AFFMAE: Scalable and Efficient Vision Pretraining for Desktop Graphics Cards
作者: David Smerkous, Zian Wang, Behzad Najafian
分类: cs.CV
发布日期: 2026-02-18
备注: Preprint
🔗 代码/项目: GITHUB
💡 一句话要点
AFFMAE:用于桌面级显卡的可扩展高效视觉预训练框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 视觉预训练 掩码自编码器 分层架构 电子显微镜分割
📋 核心要点
- 高分辨率视觉预训练依赖服务器级算力,限制了领域内基础模型的发展。
- AFFMAE通过自适应离网token合并,构建掩码友好的分层预训练框架。
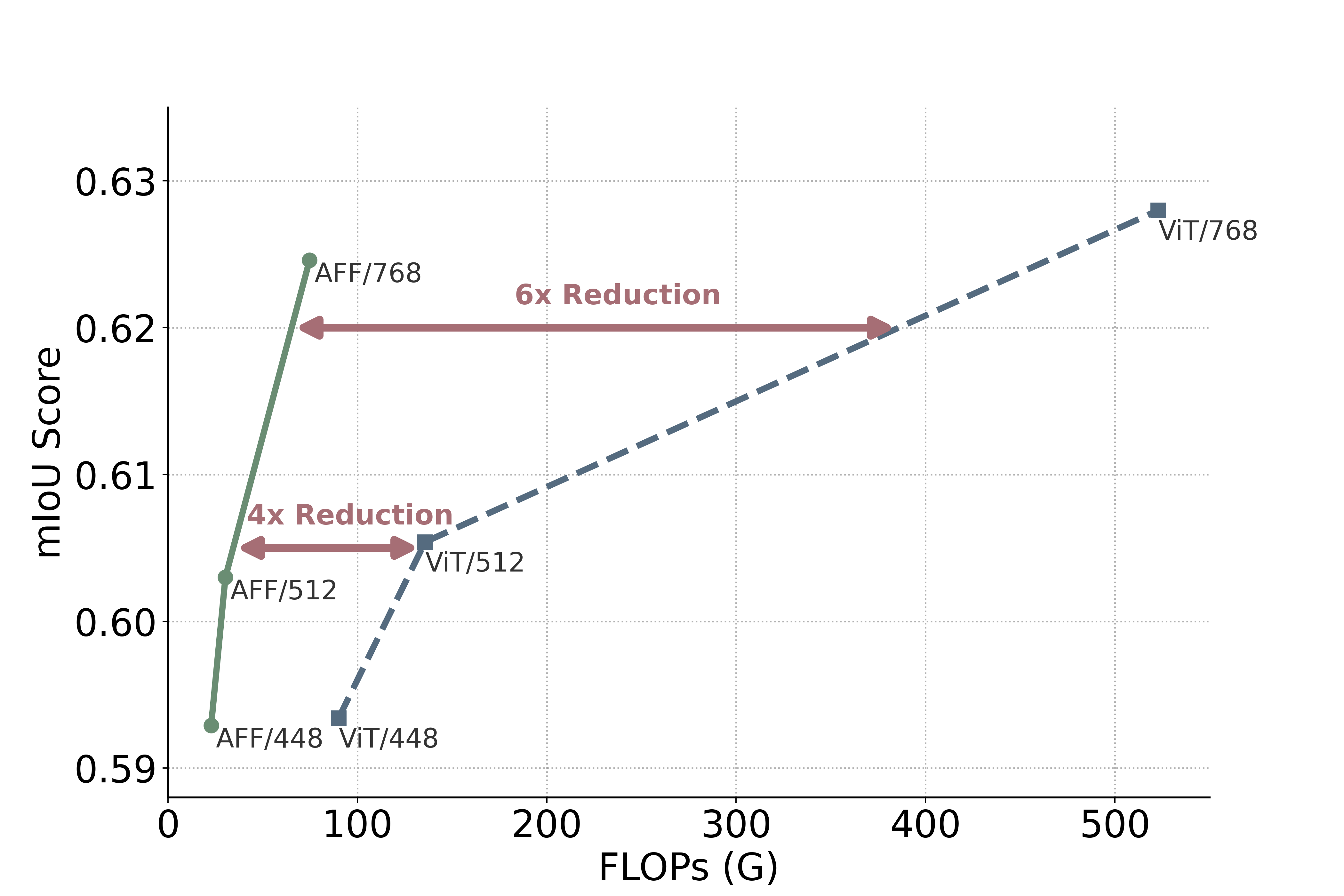
- AFFMAE在电子显微镜分割上,参数量相同情况下,FLOPs降低7倍,内存减半。
📝 摘要(中文)
自监督预训练已经通过实现数据高效的微调改变了计算机视觉领域。然而,高分辨率训练通常需要服务器级别的基础设施,这限制了许多研究实验室进行领域内基础模型开发。掩码自编码器(MAE)通过仅编码可见的tokens来减少计算量,但由于密集的网格先验和对掩码敏感的设计妥协,将MAE与分层下采样架构结合仍然存在结构上的挑战。我们提出了AFFMAE,一个基于自适应、离网token合并的掩码友好的分层预训练框架。通过丢弃被掩码的tokens并仅对可见的tokens执行动态合并,AFFMAE消除了密集网格假设,同时保留了分层可扩展性。我们开发了数值稳定的混合精度Flash风格的集群注意力核,并通过深度监督缓解了稀疏阶段的表示崩溃。在高分辨率电子显微镜分割任务上,AFFMAE在相同参数量下匹配了ViT-MAE的性能,同时减少了高达7倍的FLOPs,减少了一半的内存使用,并在单个RTX 5090上实现了更快的训练。
🔬 方法详解
问题定义:现有高分辨率图像的自监督预训练通常需要大量的计算资源,这使得许多研究实验室难以负担。Masked Autoencoders (MAE)虽然减少了计算量,但与分层架构结合时,由于其对密集网格的依赖以及对掩码的敏感性,面临结构上的挑战。现有方法难以在计算资源有限的情况下,实现高效且可扩展的视觉预训练。
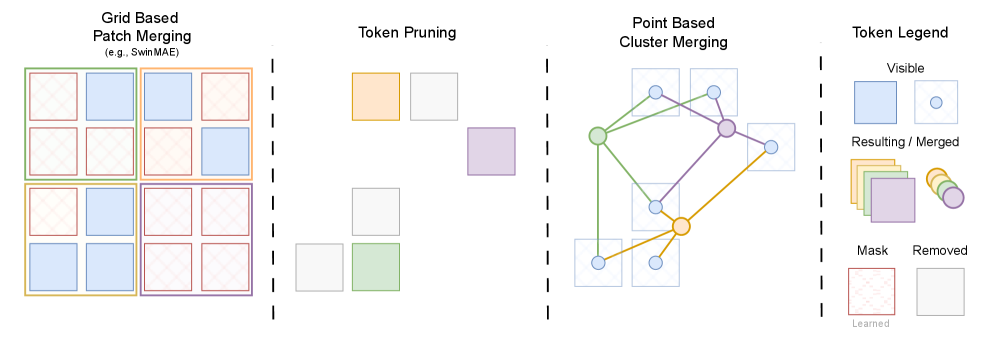
核心思路:AFFMAE的核心思路是设计一种掩码友好的分层预训练框架,该框架能够自适应地合并可见的tokens,从而消除对密集网格的依赖。通过仅对可见tokens进行操作,并动态地调整合并策略,AFFMAE能够在减少计算量的同时,保持分层架构的可扩展性。
技术框架:AFFMAE的整体框架包括以下几个主要阶段:1) 输入图像被分割成tokens,并随机掩码一部分tokens。2) 编码器仅处理可见的tokens,并使用自适应的离网token合并策略来构建分层表示。3) 解码器重建被掩码的tokens。4) 通过深度监督来缓解稀疏阶段的表示崩溃。整个框架旨在实现高效的预训练,并能够在计算资源有限的设备上运行。
关键创新:AFFMAE的关键创新在于其自适应的离网token合并策略。与传统的基于固定网格的合并方法不同,AFFMAE能够根据可见tokens的分布动态地调整合并策略,从而更好地适应掩码操作。此外,AFFMAE还开发了数值稳定的混合精度Flash风格的集群注意力核,进一步提高了计算效率。
关键设计:AFFMAE的关键设计包括:1) 自适应token合并策略,该策略根据可见tokens的分布动态地调整合并区域的大小和形状。2) 混合精度Flash风格的集群注意力核,该核能够有效地利用GPU的计算资源,并减少内存访问。3) 深度监督机制,该机制通过在多个层级上添加辅助损失函数来缓解稀疏阶段的表示崩溃。损失函数包括重建损失和辅助分类损失。
🖼️ 关键图片

📊 实验亮点
AFFMAE在电子显微镜分割任务上取得了显著的性能提升。在相同参数量下,AFFMAE匹配了ViT-MAE的性能,同时减少了高达7倍的FLOPs,减少了一半的内存使用,并在单个RTX 5090上实现了更快的训练。这些结果表明,AFFMAE是一种高效且可扩展的视觉预训练框架。
🎯 应用场景
AFFMAE具有广泛的应用前景,尤其是在计算资源受限的环境下。它可以用于医学图像分析、遥感图像处理、以及其他需要高分辨率图像处理的领域。通过在桌面级显卡上进行高效的预训练,AFFMAE可以加速领域内基础模型的开发,并促进计算机视觉技术在各个领域的应用。
📄 摘要(原文)
Self-supervised pretraining has transformed computer vision by enabling data-efficient fine-tuning, yet high-resolution training typically requires server-scale infrastructure, limiting in-domain foundation model development for many research laboratories. Masked Autoencoders (MAE) reduce computation by encoding only visible tokens, but combining MAE with hierarchical downsampling architectures remains structurally challenging due to dense grid priors and mask-aware design compromises. We introduce AFFMAE, a masking-friendly hierarchical pretraining framework built on adaptive, off-grid token merging. By discarding masked tokens and performing dynamic merging exclusively over visible tokens, AFFMAE removes dense-grid assumptions while preserving hierarchical scalability. We developed numerically stable mixed-precision Flash-style cluster attention kernels, and mitigate sparse-stage representation collapse via deep supervision. On high-resolution electron microscopy segmentation, AFFMAE matches ViT-MAE performance at equal parameter count while reducing FLOPs by up to 7x, halving memory usage, and achieving faster training on a single RTX 5090. Code available at https://github.com/najafian-lab/affmae.