CREMD: Crowd-Sourced Emotional Multimodal Dogs Dataset
作者: Jinho Baek, Houwei Cao, Kate Blackwell
分类: cs.CV
发布日期: 2026-02-17
备注: Submitted to arXiv
💡 一句话要点
提出CREMD数据集,用于研究不同模态信息和标注者特征对犬类情感识别的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 犬类情感识别 多模态数据集 众包标注 情感计算 人机交互
📋 核心要点
- 现有犬类情感识别方法缺乏标准化的数据集和客观的评估标准,导致模型泛化能力不足。
- CREMD数据集通过众包方式,收集了不同模态信息和标注者特征下的犬类情感标注,旨在研究这些因素对情感识别的影响。
- 实验结果表明,视觉上下文显著提升标注一致性,标注者背景(如是否养狗)也会影响情感识别的准确性。
📝 摘要(中文)
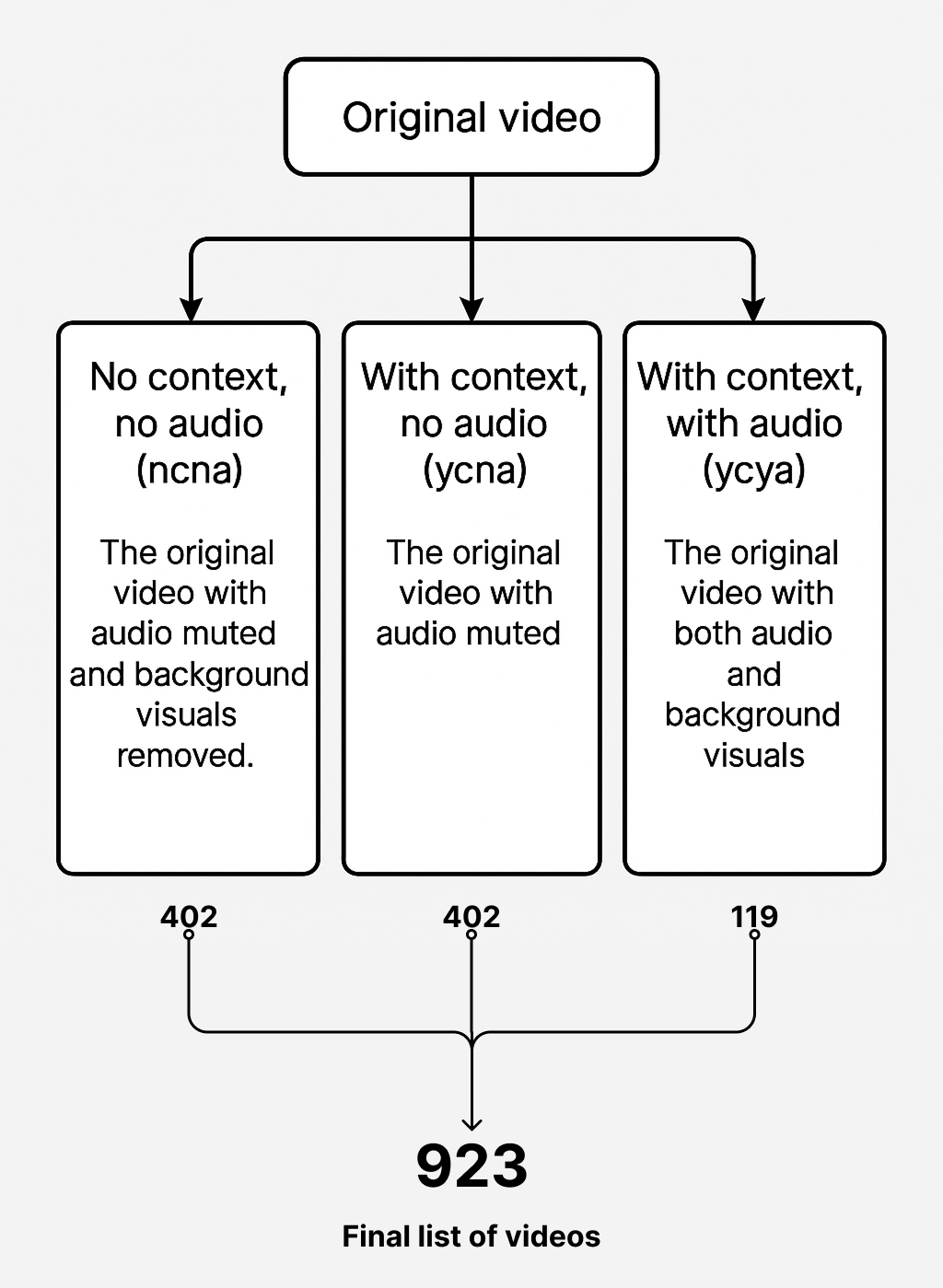
犬类情感识别在改善人与动物互动、兽医护理以及开发犬类福祉监测自动化系统方面至关重要。然而,由于情感评估的主观性和缺乏标准化的ground truth方法,准确解读犬类情感极具挑战。本文提出了CREMD(众包情感多模态犬类数据集),该数据集旨在探索不同的呈现模式(例如,上下文、音频、视频)和标注者特征(例如,是否养狗、性别、专业经验)如何影响犬类情感的感知和标注。该数据集包含923个视频片段,以三种不同的模式呈现:无上下文和音频、有上下文但无音频、以及同时包含上下文和音频。我们分析了来自不同参与者的标注,包括狗主人、专业人士以及具有不同人口背景和经验水平的个体,以识别影响可靠犬类情感识别的因素。研究结果表明:(1)虽然添加视觉上下文显著提高了标注一致性,但由于设计限制(特别是缺少无上下文但有音频的条件以及有限的干净音频可用性),我们关于音频线索的发现尚无定论;(2)与预期相反,非狗主人和男性标注者表现出比狗主人和女性标注者更高的协议水平,而专业人士表现出更高的协议水平,这与我们最初的假设一致;(3)音频的存在显著提高了标注者识别特定情绪(特别是愤怒和恐惧)的信心。
🔬 方法详解
问题定义:现有的犬类情感识别研究面临缺乏高质量、多模态数据集的挑战。主观的情感评估和缺乏标准化的标注方法导致模型难以准确泛化到真实场景。此外,不同背景的观察者对犬类情感的理解可能存在差异,这些差异需要被量化和分析。
核心思路:CREMD数据集的核心思路是通过众包的方式,收集大量带有不同模态信息(视频、音频、上下文)的犬类情感数据,并邀请不同背景的标注者进行标注。通过分析标注结果,研究不同模态信息和标注者特征对情感识别的影响,从而为更可靠的犬类情感识别模型提供数据基础和理论指导。
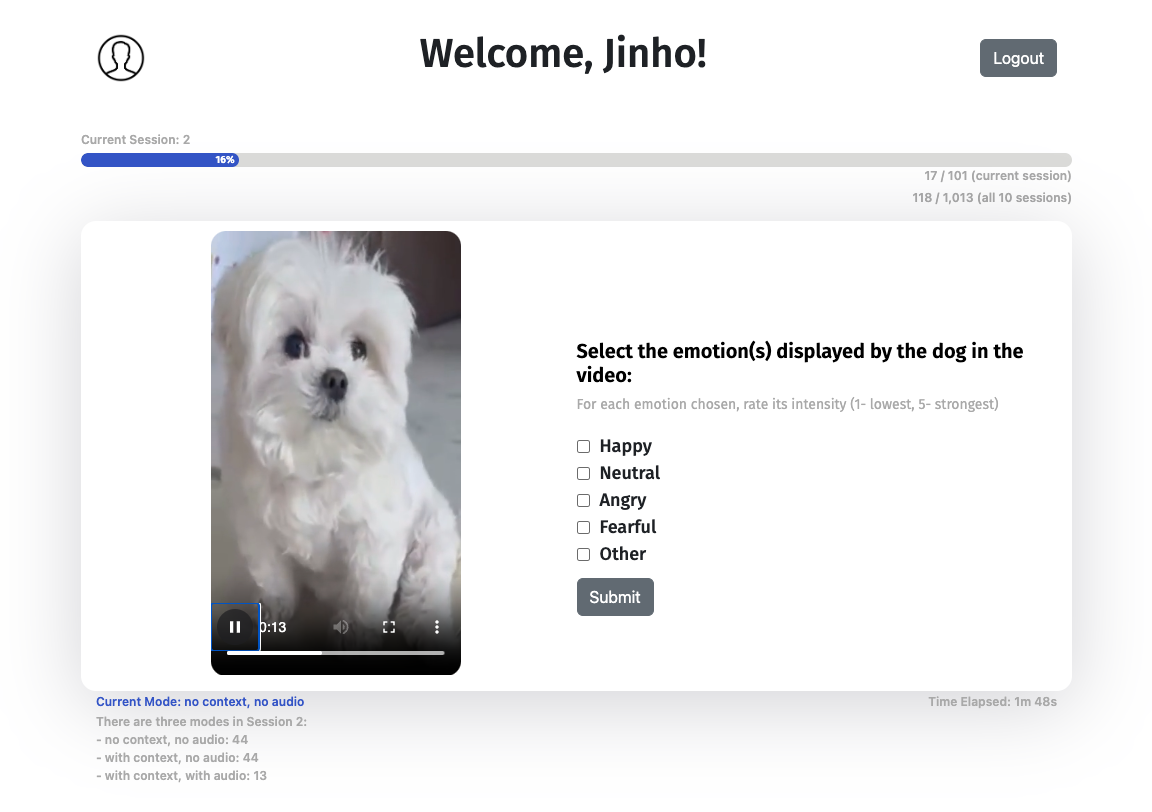
技术框架:CREMD数据集的构建流程主要包括以下几个阶段:1) 视频片段收集:收集包含犬类情感表达的视频片段;2) 模态信息处理:将视频片段处理成三种不同的模式:无上下文和音频、有上下文但无音频、以及同时包含上下文和音频;3) 标注者招募:招募不同背景的标注者,包括狗主人、非狗主人、专业人士等;4) 情感标注:标注者根据视频片段对犬类情感进行标注;5) 数据分析:分析标注结果,研究不同模态信息和标注者特征对情感识别的影响。
关键创新:CREMD数据集的关键创新在于其综合考虑了多模态信息和标注者特征对犬类情感识别的影响。以往的研究往往只关注单一模态的信息,或者忽略了标注者背景对情感识别的影响。CREMD数据集通过提供多模态数据和不同背景的标注,为更全面地理解犬类情感识别提供了可能。
关键设计:CREMD数据集的关键设计包括:1) 三种不同的模态呈现方式,用于研究不同模态信息对情感识别的影响;2) 多样化的标注者群体,用于研究标注者特征对情感识别的影响;3) 详细的标注指南,用于确保标注质量;4) 严格的数据清洗和预处理流程,用于保证数据质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,添加视觉上下文显著提高了标注一致性,说明视觉信息在犬类情感识别中起着重要作用。非狗主人和男性标注者表现出比狗主人和女性标注者更高的协议水平,这与直觉相反,提示我们在设计情感识别系统时需要考虑标注者的背景因素。音频的存在显著提高了标注者识别特定情绪(特别是愤怒和恐惧)的信心。
🎯 应用场景
该研究成果可应用于多个领域,包括:开发更智能的宠物监控设备,能够准确识别犬类的情绪状态并及时发出警报;辅助兽医进行更准确的情绪评估,从而提供更有效的治疗方案;改进人与动物的互动方式,增进彼此的理解和信任;为情感计算和人机交互领域提供新的研究思路和数据支持。
📄 摘要(原文)
Dog emotion recognition plays a crucial role in enhancing human-animal interactions, veterinary care, and the development of automated systems for monitoring canine well-being. However, accurately interpreting dog emotions is challenging due to the subjective nature of emotional assessments and the absence of standardized ground truth methods. We present the CREMD (Crowd-sourced Emotional Multimodal Dogs Dataset), a comprehensive dataset exploring how different presentation modes (e.g., context, audio, video) and annotator characteristics (e.g., dog ownership, gender, professional experience) influence the perception and labeling of dog emotions. The dataset consists of 923 video clips presented in three distinct modes: without context or audio, with context but no audio, and with both context and audio. We analyze annotations from diverse participants, including dog owners, professionals, and individuals with varying demographic backgrounds and experience levels, to identify factors that influence reliable dog emotion recognition. Our findings reveal several key insights: (1) while adding visual context significantly improved annotation agreement, our findings regarding audio cues are inconclusive due to design limitations (specifically, the absence of a no-context-with-audio condition and limited clean audio availability); (2) contrary to expectations, non-owners and male annotators showed higher agreement levels than dog owners and female annotators, respectively, while professionals showed higher agreement levels, aligned with our initial hypothesis; and (3) the presence of audio substantially increased annotators' confidence in identifying specific emotions, particularly anger and fear.