Concept-Enhanced Multimodal RAG: Towards Interpretable and Accurate Radiology Report Generation
作者: Marco Salmè, Federico Siciliano, Fabrizio Silvestri, Paolo Soda, Rosa Sicilia, Valerio Guarrasi
分类: cs.CV
发布日期: 2026-02-17
💡 一句话要点
提出概念增强多模态RAG框架CEMRAG,提升放射报告生成的可解释性和准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 放射报告生成 多模态RAG 视觉概念 可解释性 医学影像 临床准确性 视觉语言模型
📋 核心要点
- 现有RRG方法缺乏可解释性,且容易产生与影像证据不符的幻觉,限制了其临床应用。
- CEMRAG将视觉表征分解为可解释的临床概念,并与多模态RAG集成,从而提高可解释性和准确性。
- 实验结果表明,CEMRAG在临床准确性和标准NLP指标上均优于传统方法,挑战了可解释性和性能之间的权衡。
📝 摘要(中文)
本文提出了一种概念增强多模态RAG (CEMRAG) 框架,用于放射报告生成 (RRG)。该框架旨在通过将视觉表征分解为可解释的临床概念,并将其与多模态RAG集成,从而提高RRG的可解释性和事实准确性。CEMRAG利用丰富的上下文提示来生成放射报告。在MIMIC-CXR和IU X-Ray数据集上的实验结果表明,CEMRAG在多种VLM架构、训练方式和检索配置下,均优于传统的RAG和仅基于概念的方法,在临床准确性指标和标准NLP指标上均有提升。该研究表明,透明的视觉概念可以增强而非损害医学VLM的诊断准确性。CEMRAG的模块化设计将可解释性分解为视觉透明度和结构化语言模型调节,为实现临床上可信赖的AI辅助放射学提供了一条有原则的途径。
🔬 方法详解
问题定义:放射报告生成(RRG)旨在利用视觉语言模型(VLM)自动生成放射报告,以减轻医生的文档负担并提高报告的一致性。然而,现有方法缺乏可解释性,并且容易产生与影像证据不符的错误信息(即幻觉),这严重阻碍了它们在临床实践中的应用。现有研究通常将可解释性和准确性作为独立的目标来处理,缺乏统一的解决方案。
核心思路:CEMRAG的核心思路是将视觉表征分解为可解释的临床概念,并将这些概念融入到多模态RAG框架中。通过显式地提取和利用临床概念,模型可以更好地理解图像内容,并生成更准确、更可信的报告。这种设计旨在弥合可解释性和准确性之间的差距,使模型既能提供透明的推理过程,又能保证报告的质量。
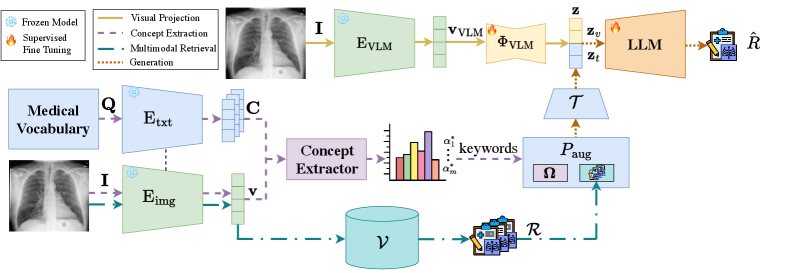
技术框架:CEMRAG框架主要包含以下几个模块:1) 视觉概念提取模块:用于从放射图像中提取临床相关的概念。2) 多模态RAG模块:利用检索增强生成技术,从外部知识库中检索相关信息,并将其与视觉概念融合。3) 报告生成模块:基于融合后的信息,生成最终的放射报告。整体流程是:首先,视觉概念提取模块从输入图像中提取概念;然后,多模态RAG模块利用这些概念检索相关信息;最后,报告生成模块将检索到的信息和视觉概念结合起来,生成报告。
关键创新:CEMRAG的关键创新在于将可解释的视觉概念与多模态RAG相结合,形成一个统一的框架。与传统的RAG方法相比,CEMRAG利用视觉概念作为桥梁,将视觉信息和语言信息更好地连接起来,从而提高了报告的准确性和可解释性。与仅基于概念的方法相比,CEMRAG通过RAG机制引入了外部知识,进一步增强了模型的知识储备和推理能力。
关键设计:CEMRAG的关键设计包括:1) 使用预训练的视觉概念检测器来提取临床概念;2) 设计了一种新的上下文提示策略,将视觉概念融入到RAG的提示中;3) 采用了一种多模态融合机制,将视觉信息和检索到的信息有效地结合起来。具体的参数设置、损失函数和网络结构等细节在论文中没有详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
在MIMIC-CXR和IU X-Ray数据集上的实验结果表明,CEMRAG在临床准确性指标和标准NLP指标上均优于传统的RAG和仅基于概念的方法。具体的性能提升数据在摘要中没有给出,属于未知信息。该研究挑战了可解释性和性能之间的权衡,证明了透明的视觉概念可以增强而非损害医学VLM的诊断准确性。
🎯 应用场景
CEMRAG框架具有广泛的应用前景,可用于辅助放射科医生进行报告生成,提高诊断效率和准确性。该框架还可以应用于医学教育领域,帮助学生理解放射图像和报告之间的关系。此外,CEMRAG的设计思路也可以推广到其他医学影像分析任务中,例如疾病诊断和治疗方案制定。
📄 摘要(原文)
Radiology Report Generation (RRG) through Vision-Language Models (VLMs) promises to reduce documentation burden, improve reporting consistency, and accelerate clinical workflows. However, their clinical adoption remains limited by the lack of interpretability and the tendency to hallucinate findings misaligned with imaging evidence. Existing research typically treats interpretability and accuracy as separate objectives, with concept-based explainability techniques focusing primarily on transparency, while Retrieval-Augmented Generation (RAG) methods targeting factual grounding through external retrieval. We present Concept-Enhanced Multimodal RAG (CEMRAG), a unified framework that decomposes visual representations into interpretable clinical concepts and integrates them with multimodal RAG. This approach exploits enriched contextual prompts for RRG, improving both interpretability and factual accuracy. Experiments on MIMIC-CXR and IU X-Ray across multiple VLM architectures, training regimes, and retrieval configurations demonstrate consistent improvements over both conventional RAG and concept-only baselines on clinical accuracy metrics and standard NLP measures. These results challenge the assumed trade-off between interpretability and performance, showing that transparent visual concepts can enhance rather than compromise diagnostic accuracy in medical VLMs. Our modular design decomposes interpretability into visual transparency and structured language model conditioning, providing a principled pathway toward clinically trustworthy AI-assisted radiology.