Sparrow: Text-Anchored Window Attention with Visual-Semantic Glimpsing for Speculative Decoding in Video LLMs
作者: Libo Zhang, Zhaoning Zhang, Wangyang Hong, Peng Qiao, Dongsheng Li
分类: cs.CV, cs.AI
发布日期: 2026-02-17
备注: 15 pages , 6 figures
💡 一句话要点
Sparrow:面向视频LLM推断加速,提出文本锚定窗口注意力机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 推测解码 文本锚定注意力 视觉语义内化 长视频理解
📋 核心要点
- 视频大语言模型(Vid-LLMs)在长视频处理中面临推断速度慢和性能下降的问题,主要原因是注意力机制的计算复杂度随视频长度增加而显著提升。
- Sparrow框架通过文本锚定窗口注意力机制,利用文本隐藏状态重用,减少视觉计算量,并采用中间层视觉状态桥接,提升草稿模型的语义理解能力。
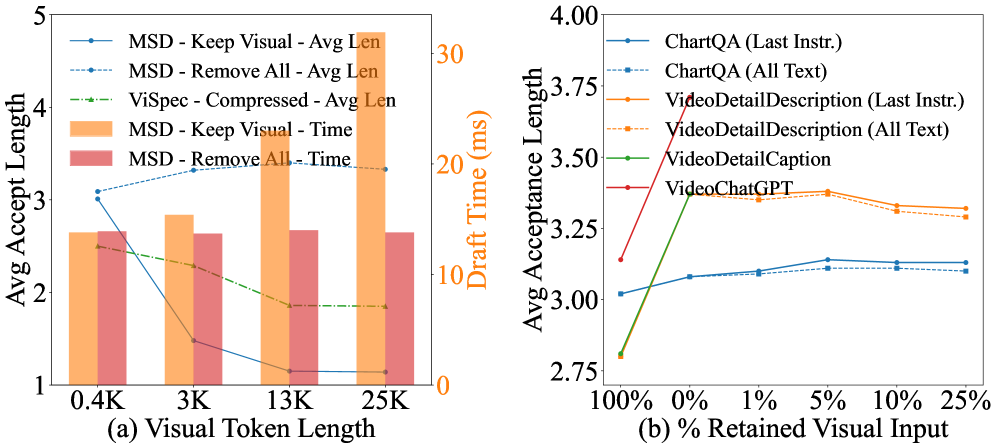
- 实验结果表明,Sparrow框架在长视频任务中实现了显著的加速效果,平均加速比达到2.82倍,有效解决了长序列中的性能退化问题。
📝 摘要(中文)
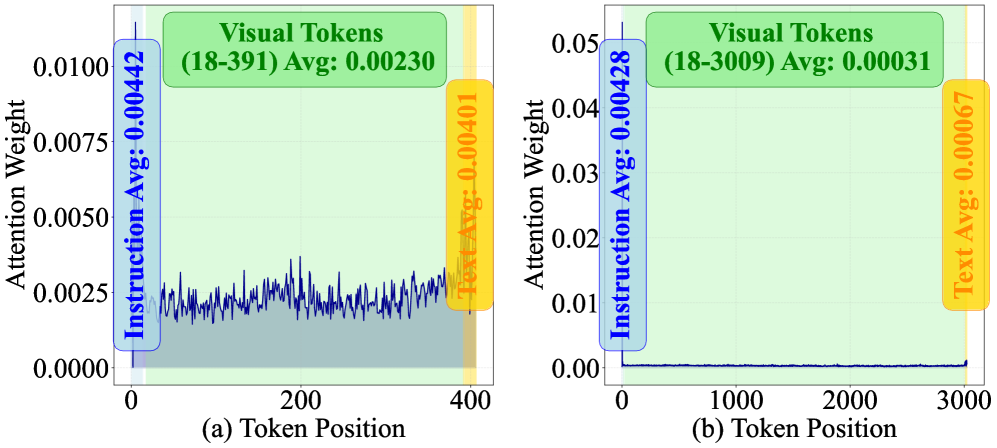
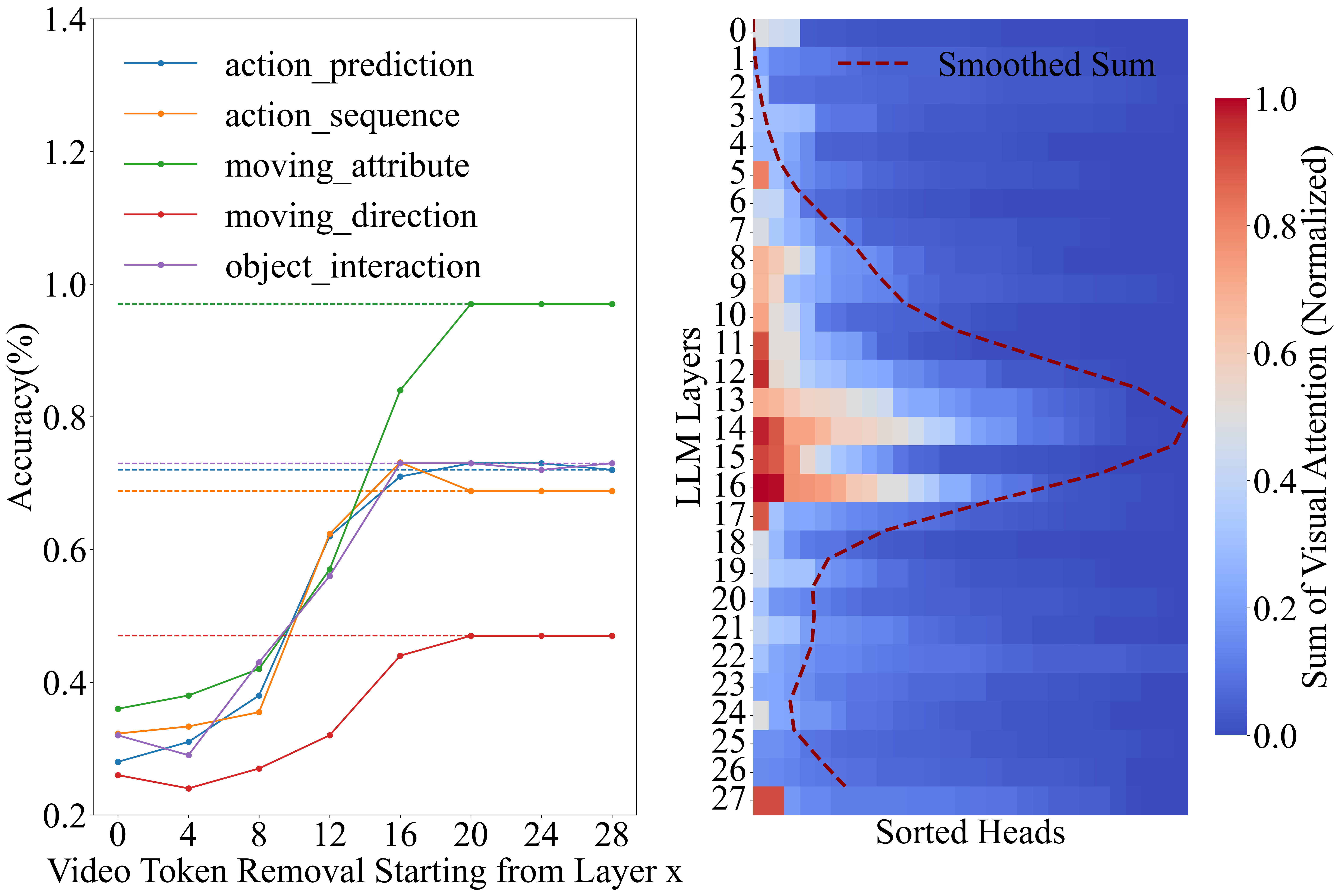
推测解码广泛应用于加速视觉-语言模型(VLMs)的推理,但当应用于视频大语言模型(Vid-LLMs)时,其性能会严重下降。这是因为草稿模型容易陷入注意力稀释和负视觉增益的陷阱,根本原因是键值缓存爆炸和上下文窗口不匹配。我们观察到Vid-LLMs中存在视觉语义内化现象,表明关键的视觉语义在深层交互过程中被隐式地编码到文本隐藏状态中,这使得原始视觉输入在深层推理过程中在结构上变得冗余。为了解决这个问题,我们提出了Sparrow框架,该框架首先利用视觉感知的文本锚定窗口注意力,通过隐藏状态重用来完全卸载视觉计算到目标模型,并利用中间层视觉状态桥接来训练具有语义丰富的中间状态的草稿模型,从而过滤掉低级视觉噪声。此外,还引入了一种多token预测策略来弥合训练-推理分布的差异。实验表明,即使使用25k个视觉token,Sparrow也能实现平均2.82倍的加速,有效地解决了长序列中的性能下降问题,并为实时长视频任务提供了一个实用的解决方案。
🔬 方法详解
问题定义:视频大语言模型(Vid-LLMs)在处理长视频时,由于视觉token数量庞大,导致计算量剧增,推断速度显著下降。现有的推测解码方法在Vid-LLMs中表现不佳,容易出现注意力稀释和负视觉增益,无法有效利用视觉信息。现有方法的痛点在于无法在保证性能的同时,有效降低视觉计算的复杂度,尤其是在长视频序列中。
核心思路:Sparrow框架的核心思路是利用Vid-LLMs中存在的“视觉语义内化”现象,即关键视觉语义已经编码到文本隐藏状态中。因此,可以通过减少对原始视觉输入的依赖,降低视觉计算量。具体来说,通过文本锚定窗口注意力机制,将视觉计算卸载到目标模型,并利用中间层视觉状态桥接来提升草稿模型的语义理解能力。
技术框架:Sparrow框架主要包含两个关键模块:1) 视觉感知的文本锚定窗口注意力(Text-Anchored Window Attention):利用文本隐藏状态重用,减少视觉计算量,并将视觉计算卸载到目标模型。2) 中间层视觉状态桥接(Intermediate-Layer Visual State Bridging):利用语义丰富的中间层视觉状态训练草稿模型,过滤低级视觉噪声。此外,还引入了多token预测策略来弥合训练-推理分布的差异。
关键创新:Sparrow框架的关键创新在于:1) 提出了文本锚定窗口注意力机制,有效减少了视觉计算量,避免了注意力稀释问题。2) 利用中间层视觉状态桥接,提升了草稿模型的语义理解能力,使其能够更好地利用视觉信息。3) 针对训练-推理分布差异,引入了多token预测策略。
关键设计:文本锚定窗口注意力机制的关键在于如何确定窗口大小和位置,以及如何有效地利用文本隐藏状态重用。中间层视觉状态桥接的关键在于选择合适的中间层,以及如何设计损失函数来引导草稿模型学习语义丰富的视觉表示。多token预测策略的关键在于如何选择合适的预测token数量,以及如何平衡预测精度和计算复杂度。具体参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Sparrow框架在长视频任务中实现了显著的加速效果,平均加速比达到2.82倍,即使使用25k个视觉token,也能有效解决长序列中的性能下降问题。相比于传统的推测解码方法,Sparrow框架在保证性能的同时,显著降低了计算复杂度,为实时长视频任务提供了一个实用的解决方案。
🎯 应用场景
Sparrow框架可以应用于各种需要实时处理长视频的场景,例如:实时视频监控、在线教育、远程会议、智能交通等。通过加速视频LLM的推理速度,可以提升用户体验,并降低计算成本。该研究对于推动视频理解和生成技术的发展具有重要意义,并有望在未来的智能视频应用中发挥关键作用。
📄 摘要(原文)
Although speculative decoding is widely used to accelerate Vision-Language Models (VLMs) inference, it faces severe performance collapse when applied to Video Large Language Models (Vid-LLMs). The draft model typically falls into the trap of attention dilution and negative visual gain due to key-value cache explosion and context window mismatches. We observe a visual semantic internalization phenomenon in Vid-LLMs, indicating that critical visual semantics are implicitly encoded into text hidden states during deep-layer interactions, which renders raw visual inputs structurally redundant during deep inference. To address this, we propose the Sparrow framework, which first utilizes visually-aware text-anchored window attention via hidden state reuse to fully offload visual computation to the target model, and leverages intermediate-layer visual state bridging to train the draft model with semantic-rich intermediate states, thereby filtering out low-level visual noise. Additionally, a multi-token prediction strategy is introduced to bridge the training-inference distribution shift. Experiments show that Sparrow achieves an average speedup of 2.82x even with 25k visual tokens, effectively resolving the performance degradation in long sequences and offering a practical solution for real-time long video tasks.