Learning to Retrieve Navigable Candidates for Efficient Vision-and-Language Navigation
作者: Shutian Gu, Chengkai Huang, Ruoyu Wang, Lina Yao
分类: cs.CV, cs.AI
发布日期: 2026-02-17
💡 一句话要点
提出检索增强框架,提升LLM在视觉-语言导航中的效率与稳定性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 大型语言模型 检索增强学习 模仿学习 机器人导航
📋 核心要点
- 现有VLN方法依赖LLM,但面临效率低、需重复推理和处理噪声候选动作的挑战。
- 提出检索增强框架,通过episode和step两层检索,提供上下文示例并减少动作歧义。
- 实验表明,该方法在R2R基准上显著提升了成功率和导航路径长度,验证了其有效性。
📝 摘要(中文)
视觉-语言导航(VLN)要求智能体根据自然语言指令在未知的环境中导航。最近的方法越来越多地采用大型语言模型(LLM)作为高层导航器,因为它们具有灵活性和推理能力。然而,基于提示的LLM导航常常面临效率低下的问题,因为模型必须重复地从头开始解释指令,并推理嘈杂且冗长的可导航候选对象。本文提出了一种检索增强框架,以提高基于LLM的VLN的效率和稳定性,而无需修改或微调底层语言模型。我们的方法在两个互补的层面上引入了检索。在episode层面,指令级嵌入检索器选择语义上相似的成功导航轨迹作为上下文示例,为指令理解提供特定于任务的先验知识。在step层面,模仿学习的候选检索器在LLM推理之前修剪不相关的可导航方向,从而减少动作歧义和提示复杂性。两个检索模块都是轻量级的、模块化的,并且独立于LLM进行训练。我们在Room-to-Room(R2R)基准上评估了我们的方法。实验结果表明,在已见和未见环境中,成功率、Oracle成功率和SPL都有持续的提高。消融研究进一步表明,指令级示例检索和候选修剪为全局指导和逐步决策效率做出了互补的贡献。这些结果表明,检索增强决策支持是增强基于LLM的视觉-语言导航的有效且可扩展的策略。
🔬 方法详解
问题定义:论文旨在解决基于大型语言模型(LLM)的视觉-语言导航(VLN)任务中,由于LLM需要重复解释指令和处理大量噪声候选动作而导致的效率低下问题。现有方法的痛点在于,每次决策都需要从头开始,缺乏对历史经验的利用,并且容易受到无关选项的干扰。
核心思路:论文的核心思路是通过引入检索机制,为LLM提供更有效的决策支持。具体来说,通过episode级别的检索,找到与当前指令相似的成功导航轨迹作为上下文示例,为LLM提供任务相关的先验知识。同时,在step级别,通过检索过滤掉不相关的候选动作,减少LLM需要考虑的选项数量,从而提高决策效率和准确性。
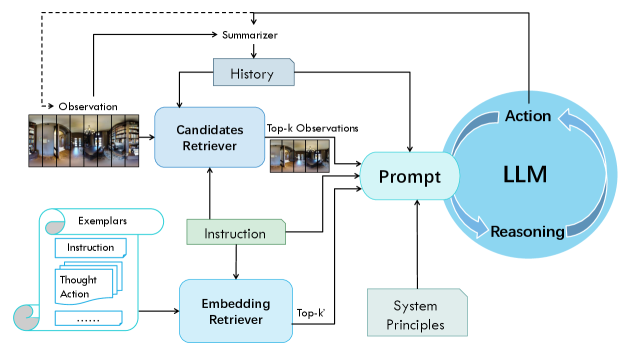
技术框架:整体框架包含两个主要的检索模块:指令级嵌入检索器和模仿学习的候选检索器。指令级嵌入检索器负责在episode级别检索相似的导航轨迹,这些轨迹被用作LLM的上下文示例。模仿学习的候选检索器则在step级别工作,通过学习模仿专家策略,预测哪些候选动作是相关的,从而过滤掉不相关的选项。LLM接收经过检索增强的输入,进行导航决策。
关键创新:最重要的技术创新点在于将检索机制引入到LLM-based VLN中,并且在episode和step两个层面进行检索,从而更全面地提升了LLM的导航能力。与现有方法相比,该方法不需要修改或微调LLM,而是通过外部的检索模块来增强LLM的决策能力,具有更好的模块化和可扩展性。
关键设计:指令级嵌入检索器使用预训练的句子嵌入模型(例如Sentence-BERT)来计算指令之间的相似度,并选择最相似的轨迹作为上下文示例。模仿学习的候选检索器通过训练一个分类器来预测每个候选动作是否是专家策略会选择的动作。损失函数通常采用交叉熵损失。具体的网络结构和参数设置取决于具体的实现,但通常会采用轻量级的网络结构以保证效率。
🖼️ 关键图片

📊 实验亮点
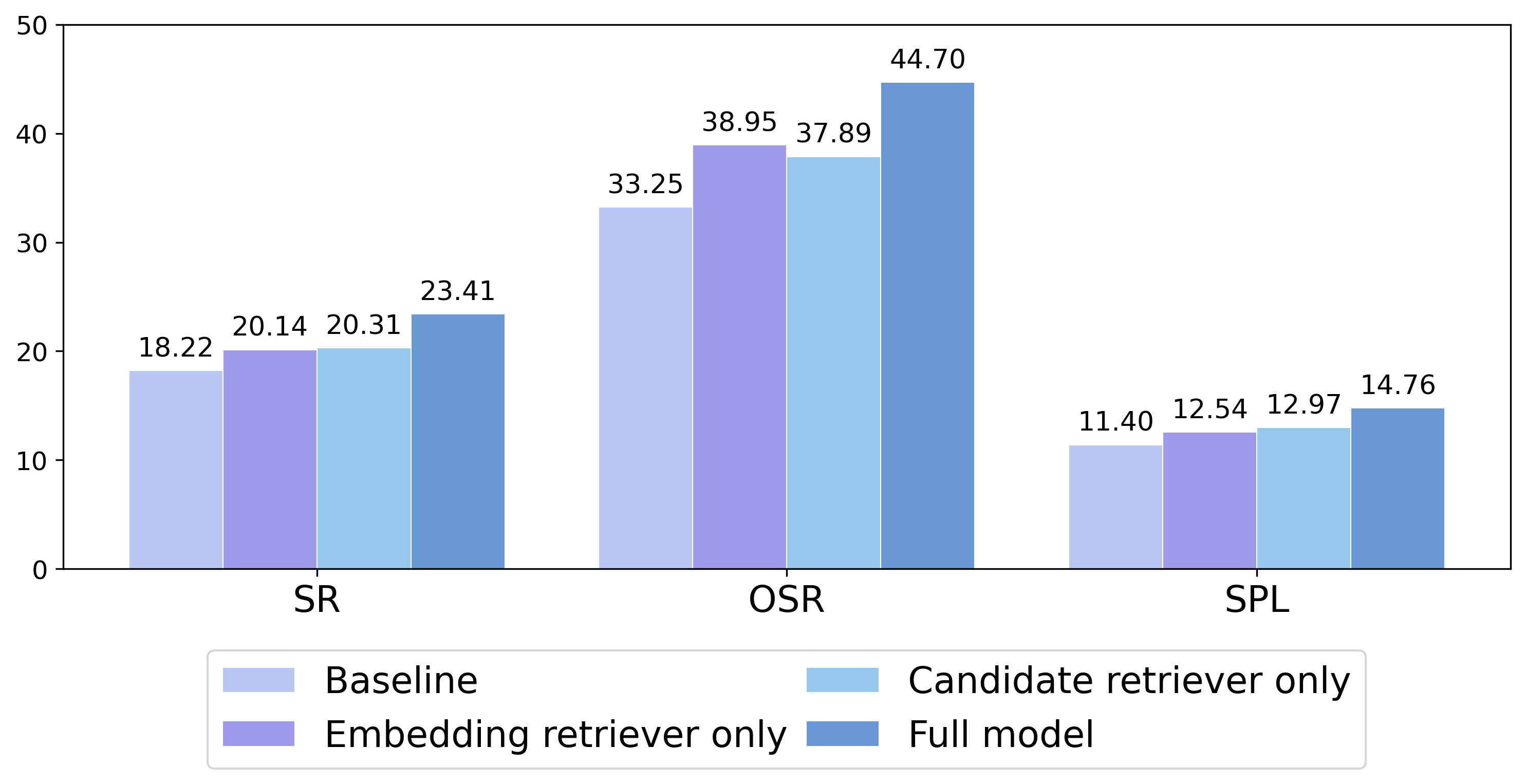
实验结果表明,该方法在R2R基准上取得了显著的性能提升。在未见环境中,成功率(SR)提高了约3-5%,Oracle成功率(OSR)提高了约2-4%,SPL(Success Rate weighted by Path Length)提高了约3-6%。消融实验表明,指令级示例检索和候选修剪都对性能提升有贡献,并且两者之间具有互补性。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、虚拟现实等领域。例如,可以帮助服务型机器人在复杂环境中根据用户指令进行导航,或者在虚拟现实游戏中为玩家提供更智能的导航辅助。该方法通过检索增强LLM的决策能力,有望提升人机交互的自然性和效率,具有广阔的应用前景。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) requires an agent to follow natural-language instructions and navigate through previously unseen environments. Recent approaches increasingly employ large language models (LLMs) as high-level navigators due to their flexibility and reasoning capability. However, prompt-based LLM navigation often suffers from inefficient decision-making, as the model must repeatedly interpret instructions from scratch and reason over noisy and verbose navigable candidates at each step. In this paper, we propose a retrieval-augmented framework to improve the efficiency and stability of LLM-based VLN without modifying or fine-tuning the underlying language model. Our approach introduces retrieval at two complementary levels. At the episode level, an instruction-level embedding retriever selects semantically similar successful navigation trajectories as in-context exemplars, providing task-specific priors for instruction grounding. At the step level, an imitation-learned candidate retriever prunes irrelevant navigable directions before LLM inference, reducing action ambiguity and prompt complexity. Both retrieval modules are lightweight, modular, and trained independently of the LLM. We evaluate our method on the Room-to-Room (R2R) benchmark. Experimental results demonstrate consistent improvements in Success Rate, Oracle Success Rate, and SPL on both seen and unseen environments. Ablation studies further show that instruction-level exemplar retrieval and candidate pruning contribute complementary benefits to global guidance and step-wise decision efficiency. These results indicate that retrieval-augmented decision support is an effective and scalable strategy for enhancing LLM-based vision-and-language navigation.