VideoSketcher: Video Models Prior Enable Versatile Sequential Sketch Generation
作者: Hui Ren, Yuval Alaluf, Omer Bar Tal, Alexander Schwing, Antonio Torralba, Yael Vinker
分类: cs.CV
发布日期: 2026-02-17
💡 一句话要点
VideoSketcher:利用预训练视频模型实现多功能序列草图生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列草图生成 视频扩散模型 文本到视频 数据高效学习 笔画排序 视觉蒸馏 生成模型
📋 核心要点
- 现有草图生成模型忽略了草图绘制过程的时序性,将草图视为静态图像,无法模拟人类的创作过程。
- 该论文利用大型语言模型(LLM)进行语义规划和笔画排序,并使用视频扩散模型作为渲染器,生成高质量、时序连贯的草图视频。
- 通过两阶段微调策略,在极少量人工草图数据上,实现了高质量的序列草图生成,并支持笔刷风格控制和自回归生成等扩展。
📝 摘要(中文)
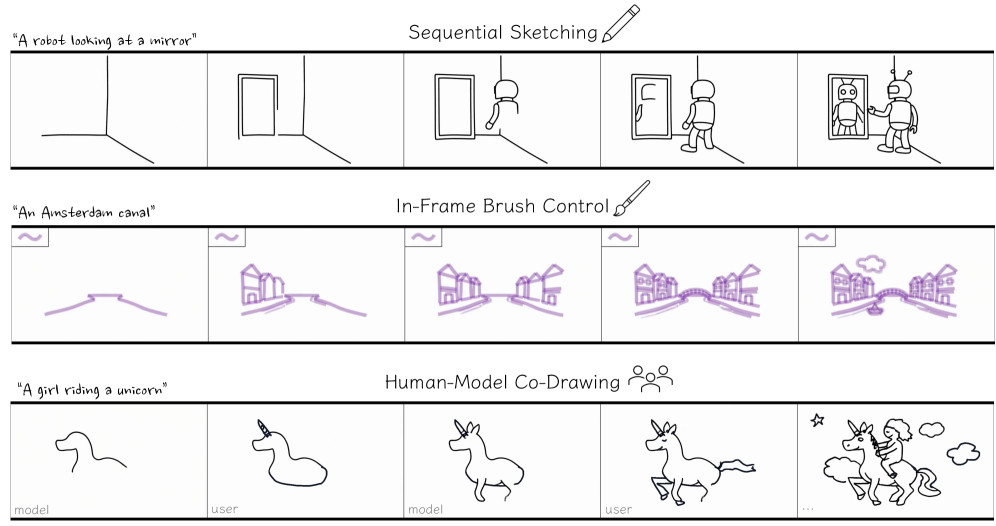
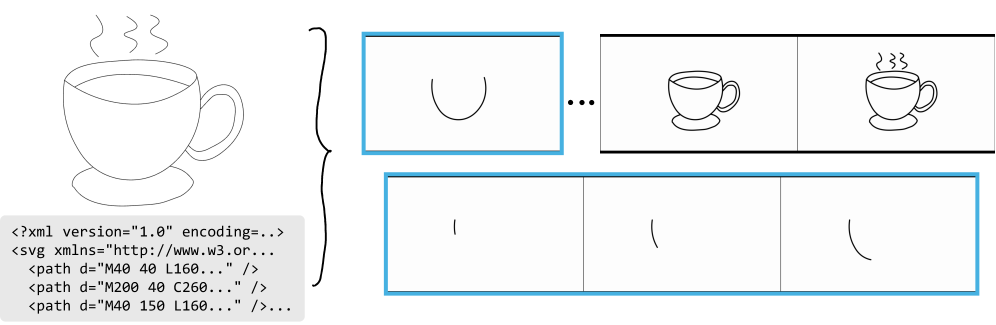
草图绘制本质上是一个序列过程,其中笔画以有意义的顺序绘制,以探索和完善想法。然而,大多数生成模型将草图视为静态图像,忽略了创意绘画的底层时间结构。我们提出了一种数据高效的序列草图生成方法,该方法改编了预训练的文本到视频扩散模型来生成草图绘制过程。我们的关键见解是,大型语言模型和视频扩散模型为此任务提供了互补的优势:LLM提供语义规划和笔画排序,而视频扩散模型作为强大的渲染器,可以生成高质量、时间上连贯的视觉效果。我们通过将草图表示为短视频来利用这一点,在短视频中,笔画在文本指定的排序指令的指导下逐步绘制在空白画布上。我们引入了一种两阶段微调策略,将笔画排序的学习与草图外观的学习分离开来。笔画排序是使用具有受控时间结构的合成形状组合来学习的,而视觉外观是从少至七个手动创作的草图绘制过程中提取的,这些过程捕获了全局绘制顺序和单个笔画的连续形成。尽管人工绘制的草图数据量非常有限,但我们的方法生成了高质量的序列草图,这些草图紧密地遵循文本指定的排序,同时展现出丰富的视觉细节。我们进一步通过笔刷风格条件化和自回归草图生成等扩展展示了我们方法的灵活性,从而实现了额外的可控性和交互式协作绘图。
🔬 方法详解
问题定义:现有草图生成方法主要将草图视为静态图像,忽略了草图绘制的时序性,无法模拟人类创作过程中的探索和完善阶段。这些方法难以控制笔画的顺序,也难以生成具有丰富细节和时间连贯性的草图。
核心思路:论文的核心思路是利用预训练的文本到视频扩散模型,将草图绘制过程建模成一个短视频,其中笔画按照文本指令逐步绘制。通过结合大型语言模型(LLM)的语义规划能力和视频扩散模型的渲染能力,实现高质量的序列草图生成。
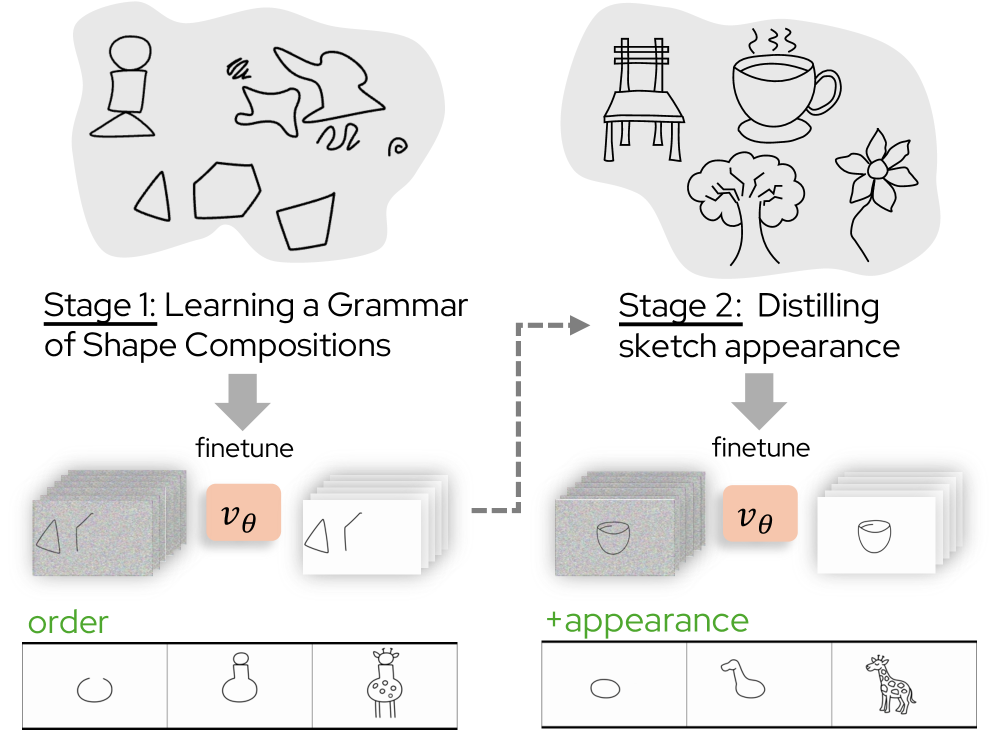
技术框架:该方法采用两阶段微调策略: 1. 笔画排序学习阶段:使用合成形状组合数据,学习笔画的排序规则,利用LLM理解文本指令并生成对应的笔画顺序。 2. 视觉外观蒸馏阶段:使用少量人工绘制的草图数据,从这些数据中提取视觉外观信息,并将其蒸馏到视频扩散模型中,使其能够生成具有丰富细节的草图。
关键创新:该方法最重要的创新点在于: 1. 将草图生成问题转化为视频生成问题,从而可以利用预训练的视频扩散模型。 2. 提出了一种数据高效的微调策略,仅需少量人工草图数据即可实现高质量的草图生成。 3. 结合了LLM和视频扩散模型的优势,实现了语义控制和视觉渲染的解耦。
关键设计: 1. 两阶段微调:先学习笔画顺序,再学习视觉外观,避免了两个任务之间的干扰。 2. 数据增强:使用合成数据增强笔画排序学习阶段的训练数据。 3. 损失函数:使用标准的扩散模型损失函数,并针对草图绘制任务进行了一些调整。 4. 网络结构:使用预训练的文本到视频扩散模型作为基础网络,并根据草图绘制任务的需求进行了一些修改。
🖼️ 关键图片
📊 实验亮点
该方法在极少量人工草图数据(仅7个)的情况下,能够生成高质量的序列草图,并且能够紧密地遵循文本指定的笔画顺序。实验结果表明,该方法生成的草图具有丰富的视觉细节和时间连贯性,并且支持笔刷风格控制和自回归生成等扩展功能。
🎯 应用场景
该研究成果可应用于创意设计、教育、人机交互等领域。例如,可以辅助设计师快速生成草图,帮助学生学习绘画技巧,或者为用户提供交互式的草图绘制体验。未来,该技术有望应用于更广泛的领域,例如虚拟现实、增强现实等。
📄 摘要(原文)
Sketching is inherently a sequential process, in which strokes are drawn in a meaningful order to explore and refine ideas. However, most generative models treat sketches as static images, overlooking the temporal structure that underlies creative drawing. We present a data-efficient approach for sequential sketch generation that adapts pretrained text-to-video diffusion models to generate sketching processes. Our key insight is that large language models and video diffusion models offer complementary strengths for this task: LLMs provide semantic planning and stroke ordering, while video diffusion models serve as strong renderers that produce high-quality, temporally coherent visuals. We leverage this by representing sketches as short videos in which strokes are progressively drawn on a blank canvas, guided by text-specified ordering instructions. We introduce a two-stage fine-tuning strategy that decouples the learning of stroke ordering from the learning of sketch appearance. Stroke ordering is learned using synthetic shape compositions with controlled temporal structure, while visual appearance is distilled from as few as seven manually authored sketching processes that capture both global drawing order and the continuous formation of individual strokes. Despite the extremely limited amount of human-drawn sketch data, our method generates high-quality sequential sketches that closely follow text-specified orderings while exhibiting rich visual detail. We further demonstrate the flexibility of our approach through extensions such as brush style conditioning and autoregressive sketch generation, enabling additional controllability and interactive, collaborative drawing.