Understanding vs. Generation: Navigating Optimization Dilemma in Multimodal Models
作者: Sen Ye, Mengde Xu, Shuyang Gu, Di He, Liwei Wang, Han Hu
分类: cs.CV, cs.AI
发布日期: 2026-02-17
备注: Accepted to ICLR2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出R3框架,解决多模态模型生成与理解能力优化困境
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 生成模型 理解能力 优化困境 Reason-Reflect-Refine 图像描述生成 视频摘要生成
📋 核心要点
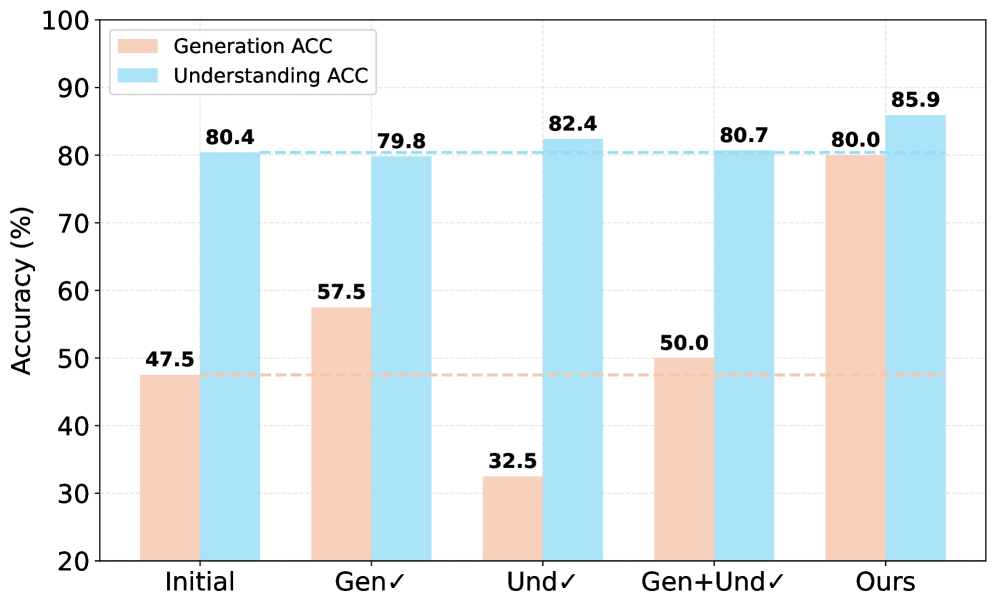
- 现有方法在提升多模态模型的生成能力时,往往会牺牲其理解能力,反之亦然,存在优化困境。
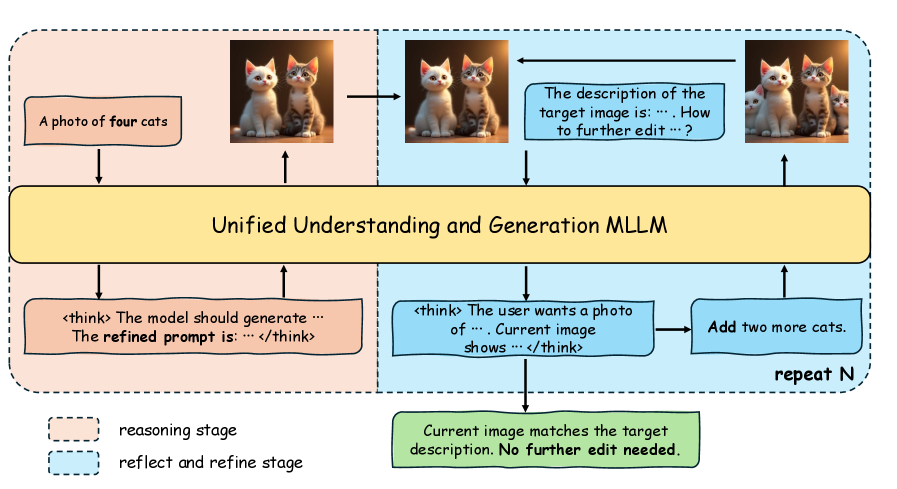
- 论文提出Reason-Reflect-Refine (R3)框架,将单步生成任务分解为生成、理解和再生成的多步过程。
- R3框架通过显式利用模型的理解能力,缓解了生成与理解之间的优化冲突,提升了生成效果和理解能力。
📝 摘要(中文)
当前多模态模型研究面临一个关键挑战:提升生成能力往往以牺牲理解能力为代价,反之亦然。本文分析了这种权衡,并指出其主要原因是生成和理解之间的潜在冲突,这在模型内部产生了一种竞争动态。为了解决这个问题,我们提出了Reason-Reflect-Refine (R3)框架。这种创新算法将单步生成任务重新构建为“生成-理解-再生成”的多步过程。通过在生成过程中显式地利用模型的理解能力,我们成功地缓解了优化困境,实现了更强的生成结果,并提高了与生成过程相关的理解能力。这为设计下一代统一多模态模型提供了有价值的见解。代码已在https://github.com/sen-ye/R3上发布。
🔬 方法详解
问题定义:多模态模型在训练过程中,生成能力和理解能力往往存在此消彼长的现象,即提升生成能力会导致理解能力下降,反之亦然。现有的多模态模型训练方法难以同时优化生成和理解能力,存在优化困境。
核心思路:论文的核心思路是将单步生成任务分解为多步过程,显式地利用模型的理解能力来指导生成过程。通过引入中间的“理解”步骤,缓解生成和理解之间的直接竞争关系,从而实现二者的协同优化。
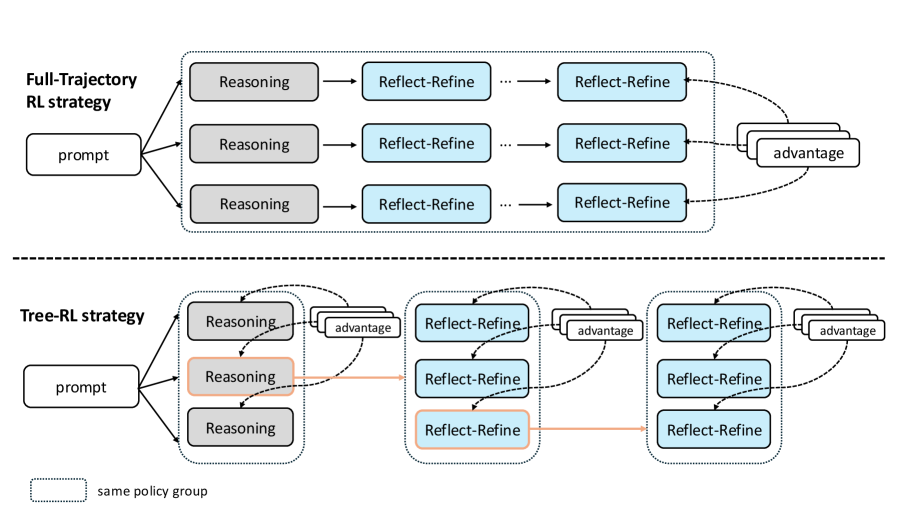
技术框架:R3框架包含三个主要阶段:Reason(推理)、Reflect(反思)和Refine(精炼)。在Reason阶段,模型首先生成初步的结果;在Reflect阶段,模型对生成的结果进行理解和分析,提取关键信息;在Refine阶段,模型利用理解阶段提取的信息,对初步生成的结果进行精炼和改进,得到最终的生成结果。整个过程迭代进行,直到满足停止条件。
关键创新:R3框架的关键创新在于将生成任务分解为多步过程,并在生成过程中显式地引入了理解步骤。这种设计使得模型能够在生成的同时进行理解,从而缓解了生成和理解之间的优化冲突。与现有方法相比,R3框架能够更好地平衡生成和理解能力,实现二者的协同优化。
关键设计:R3框架的具体实现细节包括:如何设计理解模块,如何将理解模块的输出融入到生成模块中,以及如何设计损失函数来指导模型的训练。例如,可以使用注意力机制来提取关键信息,并使用交叉熵损失函数来衡量生成结果的质量。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
论文提出的R3框架在多个多模态任务上取得了显著的性能提升。实验结果表明,R3框架不仅能够提升生成结果的质量,还能够提高模型的理解能力。例如,在图像描述生成任务中,R3框架生成的描述更加准确和丰富,能够更好地表达图像的内容。具体的性能数据和对比基线可以在论文中找到。
🎯 应用场景
R3框架具有广泛的应用前景,可以应用于图像描述生成、视频摘要生成、对话生成等多个领域。该研究的实际价值在于能够提升多模态模型的生成质量和理解能力,从而为人工智能应用提供更强大的支持。未来,R3框架可以进一步扩展到更多的多模态任务中,并与其他技术相结合,例如知识图谱、强化学习等,以实现更智能化的多模态交互。
📄 摘要(原文)
Current research in multimodal models faces a key challenge where enhancing generative capabilities often comes at the expense of understanding, and vice versa. We analyzed this trade-off and identify the primary cause might be the potential conflict between generation and understanding, which creates a competitive dynamic within the model. To address this, we propose the Reason-Reflect-Refine (R3) framework. This innovative algorithm re-frames the single-step generation task into a multi-step process of "generate-understand-regenerate". By explicitly leveraging the model's understanding capability during generation, we successfully mitigate the optimization dilemma, achieved stronger generation results and improved understanding ability which are related to the generation process. This offers valuable insights for designing next-generation unified multimodal models. Code is available at https://github.com/sen-ye/R3.