Emergent Morphing Attack Detection in Open Multi-modal Large Language Models
作者: Marija Ivanovska, Vitomir Štruc
分类: cs.CV
发布日期: 2026-02-17
备注: This manuscript is currently under review at Pattern Recognition Letters
💡 一句话要点
利用开放多模态大语言模型实现人脸融合攻击的零样本检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人脸融合攻击检测 多模态大语言模型 零样本学习 生物特征识别 数字取证
📋 核心要点
- 现有的人脸融合攻击检测方法依赖于特定任务的训练数据,泛化能力不足,难以应对新型攻击。
- 本文探索了开源多模态大语言模型(MLLM)在零样本人脸融合攻击检测中的潜力,无需额外训练即可实现有效检测。
- 实验结果表明,MLLM在零样本条件下即可超越特定任务的基线方法,并在EER指标上取得显著提升。
📝 摘要(中文)
人脸融合攻击对生物特征验证构成威胁,但大多数融合攻击检测(MAD)系统需要针对特定任务进行训练,并且对未见过的攻击类型泛化能力较差。与此同时,开源多模态大语言模型(MLLM)已经展示出强大的视觉-语言推理能力,但它们在生物特征取证方面的潜力仍未被充分探索。本文首次对开源MLLM在单图像MAD中的零样本性能进行了系统评估,使用了公开可用的权重和一个标准化的、可复现的协议。在各种融合技术中,许多MLLM在没有任何微调或领域自适应的情况下都表现出显著的判别能力,其中LLaVA1.6-Mistral-7B达到了最先进的性能,在等错误率(EER)方面至少超过了极具竞争力的特定任务MAD基线23%。结果表明,多模态预训练可以隐式地编码指示融合伪影的细粒度面部不一致性,从而实现零样本取证敏感性。我们的发现将开源MLLM定位为生物特征安全和取证图像分析的可复现、可解释和有竞争力的基础。这种涌现的能力也突出了通过有针对性的微调或轻量级自适应来开发最先进的MAD系统的新机会,从而进一步提高准确性和效率,同时保持可解释性。为了支持未来的研究,所有代码和评估协议将在发表后发布。
🔬 方法详解
问题定义:人脸融合攻击通过将多个人脸图像融合,生成一张可以同时通过多个人身份验证的人脸图像,对生物特征识别系统构成严重威胁。现有的融合攻击检测方法通常需要大量特定于攻击类型的训练数据,导致模型泛化能力差,难以检测未知的攻击方式。
核心思路:本文的核心思路是利用多模态大语言模型(MLLM)在视觉和语言理解方面的强大能力,通过分析单张人脸图像中的细微不一致性来判断是否存在融合攻击。MLLM在大量数据上的预训练使其能够学习到人脸图像的内在结构和潜在的伪影,从而实现零样本检测。
技术框架:本文采用的框架是直接利用预训练好的开源MLLM,例如LLaVA1.6-Mistral-7B,进行零样本推理。具体流程是:输入单张人脸图像到MLLM,通过提示工程(Prompt Engineering)引导模型分析图像并判断是否存在融合攻击。模型输出一个置信度分数,用于判断图像是否为融合图像。
关键创新:本文最重要的创新点在于首次探索了开源MLLM在零样本人脸融合攻击检测中的应用。与传统方法需要特定任务训练不同,本文的方法无需任何微调或领域自适应,即可实现有效的检测,展示了MLLM的涌现能力。
关键设计:本文的关键设计在于提示工程。通过精心设计的提示语,例如“Is this image a real face or a morphed face? Explain your reasoning.”,引导MLLM关注人脸图像中的细微不一致性,并给出判断依据。此外,本文还采用了标准化的评估协议,确保实验结果的可复现性。
🖼️ 关键图片

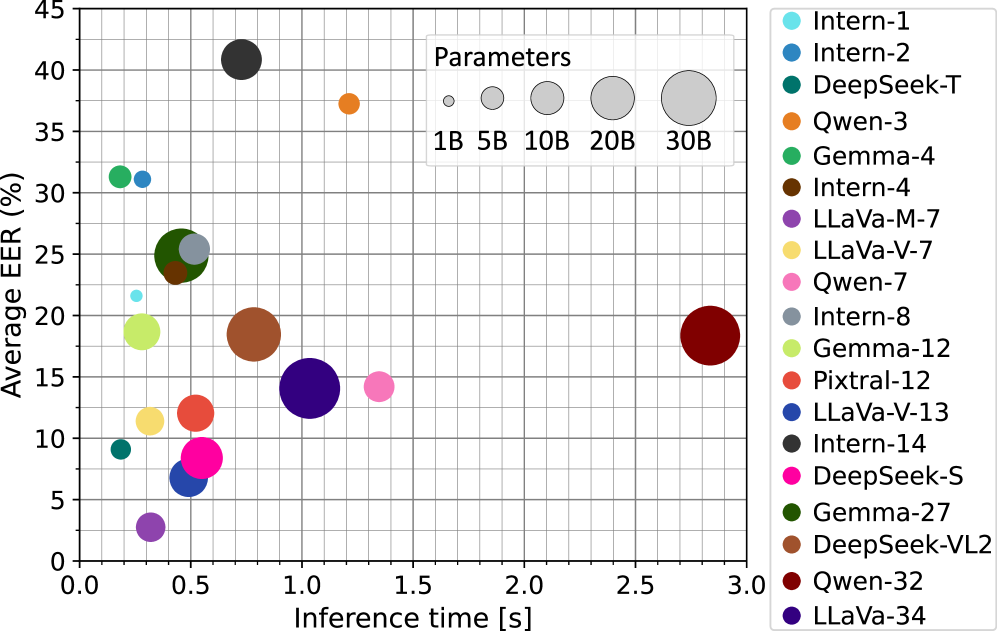
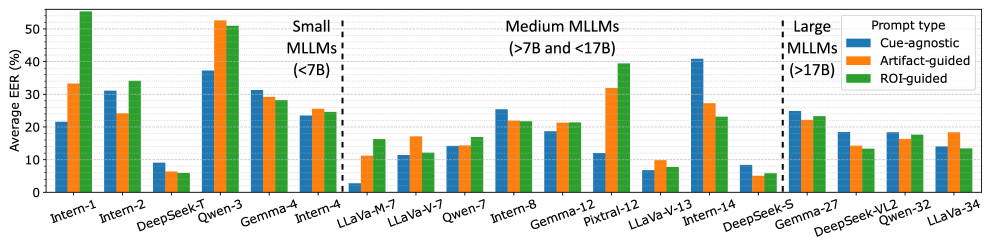
📊 实验亮点
实验结果表明,LLaVA1.6-Mistral-7B在零样本条件下,在人脸融合攻击检测任务上取得了最先进的性能,其等错误率(EER)至少超过了极具竞争力的特定任务MAD基线23%。这表明多模态预训练可以有效地编码指示融合伪影的细粒度面部不一致性,从而实现零样本取证敏感性。
🎯 应用场景
该研究成果可应用于生物特征识别系统,例如人脸解锁、身份验证等,以提高系统的安全性,防止人脸融合攻击。此外,该方法还可用于数字取证领域,帮助鉴定图像的真实性,防止恶意篡改和伪造。未来,该技术有望应用于更广泛的安全领域,例如视频监控、网络安全等。
📄 摘要(原文)
Face morphing attacks threaten biometric verification, yet most morphing attack detection (MAD) systems require task-specific training and generalize poorly to unseen attack types. Meanwhile, open-source multimodal large language models (MLLMs) have demonstrated strong visual-linguistic reasoning, but their potential in biometric forensics remains underexplored. In this paper, we present the first systematic zero-shot evaluation of open-source MLLMs for single-image MAD, using publicly available weights and a standardized, reproducible protocol. Across diverse morphing techniques, many MLLMs show non-trivial discriminative ability without any fine-tuning or domain adaptation, and LLaVA1.6-Mistral-7B achieves state-of-the-art performance, surpassing highly competitive task-specific MAD baselines by at least 23% in terms of equal error rate (EER). The results indicate that multimodal pretraining can implicitly encode fine-grained facial inconsistencies indicative of morphing artifacts, enabling zero-shot forensic sensitivity. Our findings position open-source MLLMs as reproducible, interpretable, and competitive foundations for biometric security and forensic image analysis. This emergent capability also highlights new opportunities to develop state-of-the-art MAD systems through targeted fine-tuning or lightweight adaptation, further improving accuracy and efficiency while preserving interpretability. To support future research, all code and evaluation protocols will be released upon publication.