Dual-Signal Adaptive KV-Cache Optimization for Long-Form Video Understanding in Vision-Language Models
作者: Vishnu Sai, Dheeraj Sai, Srinath B, Girish Varma, Priyesh Shukla
分类: cs.CV, cs.AI, cs.LG, cs.PF
发布日期: 2026-02-15
💡 一句话要点
Sali-Cache:面向长视频理解的视觉-语言模型双信号自适应KV-Cache优化
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 长视频理解 视觉-语言模型 KV-Cache优化 光流分析 显著性检测
📋 核心要点
- 现有VLM处理长视频时,KV-Cache随序列长度线性增长,导致内存瓶颈,且现有方法在丢弃tokens前计算完整注意力矩阵,浪费算力。
- Sali-Cache通过光流分析和显著性检测,分别从时间和空间维度过滤冗余信息,在计算注意力之前主动管理内存,实现高效缓存。
- 实验表明,Sali-Cache在LLaVA 1.6上实现了2.20倍的内存压缩,同时保持了BLEU、ROUGE-L和Exact Match指标的100%准确率。
📝 摘要(中文)
视觉-语言模型(VLMs)在处理长视频内容时面临着严重的内存瓶颈,这是由于Key-Value (KV)缓存随着序列长度线性增长所致。现有的解决方案主要采用被动的驱逐策略,即在丢弃tokens之前计算完整的注意力矩阵,导致大量的计算浪费。我们提出了Sali-Cache,一种新颖的先验优化框架,通过主动内存管理实现双信号自适应缓存。通过整合基于光流分析的时间滤波器来检测帧间冗余,以及利用显著性检测的空间滤波器来识别视觉上重要的区域,Sali-Cache在进入计算密集型的注意力操作之前智能地管理内存分配。在LLaVA 1.6架构上的实验评估表明,我们的方法在有效内存使用方面实现了2.20倍的压缩比,同时在BLEU、ROUGE-L和Exact Match指标上保持了100%的准确率。此外,在相同的内存预算约束下,Sali-Cache能够在更长的时间跨度内保留上下文丰富的特征,而不会降低模型性能,从而能够在消费级硬件上高效处理长视频内容。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLM)处理长视频时,由于KV-Cache线性增长导致的内存瓶颈问题。现有方法通常采用被动的缓存驱逐策略,即先计算完整的注意力矩阵,再根据某种规则(如重要性评分)丢弃部分tokens。这种方式的痛点在于,即使最终会被丢弃的tokens,也需要消耗大量的计算资源进行注意力计算,造成了计算浪费,限制了VLM处理长视频的能力。
核心思路:Sali-Cache的核心思路是在进行昂贵的注意力计算之前,通过主动的内存管理来减少需要缓存的tokens数量。具体来说,它利用视频帧间的时间冗余性和空间冗余性,提前过滤掉不重要的信息,从而减少KV-Cache的存储压力。这种“先过滤,后计算”的策略避免了对冗余信息进行不必要的计算,提高了效率。
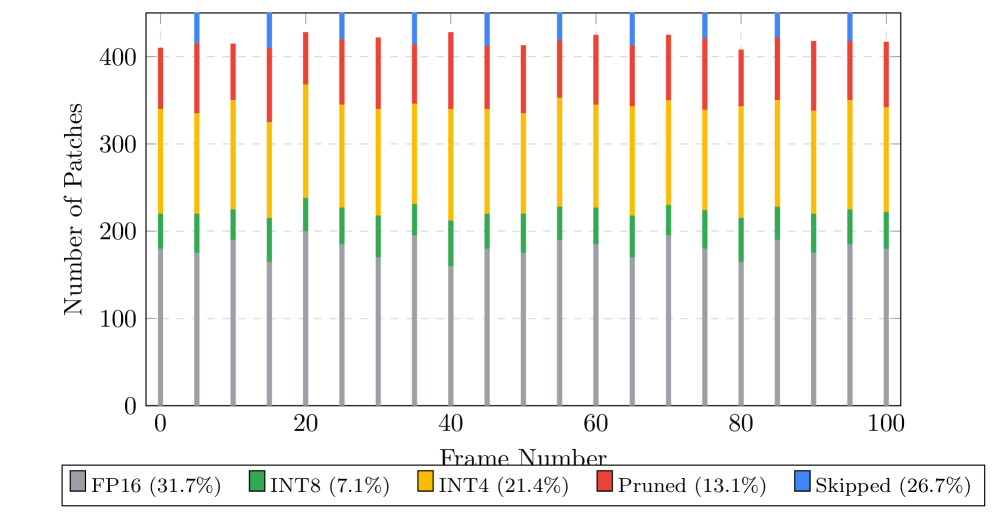
技术框架:Sali-Cache框架主要包含两个关键模块:时间滤波器和空间滤波器。时间滤波器基于光流分析,用于检测视频帧之间的冗余信息,例如静态背景或缓慢移动的物体。空间滤波器则利用显著性检测,识别每一帧中视觉上最重要的区域,例如人物或关键物体。这两个滤波器协同工作,共同决定哪些tokens应该被保留在KV-Cache中,哪些应该被丢弃。整体流程是:输入视频帧 -> 时间滤波器 -> 空间滤波器 -> KV-Cache -> 注意力计算。
关键创新:Sali-Cache的关键创新在于其双信号自适应缓存策略,即同时利用时间和空间信息进行token过滤。与仅依赖单一信号(如重要性评分)的现有方法相比,Sali-Cache能够更准确地识别和过滤冗余信息,从而实现更高的内存压缩率。此外,Sali-Cache是一种先验优化方法,它在注意力计算之前进行内存管理,避免了不必要的计算浪费,提高了整体效率。
关键设计:时间滤波器使用光流的幅度作为帧间差异的度量,幅度低于阈值的区域被认为是冗余的。空间滤波器使用预训练的显著性检测模型来生成显著性图,显著性值低于阈值的区域被认为是视觉上不重要的。这两个阈值是关键的参数,需要根据具体的视频内容和模型性能进行调整。论文中使用了LLaVA 1.6作为基础VLM,并针对其KV-Cache进行了优化。
🖼️ 关键图片

📊 实验亮点
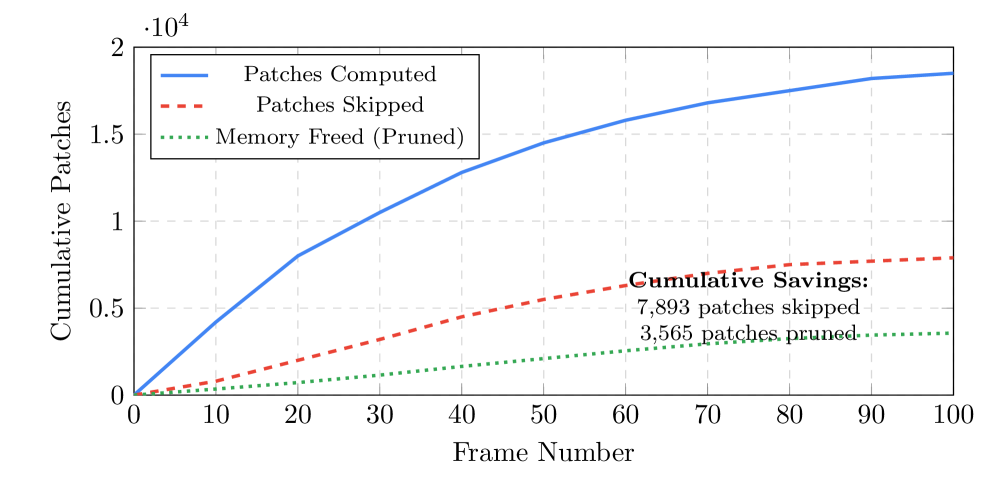
Sali-Cache在LLaVA 1.6架构上实现了显著的性能提升。实验结果表明,该方法在有效内存使用方面实现了2.20倍的压缩比,这意味着在相同的硬件条件下,可以处理更长的视频序列。更重要的是,Sali-Cache在BLEU、ROUGE-L和Exact Match等关键指标上保持了100%的准确率,表明其在压缩内存的同时,并没有牺牲模型的性能。这证明了Sali-Cache是一种高效且有效的长视频理解优化方法。
🎯 应用场景
Sali-Cache具有广泛的应用前景,尤其是在需要处理长视频内容的场景中,例如视频监控、自动驾驶、在线教育、电影分析等。通过降低VLM的内存需求,Sali-Cache使得在消费级硬件上运行复杂的视频理解任务成为可能。未来,该技术有望推动VLM在更多实际应用中的落地,并促进视频内容分析和理解的智能化。
📄 摘要(原文)
Vision-Language Models (VLMs) face a critical memory bottleneck when processing long-form video content due to the linear growth of the Key-Value (KV) cache with sequence length. Existing solutions predominantly employ reactive eviction strategies that compute full attention matrices before discarding tokens, resulting in substantial computational waste. We propose Sali-Cache, a novel a priori optimization framework that implements dual-signal adaptive caching through proactive memory management. By integrating a temporal filter based on optical flow analysis for detecting inter-frame redundancy and a spatial filter leveraging saliency detection for identifying visually significant regions, Sali-Cache intelligently manages memory allocation before entering computationally expensive attention operations. Experimental evaluation on the LLaVA 1.6 architecture demonstrates that our method achieves a 2.20x compression ratio in effective memory usage while maintaining 100% accuracy across BLEU, ROUGE-L, and Exact Match metrics. Furthermore, under identical memory budget constraints, Sali-Cache preserves context-rich features over extended temporal durations without degrading model performance, enabling efficient processing of long-form video content on consumer-grade hardware.