Revealing and Enhancing Core Visual Regions: Harnessing Internal Attention Dynamics for Hallucination Mitigation in LVLMs
作者: Guangtao Lyu, Qi Liu, Chenghao Xu, Jiexi Yan, Muli Yang, Xueting Li, Fen Fang, Cheng Deng
分类: cs.CV
发布日期: 2026-02-17
💡 一句话要点
提出PADE:利用内部注意力动态增强视觉核心区域,缓解LVLM幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 多模态推理 幻觉缓解 注意力机制 正向注意力动态
📋 核心要点
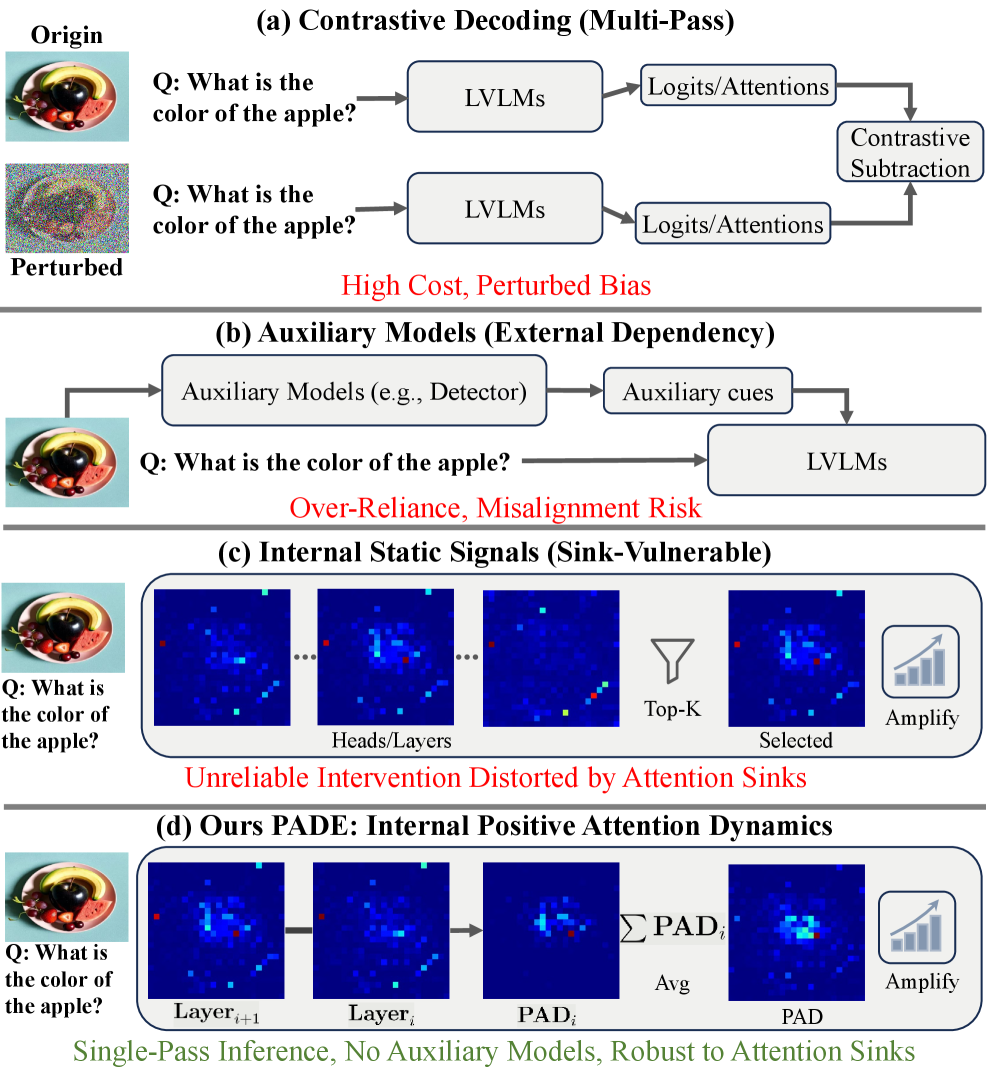
- LVLM易受注意力沉没影响,导致幻觉,现有免训练方法计算开销大且可能引入干扰。
- PADE利用正向注意力动态(PAD)揭示语义核心视觉区域,并进行自适应增强。
- 实验表明,PADE能有效提高视觉基础,减少幻觉,提升多模态推理的可靠性。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在多模态推理方面表现出色,但仍易产生幻觉,即输出与视觉输入或用户指令不一致。现有的免训练方法,如对比解码和辅助专家模型,计算开销大,可能引入干扰,且静态内部信号增强易受注意力沉没现象影响。本文发现LVLM中的正向注意力动态(PAD)在注意力沉没干扰下,能自然揭示语义核心视觉区域。基于此,提出正向注意力动态增强(PADE),一种免训练的注意力干预方法,构建PAD图以识别语义核心视觉区域,应用逐头中值绝对偏差缩放自适应控制干预强度,并利用系统令牌补偿保持对复杂用户指令的关注和长期输出一致性。在多个LVLM和基准测试上的实验表明,PADE提高了视觉基础并减少了幻觉,验证了利用内部注意力动态进行可靠多模态推理的有效性。
🔬 方法详解
问题定义:LVLM在多模态推理中存在幻觉问题,即生成与视觉输入不一致的内容。现有免训练方法,如对比解码和辅助专家模型,计算成本高昂,且可能引入额外的噪声或偏差。静态内部信号增强方法容易受到注意力沉没现象的影响,导致模型无法关注到关键的视觉区域。
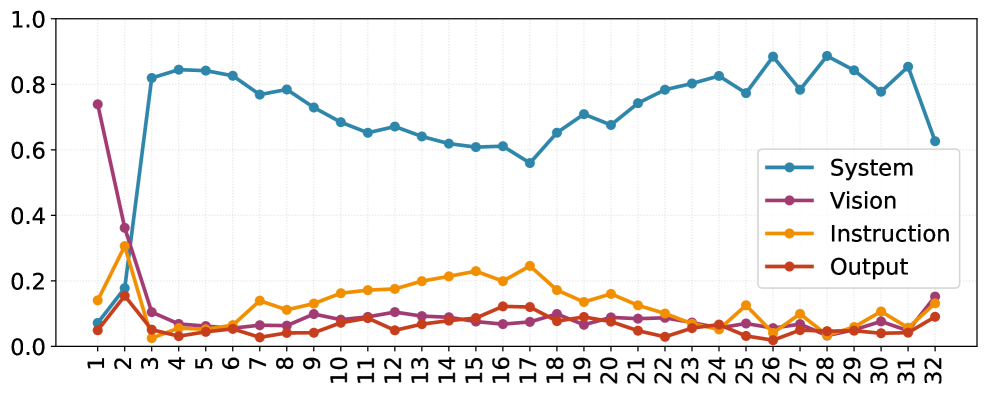
核心思路:论文的核心思路是利用LVLM内部的注意力动态来识别并增强视觉输入中语义上最重要的区域。作者观察到,即使在注意力沉没的干扰下,正向注意力动态(PAD)仍然能够揭示图像中的核心区域。通过增强这些区域的注意力,可以引导模型更好地理解视觉内容,从而减少幻觉的产生。
技术框架:PADE (Positive Attention Dynamics Enhancement) 包含三个主要步骤:1) 构建PAD图:通过分析LVLM内部的注意力权重,计算每个视觉区域的PAD值,从而得到PAD图,用于指示图像中的核心区域。2) 自适应干预强度控制:使用逐头中值绝对偏差缩放(per-head Median Absolute Deviation Scaling)来动态调整注意力干预的强度,使得干预能够适应不同的输入和模型状态。3) 系统令牌补偿:为了保持模型对复杂用户指令的关注,并支持长期输出的一致性,引入系统令牌补偿机制,确保模型不会忽略指令信息。
关键创新:PADE的关键创新在于利用了LVLM内部的注意力动态来指导注意力干预。与传统的静态注意力增强方法不同,PADE能够自适应地识别并增强图像中的核心区域,从而更有效地减少幻觉。此外,PADE是一种免训练的方法,不需要额外的训练数据或计算资源。
关键设计:PAD图的计算方式基于注意力权重矩阵,具体公式未知(论文未明确给出)。逐头中值绝对偏差缩放的具体实现细节未知(论文未明确给出)。系统令牌补偿的具体实现细节未知(论文未明确给出)。这些细节可能在补充材料或后续工作中给出。
🖼️ 关键图片

📊 实验亮点
PADE在多个LVLM和基准测试上进行了验证,实验结果表明,PADE能够有效提高视觉基础,减少幻觉。具体的性能数据和提升幅度在摘要中没有明确给出,需要在论文正文中查找。该方法是一种免训练的注意力干预方法,具有较高的实用价值。
🎯 应用场景
该研究成果可应用于各种需要可靠多模态推理的场景,例如智能客服、自动驾驶、医疗诊断等。通过减少LVLM的幻觉,可以提高这些应用的可信度和安全性,从而更好地服务于人类社会。未来,该方法可以进一步扩展到其他多模态任务和模型中。
📄 摘要(原文)
LVLMs have achieved strong multimodal reasoning capabilities but remain prone to hallucinations, producing outputs inconsistent with visual inputs or user instructions. Existing training-free methods, including contrastive decoding and auxiliary expert models, which incur several times more computational overhead and may introduce potential interference, as well as static internal signal enhancement, are often vulnerable to the attention sink phenomenon. We find that internal Positive Attention Dynamics (PAD) in LVLMs naturally reveal semantically core visual regions under the distortions of attention sinks. Based on this, we propose Positive Attention Dynamics Enhancement (PADE), a training-free attention intervention that constructs a PAD map to identify semantically core visual regions, applies per-head Median Absolute Deviation Scaling to adaptively control the intervention strength, and leverages System-Token Compensation to maintain attention to complex user instructions and support long-term output consistency. Experiments on multiple LVLMs and benchmarks show that PADE improves visual grounding and reduces hallucinations, validating the effectiveness of leveraging internal attention dynamics for reliable multimodal reasoning.