者: Daichi Yashima, Shuhei Kurita, Yusuke Oda, Komei Sugiura
分类: cs.CV
发布日期: 2026-02-18
💡 一句话要点
ReMoRa:基于精细化运动表征的多模态大语言模型,用于长视频理解
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 多模态大语言模型 运动表征 关键帧提取 视频理解 时间动态建模 视觉信息压缩
📋 核心要点
- 现有方法处理长视频时,直接处理RGB帧计算量大且冗余,自注意力机制的复杂度随视频长度呈平方增长。
- ReMoRa通过保留关键帧和引入运动表征来压缩视频信息,运动表征作为光流的代理,有效捕捉时间动态。
- 实验结果表明,ReMoRa在LongVideoBench、NExT-QA和MLVU等长视频理解基准测试中,性能优于现有方法。
📝 摘要(中文)
多模态大语言模型(MLLM)在各种任务中取得了显著成功,但长视频理解仍然是一个重大挑战。本文着重研究MLLM在视频理解方面的应用。由于自注意力机制与序列长度呈二次方复杂度关系,处理完整的RGB帧流在计算上是难以实现的,并且存在高度冗余。因此,我们提出了ReMoRa,一种视频MLLM,它通过直接处理压缩表示来理解视频。ReMoRa保留稀疏的RGB关键帧以获取外观信息,同时将时间动态编码为运动表示,从而无需按顺序处理RGB帧。这些运动表示充当光流的紧凑代理,在无需完整帧解码的情况下捕获时间动态。为了消除基于块的运动的噪声和低保真度,我们引入了一个模块来去噪并生成精细的运动表示。此外,我们的模型以线性方式压缩这些特征,使其能够随序列长度扩展。通过在全面的长视频理解基准测试套件上进行的大量实验,我们证明了ReMoRa的有效性。ReMoRa在多个具有挑战性的基准测试中优于基线方法,包括LongVideoBench、NExT-QA和MLVU。
🔬 方法详解
问题定义:长视频理解任务面临计算量大和信息冗余的挑战。直接处理原始RGB帧序列,特别是对于长视频,会导致计算成本过高,并且相邻帧之间存在大量冗余信息,影响模型的效率和性能。现有方法难以在计算资源有限的情况下有效处理长视频。
核心思路:ReMoRa的核心思路是通过提取关键帧和构建运动表征来压缩视频信息。关键帧保留了视频中的关键视觉信息,而运动表征则捕捉了视频中的时间动态。这种方法避免了直接处理所有RGB帧,从而显著降低了计算复杂度。
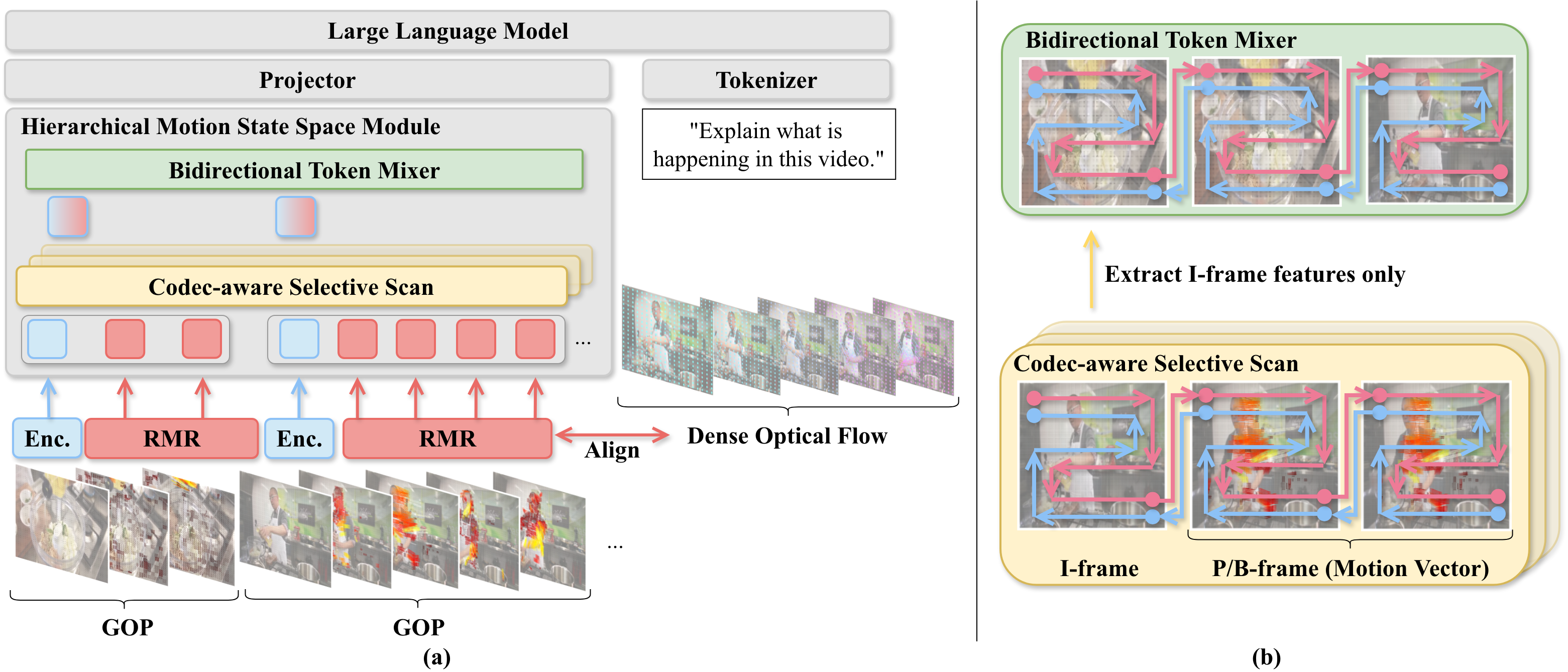
技术框架:ReMoRa的整体框架包括以下几个主要模块:1) 关键帧提取模块:选择视频中的关键帧,保留视频中的主要视觉信息。2) 运动表征模块:将视频的时间动态编码为运动表征,作为光流的紧凑代理。3) 运动表征精细化模块:用于去噪和生成精细的运动表征,提高运动信息的质量。4) 多模态大语言模型:将关键帧和运动表征输入到MLLM中,进行视频理解和推理。
关键创新:ReMoRa的关键创新在于使用运动表征来代替直接处理RGB帧序列。运动表征能够有效地捕捉视频中的时间动态,同时显著降低计算复杂度。此外,运动表征精细化模块能够提高运动信息的质量,从而提升模型的性能。
关键设计:ReMoRa的关键设计包括:1) 稀疏关键帧的选择策略,旨在保留视频中的关键视觉信息。2) 运动表征的编码方式,旨在有效地捕捉视频中的时间动态。3) 运动表征精细化模块的网络结构和损失函数,旨在提高运动信息的质量。具体参数设置和网络结构细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
ReMoRa在LongVideoBench、NExT-QA和MLVU等长视频理解基准测试中取得了显著的性能提升,证明了其有效性。具体性能数据和提升幅度在摘要中有所提及,但未给出具体数值。ReMoRa优于基线方法,表明其在长视频理解方面具有优势。
🎯 应用场景
ReMoRa在视频监控、自动驾驶、智能安防、视频内容分析与检索等领域具有广泛的应用前景。通过高效地理解长视频内容,ReMoRa可以用于异常事件检测、行为识别、场景理解等任务,提升相关系统的智能化水平和效率。未来,ReMoRa有望推动视频理解技术在更多实际场景中的应用。
📄 摘要(原文)
While multimodal large language models (MLLMs) have shown remarkable success across a wide range of tasks, long-form video understanding remains a significant challenge. In this study, we focus on video understanding by MLLMs. This task is challenging because processing a full stream of RGB frames is computationally intractable and highly redundant, as self-attention have quadratic complexity with sequence length. In this paper, we propose ReMoRa, a video MLLM that processes videos by operating directly on their compressed representations. A sparse set of RGB keyframes is retained for appearance, while temporal dynamics are encoded as a motion representation, removing the need for sequential RGB frames. These motion representations act as a compact proxy for optical flow, capturing temporal dynamics without full frame decoding. To refine the noise and low fidelity of block-based motions, we introduce a module to denoise and generate a fine-grained motion representation. Furthermore, our model compresses these features in a way that scales linearly with sequence length. We demonstrate the effectiveness of ReMoRa through extensive experiments across a comprehensive suite of long-video understanding benchmarks. ReMoRa outperformed baseline methods on multiple challenging benchmarks, including LongVideoBench, NExT-QA, and MLVU.