HyPCA-Net: Advancing Multimodal Fusion in Medical Image Analysis
作者: J. Dhar, M. K. Pandey, D. Chakladar, M. Haghighat, A. Alavi, S. Mistry, N. Zaidi
分类: cs.CV
发布日期: 2026-02-18
备注: Accepted at the IEEE/CVF Winter Conference on Applications of Computer Vision 2026
🔗 代码/项目: GITHUB
💡 一句话要点
HyPCA-Net:一种用于医学图像分析的高效多模态融合网络
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 医学图像分析 深度学习 注意力机制 残差学习
📋 核心要点
- 现有医学图像多模态融合方法计算成本高,且级联注意力模块易造成信息损失,限制了其在低资源和多疾病分析中的应用。
- HyPCA-Net 提出混合并行融合级联注意力网络,利用残差自适应学习注意力块和双视角级联注意力块,分别提取模态特定和跨模态的鲁棒特征。
- 在十个公开数据集上的实验表明,HyPCA-Net 显著优于现有方法,性能提升高达 5.2%,计算成本降低高达 73.1%。
📝 摘要(中文)
多模态融合框架通过整合不同的医学成像模态(如MRI、CT),在皮肤癌检测、痴呆症诊断和脑肿瘤预测等应用中展现出巨大潜力。然而,现有的多模态融合方法面临着显著的挑战。首先,它们通常依赖于计算成本高昂的模型,限制了其在低资源环境中的适用性。其次,它们经常采用级联注意力模块,这可能会增加模块间转换过程中信息丢失的风险,并阻碍其有效捕获跨模态的鲁棒共享表示的能力。这限制了它们在多疾病分析任务中的泛化能力。为了解决这些限制,我们提出了一种混合并行融合级联注意力网络(HyPCA-Net),它由两个核心的新颖模块组成:(a)一种计算高效的残差自适应学习注意力块,用于捕获精细的模态特定表示,以及(b)一种双视角级联注意力块,旨在学习跨不同模态的鲁棒共享表示。在十个公开数据集上的大量实验表明,HyPCA-Net 显著优于现有的领先方法,性能提升高达 5.2%,计算成本降低高达 73.1%。
🔬 方法详解
问题定义:论文旨在解决医学图像多模态融合中计算成本高昂和信息损失的问题。现有方法依赖于复杂的模型和级联注意力机制,导致计算资源消耗大,且在模块间传递信息时容易丢失关键特征,限制了其在资源受限环境和多疾病分析任务中的应用。
核心思路:论文的核心思路是设计一种计算高效且能有效捕获模态特定和跨模态鲁棒特征的网络结构。通过并行融合和级联注意力机制的混合使用,以及残差学习和自适应学习策略,在降低计算复杂度的同时,增强特征提取能力,从而提高模型性能和泛化能力。
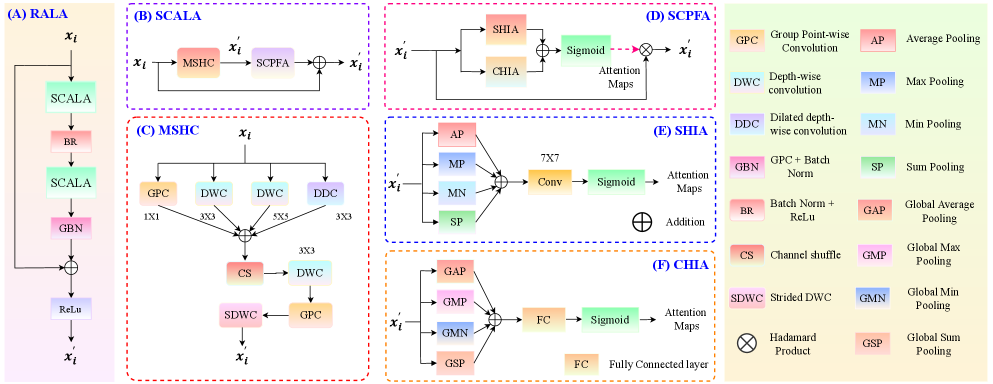
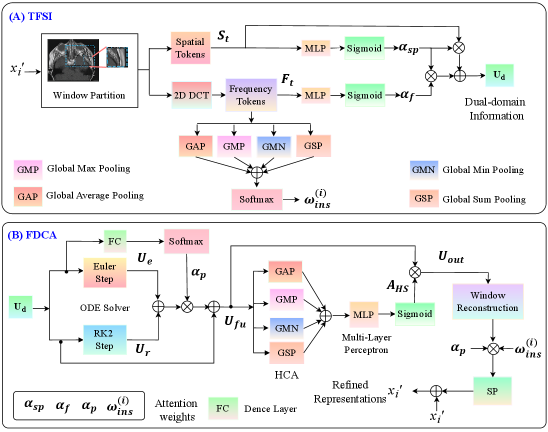
技术框架:HyPCA-Net 的整体架构包含两个核心模块:残差自适应学习注意力块(Residual Adaptive Learning Attention Block)和双视角级联注意力块(Dual-View Cascaded Attention Block)。前者用于提取精细的模态特定表示,后者用于学习跨模态的鲁棒共享表示。这两个模块并行处理不同模态的输入,并通过级联注意力机制进行融合。
关键创新:HyPCA-Net 的关键创新在于其混合并行融合级联注意力机制。传统的级联注意力容易造成信息损失,而该论文提出的方法通过并行处理不同模态的信息,并在后续的级联注意力模块中进行融合,从而减少了信息损失,提高了特征提取的效率和鲁棒性。此外,残差自适应学习注意力块的设计也降低了计算复杂度。
关键设计:残差自适应学习注意力块采用残差连接和自适应学习策略,以提高特征提取的效率和鲁棒性。双视角级联注意力块则通过不同的视角来观察输入数据,从而捕获更全面的跨模态信息。具体的参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
HyPCA-Net 在十个公开数据集上进行了广泛的实验,结果表明其性能显著优于现有的领先方法,性能提升高达 5.2%,计算成本降低高达 73.1%。这些结果表明 HyPCA-Net 在提高医学图像分析的准确性和效率方面具有显著优势。
🎯 应用场景
HyPCA-Net 在医学图像分析领域具有广泛的应用前景,例如皮肤癌检测、痴呆症诊断、脑肿瘤预测以及其他多疾病诊断任务。该研究成果有助于开发更高效、更准确的医学图像分析系统,从而辅助医生进行疾病诊断和治疗方案制定,提高医疗效率和患者生存率。
📄 摘要(原文)
Multimodal fusion frameworks, which integrate diverse medical imaging modalities (e.g., MRI, CT), have shown great potential in applications such as skin cancer detection, dementia diagnosis, and brain tumor prediction. However, existing multimodal fusion methods face significant challenges. First, they often rely on computationally expensive models, limiting their applicability in low-resource environments. Second, they often employ cascaded attention modules, which potentially increase risk of information loss during inter-module transitions and hinder their capacity to effectively capture robust shared representations across modalities. This restricts their generalization in multi-disease analysis tasks. To address these limitations, we propose a Hybrid Parallel-Fusion Cascaded Attention Network (HyPCA-Net), composed of two core novel blocks: (a) a computationally efficient residual adaptive learning attention block for capturing refined modality-specific representations, and (b) a dual-view cascaded attention block aimed at learning robust shared representations across diverse modalities. Extensive experiments on ten publicly available datasets exhibit that HyPCA-Net significantly outperforms existing leading methods, with improvements of up to 5.2% in performance and reductions of up to 73.1% in computational cost. Code: https://github.com/misti1203/HyPCA-Net.