HiVid: LLM-Guided Video Saliency For Content-Aware VOD And Live Streaming
作者: Jiahui Chen, Bo Peng, Lianchen Jia, Zeyu Zhang, Tianchi Huang, Lifeng Sun
分类: cs.CV
发布日期: 2026-02-15
备注: ICLR 2026
💡 一句话要点
HiVid:利用LLM指导的视频显著性,实现内容感知的VOD和直播优化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频显著性 大型语言模型 内容感知流媒体 视频点播 直播
📋 核心要点
- 现有视频流媒体优化依赖人工标注或视觉显著性模型,前者成本高,后者泛化性差,难以适应复杂场景。
- HiVid利用LLM作为人工代理,通过感知、排序和预测模块,为VOD和直播生成高保真内容感知权重。
- 实验表明,HiVid显著提升了VOD和直播的权重预测精度,并改善了用户体验质量(QoE)相关性。
📝 摘要(中文)
内容感知的流媒体需要动态的、分块级别的权重来优化主观体验质量(QoE)。然而,直接的人工标注成本高昂,而视觉显著性模型泛化能力较差。我们提出了HiVid,这是第一个利用大型语言模型(LLM)作为可扩展的人工代理,为视频点播(VOD)和直播生成高保真权重的框架。我们解决了3个重要的挑战:(1)为了扩展LLM有限的模态并规避token限制,我们提出了一个感知模块,用于评估局部上下文窗口中的帧,自回归地构建对视频的连贯理解。(2)对于VOD中局部窗口之间评分不一致的问题,我们提出了一个排序模块,使用一种新颖的LLM指导的归并排序算法进行全局重排序。(3)对于需要低延迟、在线推理且没有未来知识的直播,我们提出了一个预测模块,使用多模态时间序列模型预测未来权重,该模型包含内容感知的注意力和自适应视野,以适应异步LLM推理。大量实验表明,HiVid在VOD和直播的权重预测精度上分别比SOTA基线提高了11.5%和26%。真实用户研究验证了HiVid将流媒体QoE相关性提高了14.7%。
🔬 方法详解
问题定义:论文旨在解决内容感知视频流媒体中,如何高效、准确地获取视频内容重要性权重的问题。现有方法要么依赖昂贵的人工标注,要么使用泛化能力有限的视觉显著性模型,无法很好地优化用户体验质量(QoE)。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大理解和推理能力,将其作为可扩展的人工代理,自动生成视频内容的重要性权重。通过设计合适的模块,克服LLM在处理视频数据时面临的模态限制、token限制以及实时性要求。
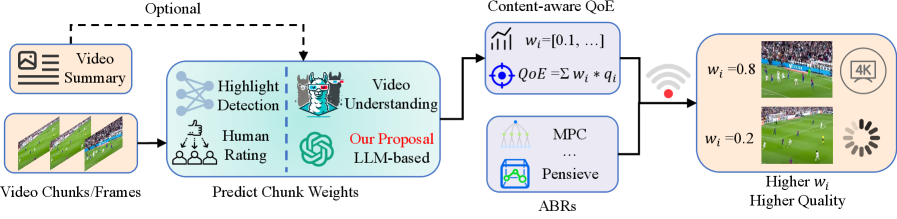
技术框架:HiVid框架包含三个主要模块:感知模块、排序模块和预测模块。感知模块负责处理视频帧,提取视觉特征,并利用LLM构建对视频内容的连贯理解。排序模块针对VOD,使用LLM指导的归并排序算法对视频片段进行全局重排序,解决局部窗口评分不一致的问题。预测模块针对直播,使用多模态时间序列模型预测未来权重,以满足低延迟要求。
关键创新:HiVid的关键创新在于将LLM引入视频显著性预测任务,并设计了针对VOD和直播场景的定制化模块。LLM指导的归并排序算法和多模态时间序列预测模型是两个重要的技术创新点,分别解决了VOD的全局一致性和直播的实时性问题。
关键设计:感知模块采用自回归的方式,逐步构建对视频内容的理解。排序模块使用LLM对视频片段进行两两比较,并根据比较结果进行排序。预测模块使用内容感知的注意力机制,关注视频内容对未来权重的影响,并采用自适应视野来平衡预测精度和延迟。
🖼️ 关键图片
📊 实验亮点
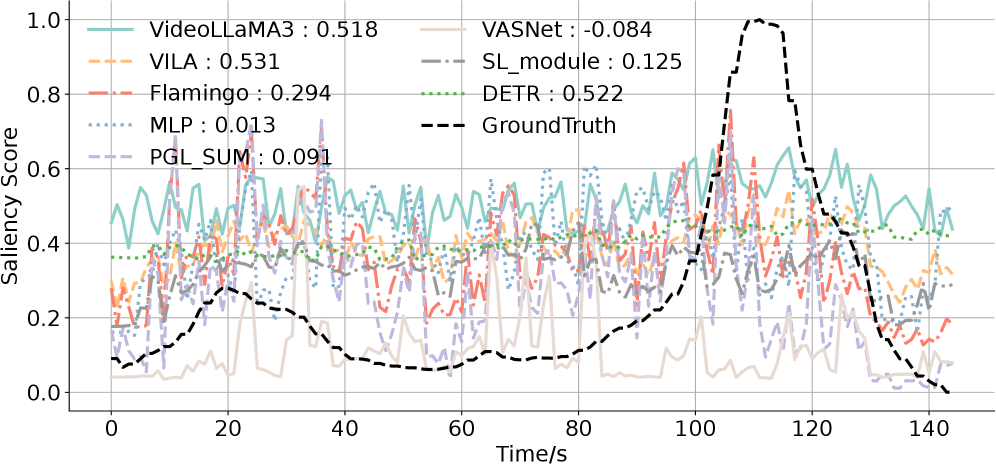
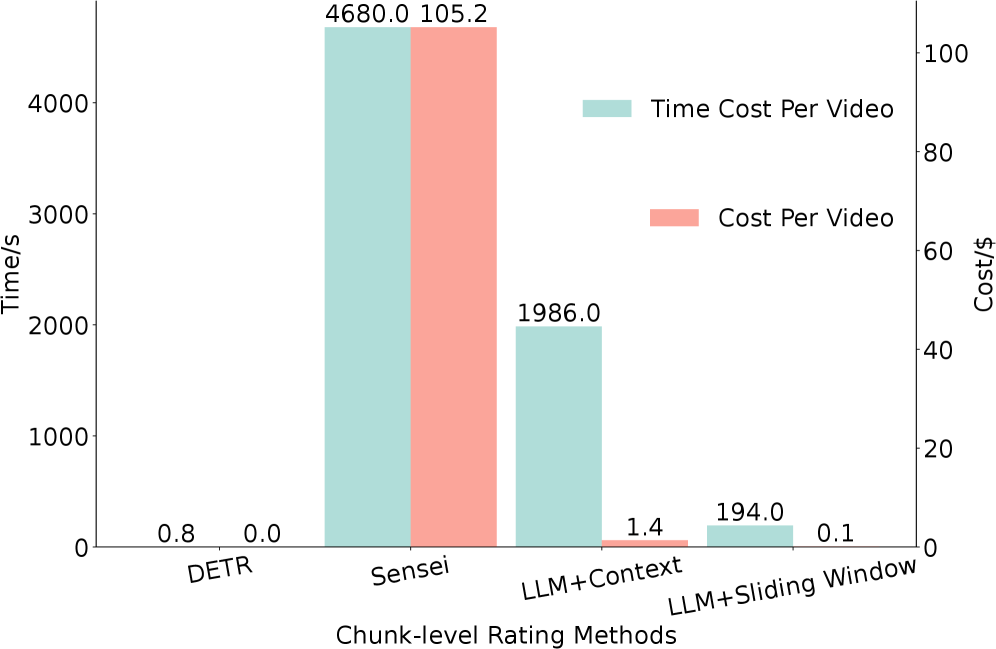
实验结果表明,HiVid在VOD和直播的权重预测精度上分别比SOTA基线提高了11.5%和26%。真实用户研究验证了HiVid将流媒体QoE相关性提高了14.7%。这些数据表明HiVid在提升视频流媒体用户体验方面具有显著优势。
🎯 应用场景
HiVid可应用于各种视频流媒体平台,包括视频点播(VOD)和直播。通过优化视频编码和资源分配,可以提升用户体验质量(QoE),降低带宽成本,并提高平台的竞争力。该研究对于推动内容感知视频流媒体技术的发展具有重要意义。
📄 摘要(原文)
Content-aware streaming requires dynamic, chunk-level importance weights to optimize subjective quality of experience (QoE). However, direct human annotation is prohibitively expensive while vision-saliency models generalize poorly. We introduce HiVid, the first framework to leverage Large Language Models (LLMs) as a scalable human proxy to generate high-fidelity weights for both Video-on-Demand (VOD) and live streaming. We address 3 non-trivial challenges: (1) To extend LLMs' limited modality and circumvent token limits, we propose a perception module to assess frames in a local context window, autoregressively building a coherent understanding of the video. (2) For VOD with rating inconsistency across local windows, we propose a ranking module to perform global re-ranking with a novel LLM-guided merge-sort algorithm. (3) For live streaming which requires low-latency, online inference without future knowledge, we propose a prediction module to predict future weights with a multi-modal time series model, which comprises a content-aware attention and adaptive horizon to accommodate asynchronous LLM inference. Extensive experiments show HiVid improves weight prediction accuracy by up to 11.5\% for VOD and 26\% for live streaming over SOTA baselines. Real-world user study validates HiVid boosts streaming QoE correlation by 14.7\%.