Parameter-Free Adaptive Multi-Scale Channel-Spatial Attention Aggregation framework for 3D Indoor Semantic Scene Completion Toward Assisting Visually Impaired
作者: Qi He, XiangXiang Wang, Jingtao Zhang, Yongbin Yu, Hongxiang Chu, Manping Fan, JingYe Cai, Zhenglin Yang
分类: cs.CV
发布日期: 2026-02-18
备注: 17 pages, 9 figures, 5 tables
💡 一句话要点
提出自适应多尺度注意力聚合框架AMAA,提升单目3D室内语义场景补全性能,辅助视觉障碍人士。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语义场景补全 单目视觉 注意力机制 多尺度融合 辅助感知
📋 核心要点
- 现有单目语义场景补全方法在特征可靠性建模和跨尺度信息传播方面存在不足,导致结构不稳定。
- 提出自适应多尺度注意力聚合框架AMAA,通过通道-空间注意力聚合和自适应特征门控策略来提升特征质量和信息融合。
- 实验表明,AMAA在NYUv2数据集上取得了显著的性能提升,并在嵌入式平台上验证了其可部署性。
📝 摘要(中文)
针对视觉障碍用户的室内辅助感知,3D语义场景补全(SSC)旨在提供结构连贯和语义一致的场景占用信息,这对安全至关重要。然而,现有的单目SSC方法通常缺乏对体素特征可靠性的显式建模,以及对2D-3D投影和多尺度融合过程中跨尺度信息传播的有效调节,容易受到投影扩散和特征纠缠的影响,从而限制了结构稳定性。为了解决这些挑战,本文提出了一个基于MonoScene流程的自适应多尺度注意力聚合(AMAA)框架。AMAA侧重于单目SSC框架内的可靠性导向的特征调节,而非引入更重的骨干网络。具体而言,通过并行通道-空间注意力聚合,在语义和空间维度上联合校准提升的体素特征,同时通过分层自适应特征门控策略稳定多尺度编码器-解码器融合,该策略调节跨尺度的信息注入。在NYUv2基准上的实验表明,AMAA在不显著增加系统复杂性的情况下,相对于MonoScene实现了持续的改进:AMAA实现了27.25%的SSC mIoU(+0.31)和43.10%的SC IoU(+0.59)。此外,在NVIDIA Jetson平台上的系统级部署验证了完整的AMAA框架可以在嵌入式硬件上稳定执行。总而言之,AMAA提高了单目SSC质量,并为针对视觉障碍用户的室内辅助系统提供了一个可靠且可部署的感知框架。
🔬 方法详解
问题定义:现有的单目3D语义场景补全方法在处理室内场景时,由于单目视觉的局限性,容易出现投影扩散和特征纠缠的问题,导致补全的场景结构不稳定,语义信息不准确。这些方法缺乏对体素特征可靠性的有效建模,并且在多尺度特征融合时,没有充分考虑不同尺度特征的重要性,导致信息传递效率低下。
核心思路:本文的核心思路是通过引入自适应多尺度注意力聚合机制,来提升特征的可靠性和信息融合的效率。具体来说,通过通道-空间注意力机制来校准体素特征,突出重要特征,抑制噪声特征。同时,采用分层自适应特征门控策略,来控制不同尺度特征的注入,避免无效信息的干扰。
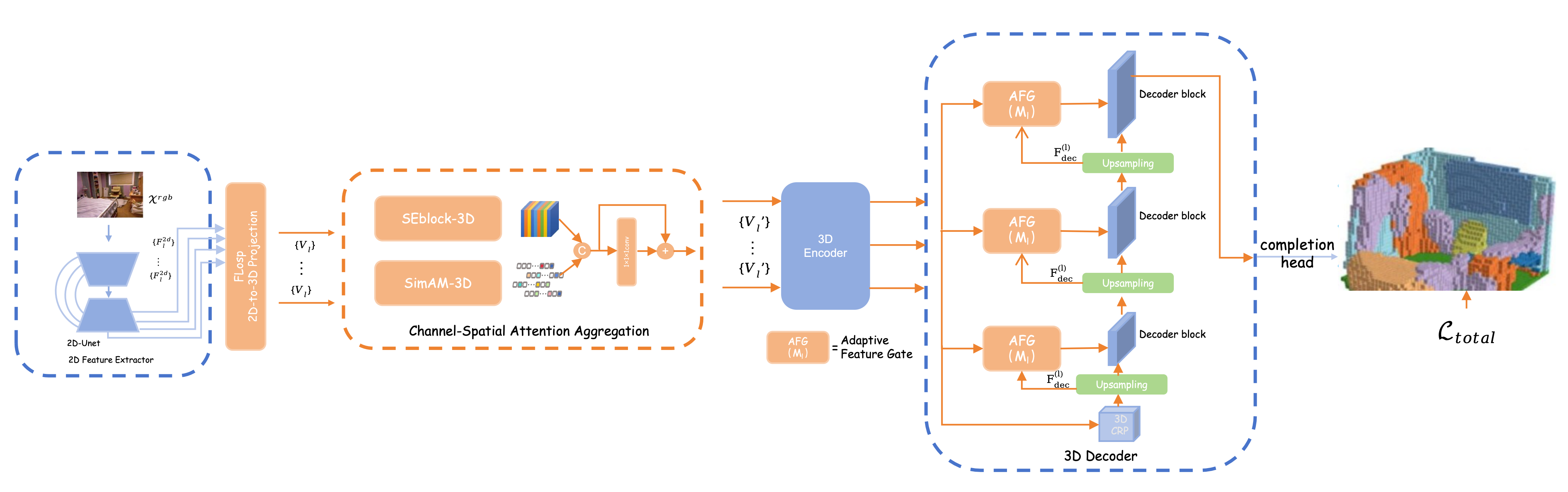
技术框架:AMAA框架基于MonoScene pipeline构建,主要包含以下几个模块:1) 特征提取模块:从单目图像中提取2D特征。2) 2D-3D投影模块:将2D特征投影到3D体素空间。3) 通道-空间注意力聚合模块:对体素特征进行语义和空间维度的联合校准。4) 多尺度编码器-解码器融合模块:通过分层自适应特征门控策略,融合不同尺度的特征。5) 语义场景补全模块:根据融合后的特征,预测场景的语义标签和占用情况。
关键创新:AMAA框架的关键创新在于:1) 提出了并行通道-空间注意力聚合机制,能够有效地校准体素特征,提升特征的可靠性。2) 引入了分层自适应特征门控策略,能够自适应地控制不同尺度特征的注入,避免无效信息的干扰,提升信息融合的效率。3) 在不显著增加系统复杂性的前提下,实现了性能的显著提升。
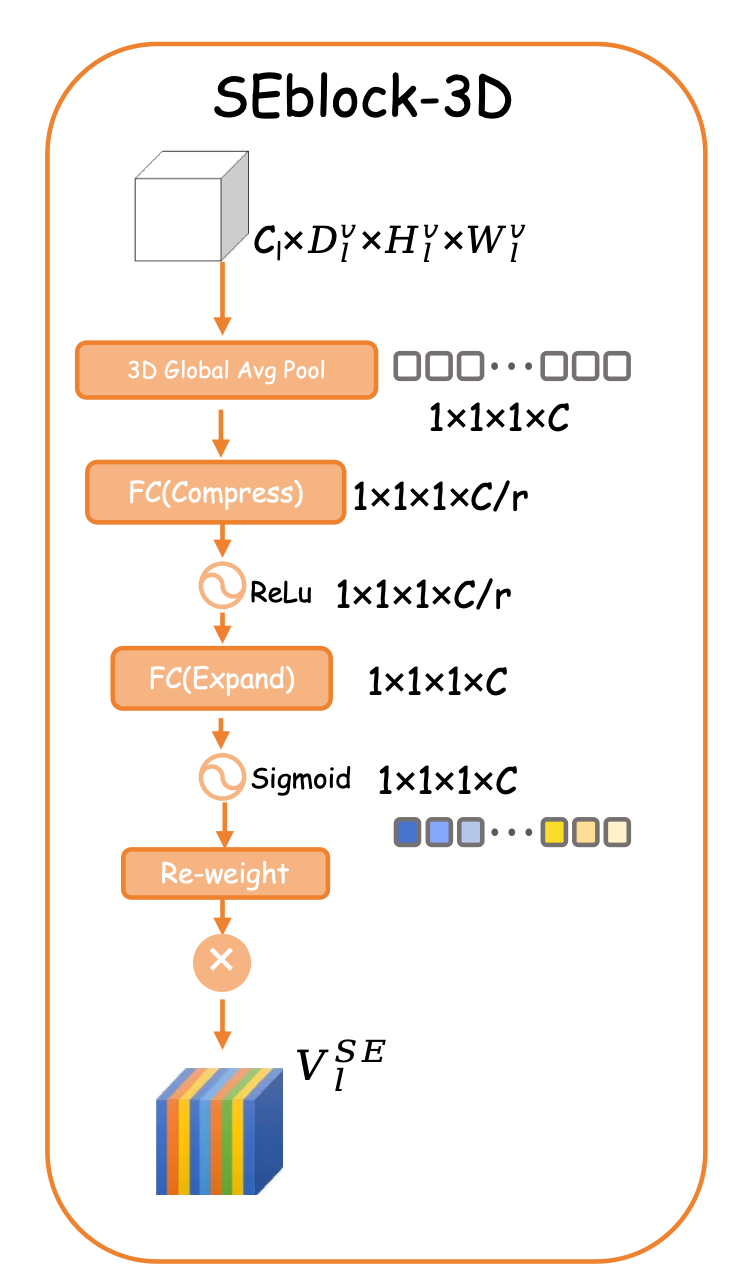
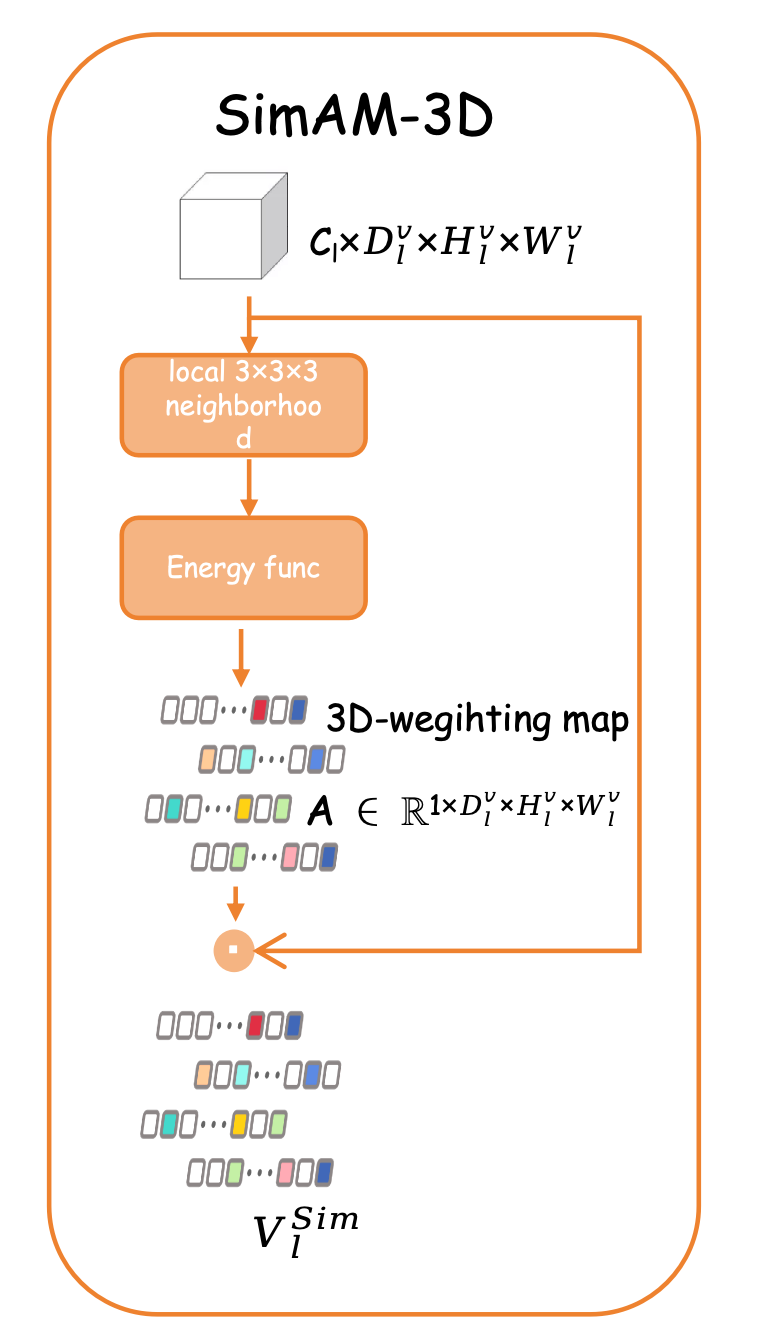
关键设计:通道-空间注意力聚合模块采用并行的通道注意力和空间注意力机制,分别对特征的通道维度和空间维度进行加权。通道注意力机制通过学习每个通道的重要性,来突出重要特征,抑制噪声特征。空间注意力机制通过学习每个空间位置的重要性,来关注重要的区域,忽略不重要的区域。分层自适应特征门控策略采用sigmoid函数来控制每个尺度特征的注入量,sigmoid函数的输入是该尺度特征的全局平均池化结果,通过学习每个尺度特征的重要性,来控制其注入量。
🖼️ 关键图片
📊 实验亮点
AMAA框架在NYUv2数据集上取得了显著的性能提升,SSC mIoU达到27.25%,相比MonoScene提升了0.31个百分点,SC IoU达到43.10%,提升了0.59个百分点。此外,在NVIDIA Jetson平台上进行了系统级部署,验证了AMAA框架可以在嵌入式硬件上稳定执行,具有实际应用价值。
🎯 应用场景
该研究成果可应用于室内辅助导航系统,帮助视觉障碍人士更好地理解周围环境,提高出行安全性。此外,该技术还可应用于机器人导航、智能家居、虚拟现实等领域,提升场景理解和交互能力。未来,可以进一步探索该框架在更复杂环境下的适应性和泛化能力,并结合其他传感器信息,实现更精确和鲁棒的场景理解。
📄 摘要(原文)
In indoor assistive perception for visually impaired users, 3D Semantic Scene Completion (SSC) is expected to provide structurally coherent and semantically consistent occupancy under strictly monocular vision for safety-critical scene understanding. However, existing monocular SSC approaches often lack explicit modeling of voxel-feature reliability and regulated cross-scale information propagation during 2D-3D projection and multi-scale fusion, making them vulnerable to projection diffusion and feature entanglement and thus limiting structural stability.To address these challenges, this paper presents an Adaptive Multi-scale Attention Aggregation (AMAA) framework built upon the MonoScene pipeline. Rather than introducing a heavier backbone, AMAA focuses on reliability-oriented feature regulation within a monocular SSC framework. Specifically, lifted voxel features are jointly calibrated in semantic and spatial dimensions through parallel channel-spatial attention aggregation, while multi-scale encoder-decoder fusion is stabilized via a hierarchical adaptive feature-gating strategy that regulates information injection across scales.Experiments on the NYUv2 benchmark demonstrate consistent improvements over MonoScene without significantly increasing system complexity: AMAA achieves 27.25% SSC mIoU (+0.31) and 43.10% SC IoU (+0.59). In addition, system-level deployment on an NVIDIA Jetson platform verifies that the complete AMAA framework can be executed stably on embedded hardware. Overall, AMAA improves monocular SSC quality and provides a reliable and deployable perception framework for indoor assistive systems targeting visually impaired users.