EventMemAgent: Hierarchical Event-Centric Memory for Online Video Understanding with Adaptive Tool Use
作者: Siwei Wen, Zhangcheng Wang, Xingjian Zhang, Lei Huang, Wenjun Wu
分类: cs.CV
发布日期: 2026-02-17
🔗 代码/项目: GITHUB
💡 一句话要点
提出EventMemAgent,利用分层事件中心记忆和自适应工具使用解决在线视频理解问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线视频理解 分层记忆 事件中心 Agentic强化学习 多模态大语言模型
📋 核心要点
- 在线视频理解面临无限视频流与多模态大语言模型有限上下文窗口的矛盾,现有方法难以兼顾长程上下文和细粒度细节。
- EventMemAgent采用分层记忆模块,短期记忆检测事件边界,长期记忆结构化存储事件信息,实现对视频流的有效管理。
- 通过集成多粒度感知工具包和Agentic强化学习,EventMemAgent能够主动捕获证据并学习推理策略,提升理解能力。
📝 摘要(中文)
本文提出EventMemAgent,一个基于分层记忆模块的主动在线视频Agent框架,旨在解决多模态大语言模型(MLLM)在处理无限视频流时上下文窗口受限的问题。该框架采用双层策略:短期记忆检测事件边界,并利用事件粒度的水库抽样动态处理固定长度缓冲区内的视频帧;长期记忆以事件为单位结构化地存档历史观测。此外,框架集成了多粒度感知工具包,用于主动迭代地捕获证据,并采用Agentic强化学习(Agentic RL)将推理和工具使用策略端到端地融入到Agent的内在能力中。实验结果表明,EventMemAgent在在线视频基准测试中取得了具有竞争力的结果。
🔬 方法详解
问题定义:在线视频理解任务需要模型持续感知并进行长程推理,但多模态大语言模型(MLLM)的上下文窗口有限,无法处理无限的视频流。现有方法通常采用被动处理方式,难以同时维护长程上下文和捕捉复杂任务所需的细粒度细节。因此,如何有效地管理和利用视频流中的信息,是该论文要解决的核心问题。
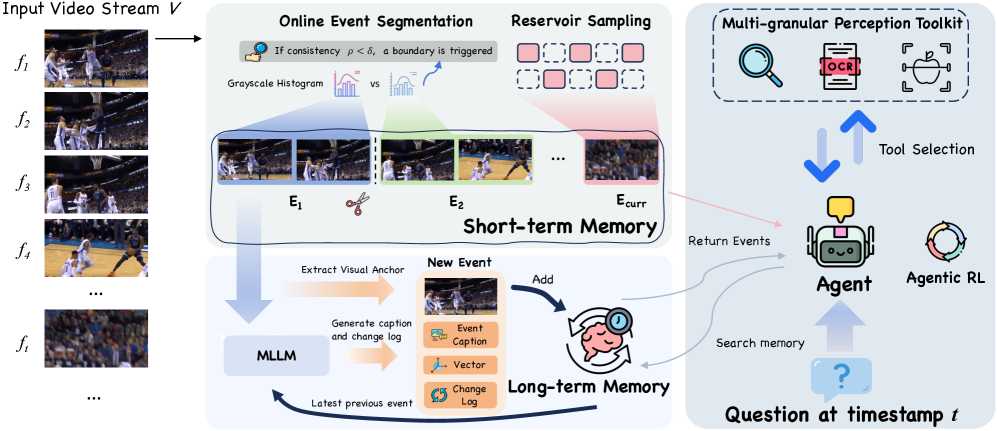
核心思路:论文的核心思路是构建一个基于分层事件中心记忆的Agent,通过短期记忆动态处理事件内的帧,长期记忆结构化存储事件信息,从而实现对视频流的有效管理。此外,通过Agentic强化学习,使Agent能够主动选择合适的工具进行推理,提升理解能力。这种设计旨在模拟人类的记忆和推理过程,使Agent能够更好地理解和处理在线视频。
技术框架:EventMemAgent框架包含以下主要模块:1) 短期记忆模块:用于检测事件边界,并利用事件粒度的水库抽样动态处理固定长度缓冲区内的视频帧。2) 长期记忆模块:以事件为单位结构化地存档历史观测。3) 多粒度感知工具包:提供多种感知工具,用于主动迭代地捕获证据。4) Agentic强化学习模块:用于学习推理和工具使用策略,并将这些策略融入到Agent的内在能力中。整体流程是,视频帧输入后,短期记忆模块检测事件边界并进行抽样,长期记忆模块存储事件信息,Agent利用多粒度感知工具包主动捕获证据,并通过Agentic强化学习不断优化推理和工具使用策略。
关键创新:该论文的关键创新在于以下几点:1) 提出了分层事件中心记忆模块,能够有效地管理和利用视频流中的信息。2) 集成了多粒度感知工具包,使Agent能够主动捕获证据。3) 采用了Agentic强化学习,将推理和工具使用策略端到端地融入到Agent的内在能力中。与现有方法相比,EventMemAgent更加主动和智能,能够更好地理解和处理在线视频。
关键设计:关于关键设计,摘要中没有给出具体参数设置、损失函数、网络结构等技术细节,这部分信息未知。但可以推测,短期记忆模块的水库抽样策略、长期记忆模块的事件结构化存储方式、多粒度感知工具包中工具的选择策略,以及Agentic强化学习模块的奖励函数设计,都会对最终性能产生重要影响。
🖼️ 关键图片


📊 实验亮点
论文实验结果表明,EventMemAgent在在线视频基准测试中取得了具有竞争力的结果。具体的性能数据、对比基线和提升幅度在摘要中未给出,需要参考论文全文才能得知。但可以确定的是,EventMemAgent在在线视频理解任务上表现出了优越的性能。
🎯 应用场景
EventMemAgent可应用于智能监控、视频会议、在线教育等领域。例如,在智能监控中,可以帮助系统理解监控视频中的异常事件;在视频会议中,可以自动提取会议纪要;在在线教育中,可以根据学生的观看行为提供个性化推荐。该研究有望提升机器对在线视频的理解能力,实现更智能的人机交互。
📄 摘要(原文)
Online video understanding requires models to perform continuous perception and long-range reasoning within potentially infinite visual streams. Its fundamental challenge lies in the conflict between the unbounded nature of streaming media input and the limited context window of Multimodal Large Language Models (MLLMs). Current methods primarily rely on passive processing, which often face a trade-off between maintaining long-range context and capturing the fine-grained details necessary for complex tasks. To address this, we introduce EventMemAgent, an active online video agent framework based on a hierarchical memory module. Our framework employs a dual-layer strategy for online videos: short-term memory detects event boundaries and utilizes event-granular reservoir sampling to process streaming video frames within a fixed-length buffer dynamically; long-term memory structuredly archives past observations on an event-by-event basis. Furthermore, we integrate a multi-granular perception toolkit for active, iterative evidence capture and employ Agentic Reinforcement Learning (Agentic RL) to end-to-end internalize reasoning and tool-use strategies into the agent's intrinsic capabilities. Experiments show that EventMemAgent achieves competitive results on online video benchmarks. The code will be released here: https://github.com/lingcco/EventMemAgent.