GeoEyes: On-Demand Visual Focusing for Evidence-Grounded Understanding of Ultra-High-Resolution Remote Sensing Imagery
作者: Fengxiang Wang, Mingshuo Chen, Yueying Li, Yajie Yang, Yifan Zhang, Long Lan, Xue Yang, Hongda Sun, Yulin Wang, Di Wang, Jun Song, Jing Zhang, Bo Du
分类: cs.CV, cs.AI
发布日期: 2026-02-15 (更新: 2026-02-20)
💡 一句话要点
GeoEyes:针对超高分辨率遥感影像,提出按需视觉聚焦的证据驱动理解方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 遥感影像 视觉问答 多模态大语言模型 按需缩放 强化学习 证据驱动 超高分辨率 智能体
📋 核心要点
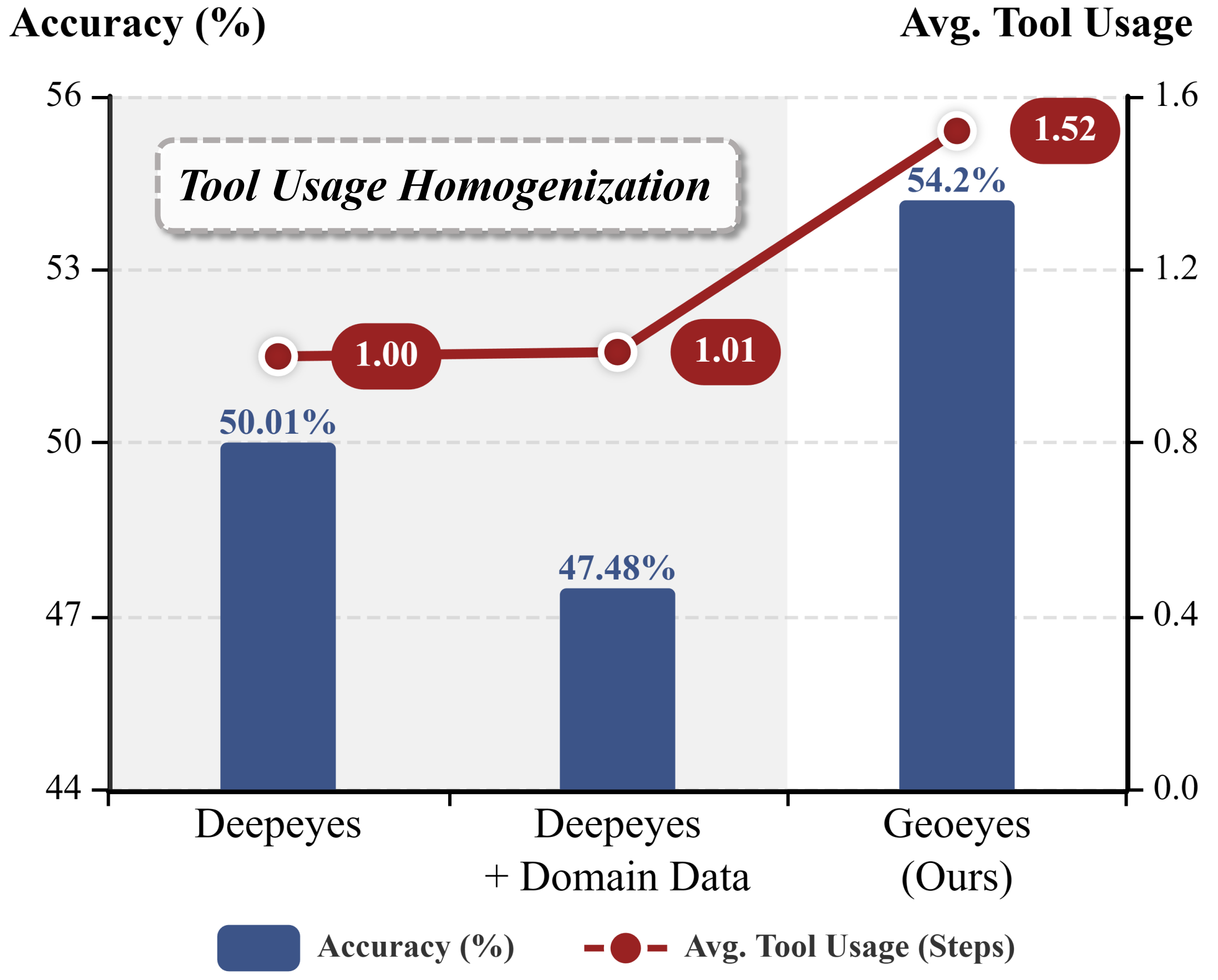
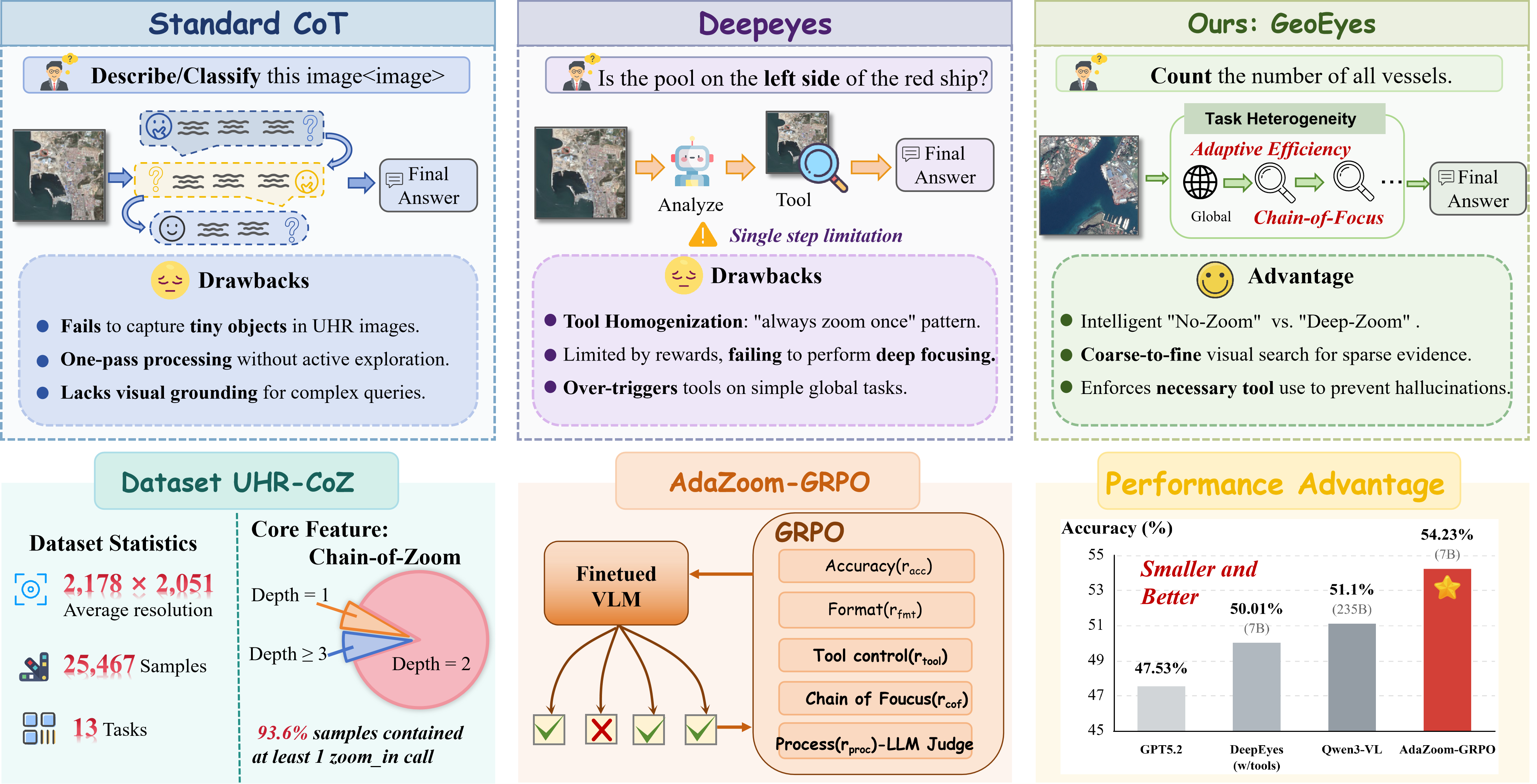
- 现有支持缩放的MLLM在超高分辨率遥感影像VQA任务中,存在工具使用同质化问题,无法有效获取任务相关证据。
- GeoEyes框架通过构建UHR-CoZ数据集和设计AdaZoom-GRPO强化学习方法,鼓励模型按需缩放并关注证据增益。
- 实验表明,GeoEyes在超高分辨率遥感基准测试中取得了显著提升,证明了其在证据驱动理解方面的有效性。
📝 摘要(中文)
“图像思考”范式使多模态大型语言模型(MLLMs)能够通过放大工具主动探索视觉场景。这对于超高分辨率(UHR)遥感VQA至关重要,因为任务相关的线索稀疏且微小。然而,我们观察到现有支持缩放的MLLM中存在一致的失败模式:工具使用同质化,即工具调用崩溃为与任务无关的模式,限制了有效证据的获取。为了解决这个问题,我们提出了GeoEyes,一个分阶段的训练框架,包括(1)一个冷启动SFT数据集,UHR Chain-of-Zoom(UHR-CoZ),它涵盖了不同的缩放机制,以及(2)一种基于智能体的强化学习方法,AdaZoom-GRPO,它明确地奖励缩放交互过程中的证据增益和答案改进。由此产生的模型学习了按需缩放以及适当的停止行为,并在UHR遥感基准测试中取得了显著的改进,在XLRS-Bench上的准确率达到了54.23%。
🔬 方法详解
问题定义:论文旨在解决超高分辨率遥感影像的视觉问答(VQA)问题。现有支持缩放的多模态大语言模型(MLLMs)在处理此类问题时,存在“工具使用同质化”的现象,即模型无法根据任务需求灵活地进行缩放操作,导致无法有效提取图像中的关键信息,从而影响VQA的准确性。现有方法缺乏对证据获取过程的有效建模和奖励机制,使得模型难以学习到合理的缩放策略。
核心思路:GeoEyes的核心思路是通过分阶段训练,使模型能够根据任务需求进行“按需缩放”,并关注缩放过程中证据的增益。具体来说,首先通过一个冷启动的监督微调(SFT)数据集UHR-CoZ,让模型初步具备缩放能力。然后,利用一种基于智能体的强化学习方法AdaZoom-GRPO,显式地奖励模型在缩放交互过程中获得的证据增益和答案改进,从而引导模型学习到更有效的缩放策略。
技术框架:GeoEyes的整体框架包含两个主要阶段:1) 冷启动监督微调(SFT):使用UHR-CoZ数据集对模型进行微调,使其初步具备缩放能力。UHR-CoZ数据集包含多种缩放模式,旨在覆盖不同的任务需求。2) 智能体强化学习:使用AdaZoom-GRPO方法对模型进行强化学习,使其能够根据任务需求进行按需缩放。AdaZoom-GRPO方法通过奖励证据增益和答案改进来引导模型学习。
关键创新:GeoEyes的关键创新在于:1) 提出了UHR-CoZ数据集,该数据集专门用于训练模型进行超高分辨率遥感影像的缩放操作,覆盖了多种缩放模式。2) 提出了AdaZoom-GRPO方法,该方法通过显式地奖励证据增益和答案改进来引导模型学习按需缩放策略。与现有方法相比,GeoEyes更加关注证据获取过程,并能够根据任务需求灵活地进行缩放操作。
关键设计:UHR-CoZ数据集的设计考虑了多种缩放模式,包括不同级别的缩放比例和不同的缩放区域。AdaZoom-GRPO方法中,奖励函数的设计至关重要,需要平衡证据增益和答案改进之间的关系。具体来说,证据增益可以通过计算缩放前后模型对图像的理解程度的变化来衡量,答案改进可以通过比较缩放前后模型生成的答案与标准答案之间的相似度来衡量。此外,还需要设计合适的探索策略,鼓励模型尝试不同的缩放操作。
🖼️ 关键图片

📊 实验亮点
GeoEyes在XLRS-Bench超高分辨率遥感基准测试中取得了显著的改进,准确率达到了54.23%,相较于现有方法有显著提升。实验结果表明,GeoEyes能够有效地解决工具使用同质化问题,并学习到按需缩放的策略,从而提高了模型在超高分辨率遥感影像VQA任务中的性能。
🎯 应用场景
GeoEyes的研究成果可应用于多种领域,例如:遥感影像分析、城市规划、灾害监测、农业估产等。通过按需视觉聚焦,可以更有效地从超高分辨率遥感影像中提取关键信息,为相关决策提供支持。未来,该技术有望与更强大的多模态大语言模型结合,实现更智能化的遥感影像分析和应用。
📄 摘要(原文)
The "thinking-with-images" paradigm enables multimodal large language models (MLLMs) to actively explore visual scenes via zoom-in tools. This is essential for ultra-high-resolution (UHR) remote sensing VQA, where task-relevant cues are sparse and tiny. However, we observe a consistent failure mode in existing zoom-enabled MLLMs: Tool Usage Homogenization, where tool calls collapse into task-agnostic patterns, limiting effective evidence acquisition. To address this, we propose GeoEyes, a staged training framework consisting of (1) a cold-start SFT dataset, UHR Chain-of-Zoom (UHR-CoZ), which covers diverse zooming regimes, and (2) an agentic reinforcement learning method, AdaZoom-GRPO, that explicitly rewards evidence gain and answer improvement during zoom interactions. The resulting model learns on-demand zooming with proper stopping behavior and achieves substantial improvements on UHR remote sensing benchmarks, with 54.23% accuracy on XLRS-Bench.