Automatic Funny Scene Extraction from Long-form Cinematic Videos
作者: Sibendu Paul, Haotian Jiang, Caren Chen
分类: cs.IR, cs.CV
发布日期: 2026-02-17
期刊: Association for the Advancement of Artificial Intelligence 2026
💡 一句话要点
提出一种自动提取长视频电影中幽默场景的端到端系统,提升用户互动。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 幽默场景提取 长视频理解 多模态融合 场景分割 镜头检测
📋 核心要点
- 长视频电影的幽默场景提取面临场景定位困难和幽默理解复杂等挑战。
- 结合视觉和文本信息进行场景分割,利用多模态信息进行幽默识别,提升准确性。
- 实验表明,该系统能有效提取幽默片段,并在场景检测和幽默识别上取得显著提升。
📝 摘要(中文)
本文提出了一种端到端系统,用于从长视频电影中自动识别和排序幽默场景,这对于创建引人入胜的视频预览和短视频内容至关重要,能够提升流媒体平台的用户参与度。长视频电影时长较长且叙事复杂,给场景定位带来挑战,而幽默依赖于多种模态及其细微风格,进一步增加了复杂性。该系统包括镜头检测、多模态场景定位和针对电影内容优化的幽默标签。主要创新包括:一种结合视觉和文本线索的新型场景分割方法,通过引导式三元组挖掘改进的镜头表示,以及一个利用音频和文本的多模态幽默标签框架。在OVSD数据集上,该系统在场景检测方面比最先进的方法提高了18.3%的AP,在长文本幽默检测方面达到了0.834的F1分数。在五个电影标题上的广泛评估表明,该流程提取的片段中有87%旨在表达幽默,并且98%的场景被准确定位。成功推广到预告片后,这些结果展示了该流程在增强内容创作工作流程、改善用户参与度以及简化各种电影媒体格式的短视频内容生成方面的潜力。
🔬 方法详解
问题定义:论文旨在解决从长视频电影中自动提取幽默场景的问题。现有方法在处理长视频时,场景定位不够准确,且难以有效利用多模态信息来识别幽默,导致提取的幽默场景质量不高。现有方法难以有效结合视觉、文本和音频信息,对电影中的幽默进行准确识别和定位。
核心思路:论文的核心思路是利用多模态信息融合,包括视觉、文本和音频,来更准确地定位和识别幽默场景。通过结合视觉和文本线索进行场景分割,可以更精确地划分场景。利用音频和文本信息进行幽默标签,可以更全面地理解幽默的表达方式。
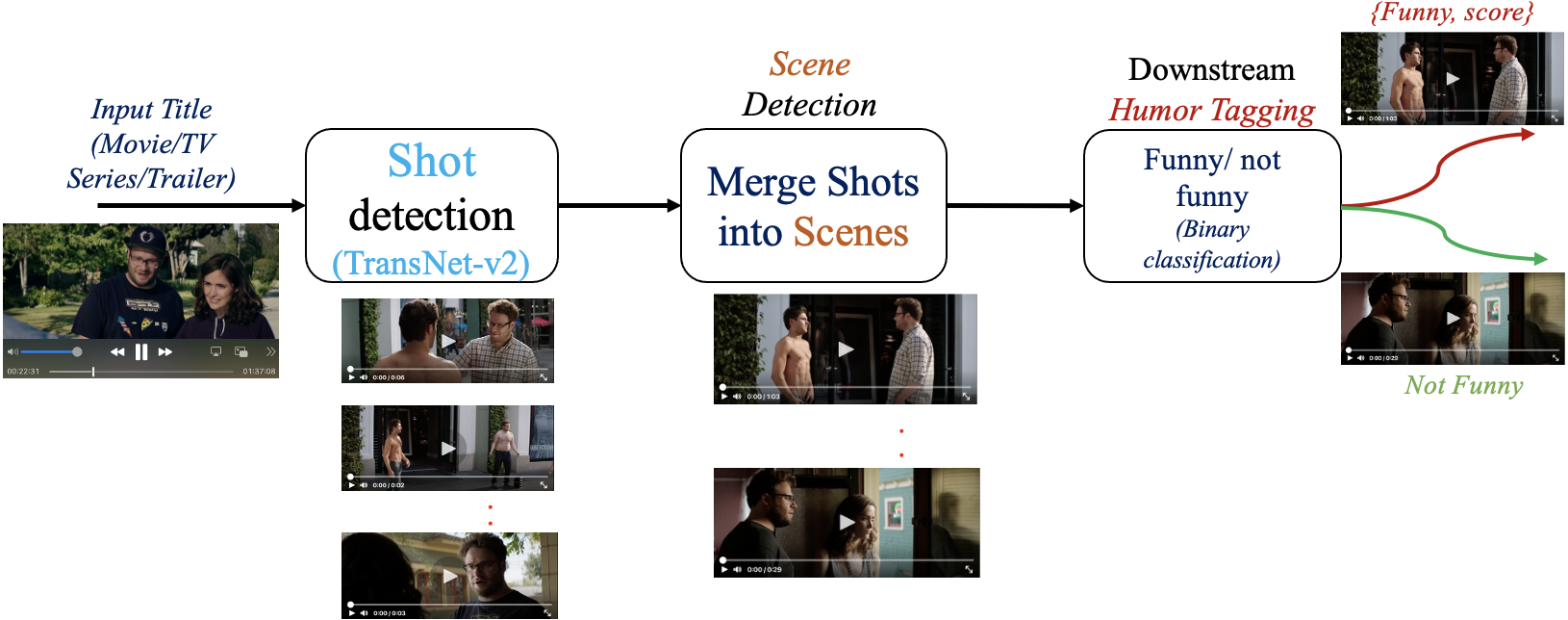
技术框架:该系统主要包含三个阶段:镜头检测、多模态场景定位和幽默标签。首先,进行镜头检测,将视频分割成镜头。然后,利用视觉和文本信息进行场景分割,将镜头组合成场景。最后,利用音频和文本信息对场景进行幽默标签,判断场景是否包含幽默元素。
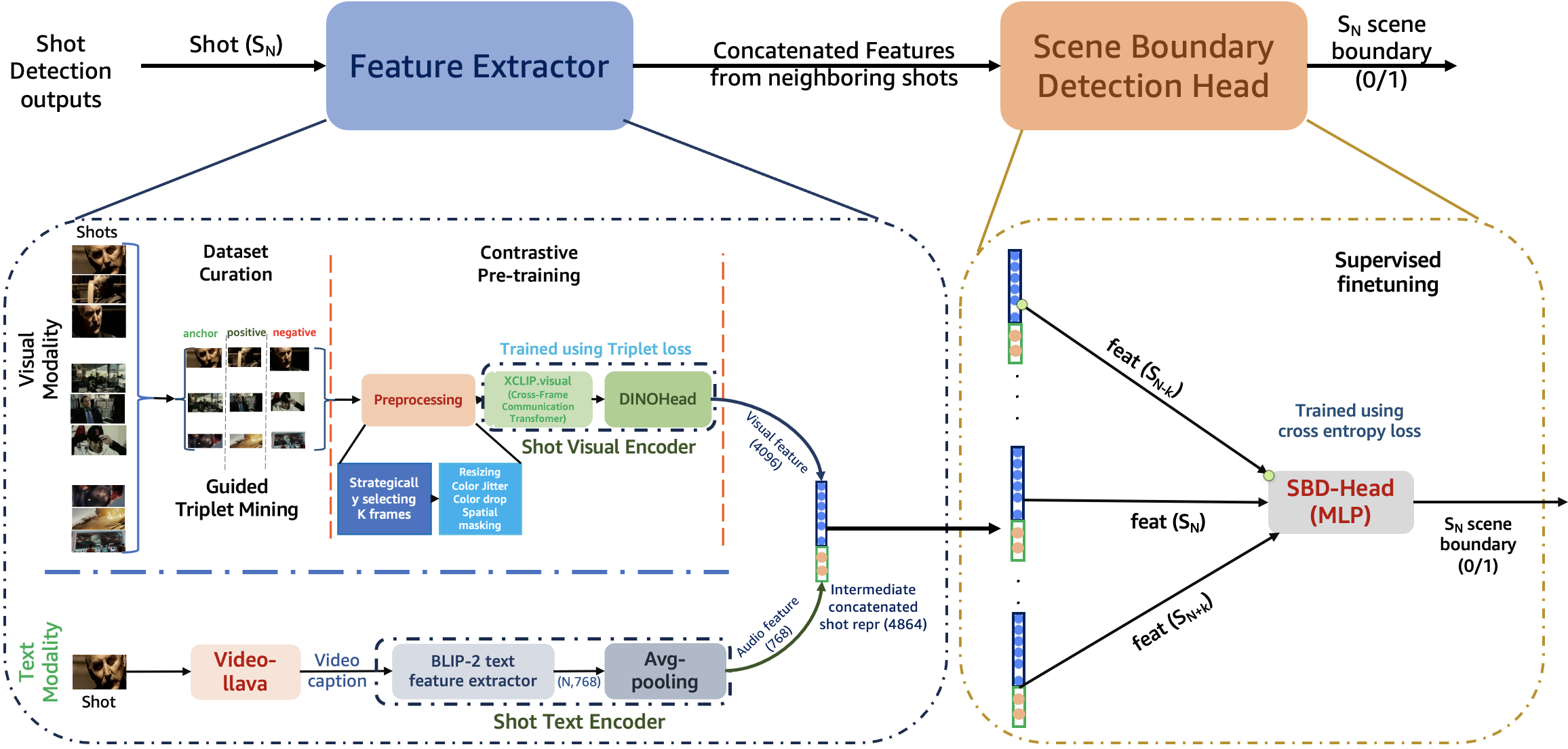
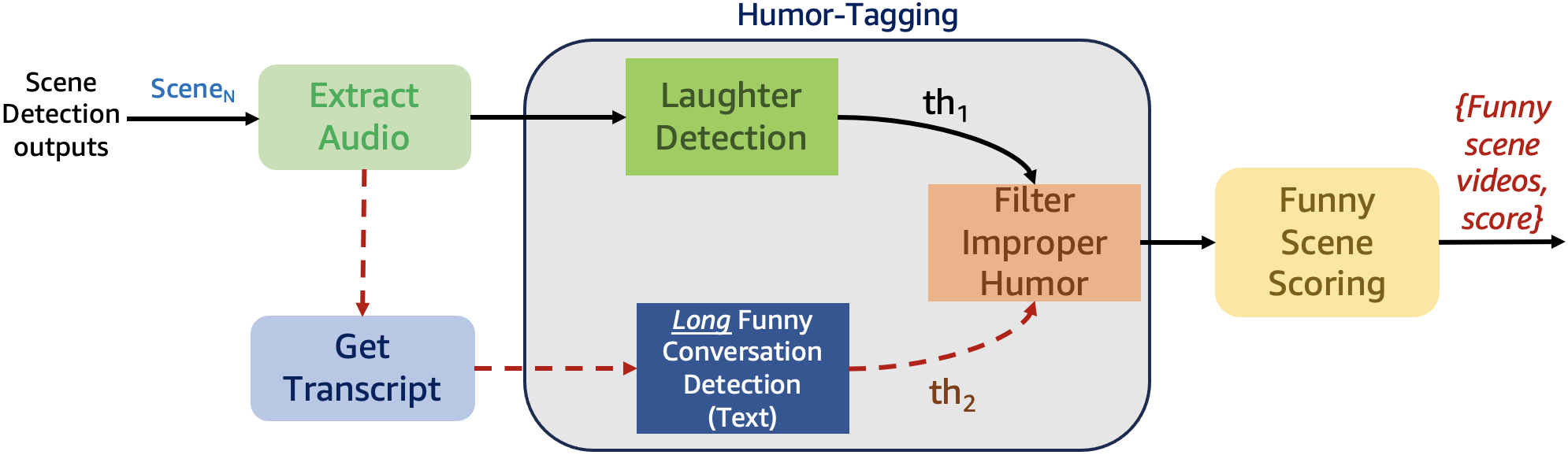
关键创新:该论文的关键创新在于:1) 提出了一种结合视觉和文本线索的新型场景分割方法,提高了场景定位的准确性。2) 通过引导式三元组挖掘改进了镜头表示,提升了特征表达能力。3) 提出了一个利用音频和文本的多模态幽默标签框架,更准确地识别幽默。
关键设计:在场景分割阶段,使用了视觉和文本特征的融合,具体融合方式未知。在镜头表示方面,使用了引导式三元组挖掘,损失函数的设计未知。在幽默标签阶段,使用了音频和文本特征,具体网络结构和参数设置未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该系统在OVSD数据集上,场景检测的AP值比现有方法提高了18.3%。在长文本幽默检测方面,F1分数达到了0.834。在五个电影标题上的评估表明,该流程提取的片段中有87%旨在表达幽默,并且98%的场景被准确定位。这些结果表明该系统在幽默场景提取方面具有显著优势。
🎯 应用场景
该研究成果可应用于视频流媒体平台,自动生成电影预告片和短视频片段,提升用户参与度和内容消费。此外,该技术还可用于电影内容分析、智能剪辑和个性化推荐等领域,具有广泛的应用前景和商业价值。未来,该技术可以扩展到其他类型的长视频内容,如电视剧和纪录片。
📄 摘要(原文)
Automatically extracting engaging and high-quality humorous scenes from cinematic titles is pivotal for creating captivating video previews and snackable content, boosting user engagement on streaming platforms. Long-form cinematic titles, with their extended duration and complex narratives, challenge scene localization, while humor's reliance on diverse modalities and its nuanced style add further complexity. This paper introduces an end-to-end system for automatically identifying and ranking humorous scenes from long-form cinematic titles, featuring shot detection, multimodal scene localization, and humor tagging optimized for cinematic content. Key innovations include a novel scene segmentation approach combining visual and textual cues, improved shot representations via guided triplet mining, and a multimodal humor tagging framework leveraging both audio and text. Our system achieves an 18.3% AP improvement over state-of-the-art scene detection on the OVSD dataset and an F1 score of 0.834 for detecting humor in long text. Extensive evaluations across five cinematic titles demonstrate 87% of clips extracted by our pipeline are intended to be funny, while 98% of scenes are accurately localized. With successful generalization to trailers, these results showcase the pipeline's potential to enhance content creation workflows, improve user engagement, and streamline snackable content generation for diverse cinematic media formats.