Semantic-Guided 3D Gaussian Splatting for Transient Object Removal
作者: Aditi Prabakaran, Priyesh Shukla
分类: cs.CV
发布日期: 2026-02-17
💡 一句话要点
提出语义引导的3D高斯溅射方法,用于移除多视角重建中的瞬态物体
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 瞬态物体移除 语义引导 视觉-语言模型 多视角重建
📋 核心要点
- 传统方法在多视角重建中难以有效去除瞬态物体,导致重建结果出现伪影,且现有方法存在内存开销大或易受视差影响的问题。
- 本文提出一种基于语义引导的3D高斯溅射方法,利用视觉-语言模型识别并移除场景中的瞬态物体,从而提高重建质量。
- 实验结果表明,该方法在RobustNeRF基准测试上优于原始3DGS,能够在保持实时渲染性能的同时,有效去除瞬态物体并提升重建质量。
📝 摘要(中文)
在多视角重建中,瞬态物体会导致3D高斯溅射(3DGS)重建中出现重影伪影。现有的解决方案依赖于高内存消耗的场景分解或易受视差歧义影响的基于运动的启发式方法。本文提出了一种语义过滤框架,用于使用视觉-语言模型进行类别感知的瞬态物体移除。在训练迭代过程中,计算渲染视图和干扰文本提示之间的CLIP相似性得分,并将其累积到每个高斯分布上。超过校准阈值的高斯分布会进行不透明度正则化和定期剪枝。与基于运动的方法不同,语义分类通过独立于运动模式识别物体类别来解决视差歧义。在RobustNeRF基准测试上的实验表明,在四个序列中,重建质量相对于原始3DGS得到了持续改进,同时保持了最小的内存开销和实时渲染性能。阈值校准和与基线的比较验证了语义引导是具有可预测干扰类别场景中瞬态移除的实用策略。
🔬 方法详解
问题定义:多视角重建中,场景中存在的瞬态物体(例如行人、车辆等)会导致重建结果出现重影伪影,降低重建质量。现有的方法,如基于运动的方法,容易受到视差歧义的影响,而基于场景分解的方法则需要大量的内存开销。因此,如何在保证内存效率和实时性的前提下,有效去除瞬态物体是本文要解决的问题。
核心思路:本文的核心思路是利用视觉-语言模型的语义理解能力,区分场景中的静态物体和瞬态物体。通过计算渲染视图和干扰文本提示之间的CLIP相似性得分,可以判断高斯分布对应的是否为瞬态物体。这种方法不依赖于运动信息,因此可以有效解决视差歧义问题。
技术框架:该方法主要包含以下几个阶段:1) 使用3D高斯溅射(3DGS)初始化场景;2) 在训练迭代过程中,渲染当前视角下的图像;3) 使用CLIP模型计算渲染图像与干扰文本提示(例如“person”、“car”)之间的相似性得分;4) 将相似性得分累积到每个高斯分布上;5) 对超过校准阈值的高斯分布进行不透明度正则化,使其逐渐透明;6) 定期剪枝不透明度较低的高斯分布。
关键创新:本文最重要的技术创新点在于利用视觉-语言模型的语义信息来指导瞬态物体的移除。与传统的基于运动的方法相比,该方法能够有效解决视差歧义问题,并且不需要进行复杂的场景分解,从而降低了内存开销。
关键设计:关键设计包括:1) 使用CLIP模型提取图像和文本的特征,并计算相似性得分;2) 设计了一种不透明度正则化策略,使得与瞬态物体对应的高斯分布逐渐透明;3) 引入了一个校准阈值,用于判断高斯分布是否对应于瞬态物体。阈值的选择会影响最终的重建效果,需要根据具体场景进行调整。
🖼️ 关键图片
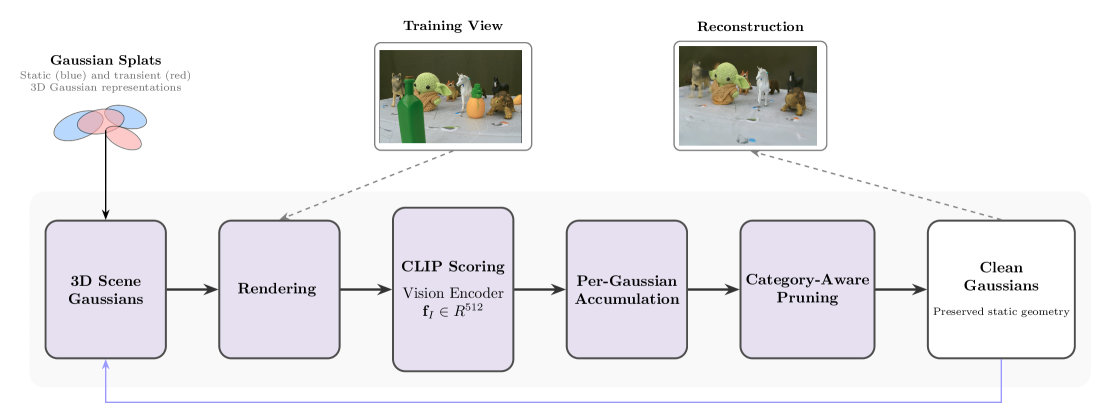

📊 实验亮点
实验结果表明,该方法在RobustNeRF基准测试上,相对于原始3DGS,重建质量得到了显著提升。具体而言,在四个序列上,该方法都取得了更好的PSNR、SSIM和LPIPS指标。同时,该方法保持了最小的内存开销和实时渲染性能,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。例如,在自动驾驶中,可以利用该方法去除道路上的行人、车辆等瞬态物体,从而提高环境感知的准确性。在机器人导航中,可以用于构建更干净、更稳定的三维地图。在增强现实中,可以用于创建更逼真的虚拟场景。
📄 摘要(原文)
Transient objects in casual multi-view captures cause ghosting artifacts in 3D Gaussian Splatting (3DGS) reconstruction. Existing solutions relied on scene decomposition at significant memory cost or on motion-based heuristics that were vulnerable to parallax ambiguity. A semantic filtering framework was proposed for category-aware transient removal using vision-language models. CLIP similarity scores between rendered views and distractor text prompts were accumulated per-Gaussian across training iterations. Gaussians exceeding a calibrated threshold underwent opacity regularization and periodic pruning. Unlike motion-based approaches, semantic classification resolved parallax ambiguity by identifying object categories independently of motion patterns. Experiments on the RobustNeRF benchmark demonstrated consistent improvement in reconstruction quality over vanilla 3DGS across four sequences, while maintaining minimal memory overhead and real-time rendering performance. Threshold calibration and comparisons with baselines validated semantic guidance as a practical strategy for transient removal in scenarios with predictable distractor categories.