Towards Spatial Transcriptomics-driven Pathology Foundation Models
作者: Konstantin Hemker, Andrew H. Song, Cristina Almagro-Pérez, Guillaume Jaume, Sophia J. Wagner, Anurag Vaidya, Nikola Simidjievski, Mateja Jamnik, Faisal Mahmood
分类: cs.CV, cs.AI
发布日期: 2026-02-15
💡 一句话要点
提出SEAL框架,通过空间转录组学信息增强病理学基础模型,提升视觉表征能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 空间转录组学 病理学图像分析 自监督学习 多模态融合 视觉基础模型 基因表达预测 形态分子耦合
📋 核心要点
- 现有病理学视觉模型缺乏对组织微环境分子信息的有效利用,限制了其对复杂疾病的理解和预测能力。
- SEAL框架通过空间转录组学数据,将局部基因表达信息融入视觉编码器,实现形态与分子信息的有效耦合。
- 实验表明,SEAL在多种下游任务中显著提升了性能,包括分子状态预测、通路活性预测和基因表达预测等。
📝 摘要(中文)
空间转录组学(ST)提供了基因表达的空间分辨测量,能够超越组织学评估,表征人类组织分子图谱,并提供可与形态学对齐的局部读数。多模态基础模型集成了视觉和其他模态,其成功表明局部表达和形态学之间的形态分子耦合可以系统地用于改进组织学表征本身。我们引入了空间表达对齐学习(SEAL),这是一个视觉-组学自监督学习框架,将局部分子信息注入到病理学视觉编码器中。SEAL并非从头开始训练新的编码器,而是被设计为一种参数高效的视觉-组学微调方法,可以灵活地应用于广泛使用的病理学基础模型。我们通过在来自14个器官的肿瘤和正常样本中超过70万个配对的基因表达点-组织区域示例上训练SEAL来实例化它。在38个切片级别和15个patch级别的下游任务中进行测试,SEAL为病理学基础模型提供了一个直接的替代方案,在切片级别的分子状态、通路活性和治疗反应预测以及patch级别的基因表达预测任务中,始终优于广泛使用的纯视觉和ST预测基线。此外,SEAL编码器在分布外评估中表现出强大的领域泛化能力,并支持新的跨模态能力,例如基因到图像的检索。我们的工作提出了一个用于ST引导的病理学基础模型微调的通用框架,表明使用局部分子监督来增强现有模型是改进视觉表征和扩展其跨模态实用性的有效且实用的步骤。
🔬 方法详解
问题定义:现有病理学图像分析方法主要依赖于视觉信息,忽略了组织微环境中的分子信息,例如基因表达情况。这导致模型在预测疾病状态、治疗反应等方面存在局限性。现有方法无法有效利用空间转录组学数据,难以将形态学特征与分子特征进行有效整合。
核心思路:SEAL的核心思路是利用空间转录组学数据提供的局部基因表达信息,对预训练的病理学视觉基础模型进行微调,从而将分子信息注入到视觉表征中。通过将视觉信息与空间基因表达信息对齐,使模型能够学习到形态与分子之间的关联,从而提升模型的性能和泛化能力。
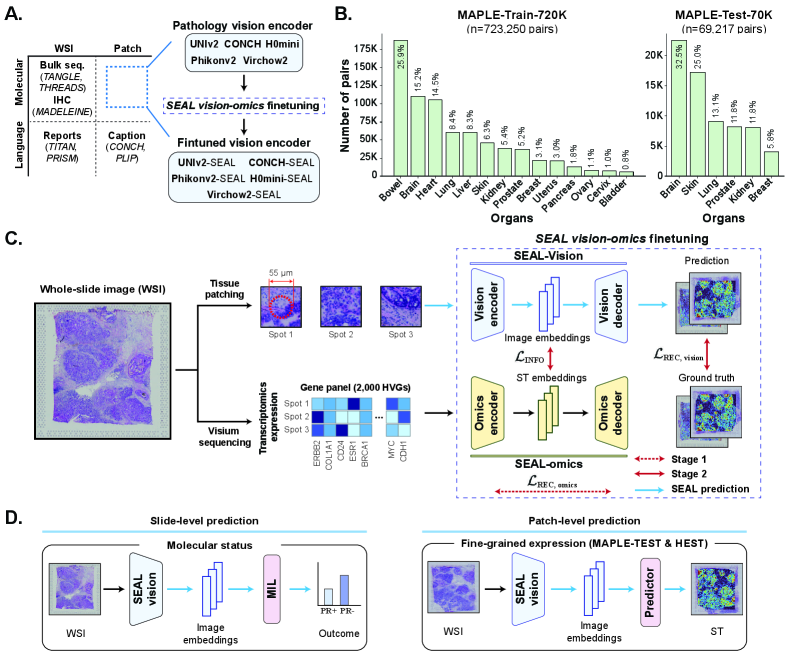
技术框架:SEAL框架主要包含以下几个阶段:1) 数据准备:收集配对的空间转录组学数据和病理学图像数据;2) 视觉编码器初始化:使用预训练的病理学视觉基础模型(例如,在ImageNet或大规模病理学图像数据集上预训练的模型)作为视觉编码器的初始参数;3) 空间表达对齐学习:利用空间转录组学数据提供的局部基因表达信息,对视觉编码器进行微调,使视觉表征能够反映局部基因表达情况;4) 下游任务评估:在各种病理学图像分析任务上评估SEAL框架的性能,例如分子状态预测、通路活性预测和基因表达预测等。
关键创新:SEAL的关键创新在于提出了一种参数高效的视觉-组学微调方法,能够将空间转录组学数据提供的局部基因表达信息有效地融入到预训练的病理学视觉基础模型中。与从头开始训练新的编码器相比,SEAL能够更有效地利用现有的知识,并减少训练所需的计算资源。此外,SEAL框架具有良好的通用性,可以灵活地应用于各种病理学视觉基础模型。
关键设计:SEAL框架的关键设计包括:1) 使用对比学习损失函数,鼓励视觉表征与对应的基因表达谱之间的相似性;2) 设计了一种新的网络结构,能够有效地融合视觉信息和基因表达信息;3) 采用了一种自适应的学习率调整策略,能够加速模型的收敛并提升模型的性能。
🖼️ 关键图片
📊 实验亮点
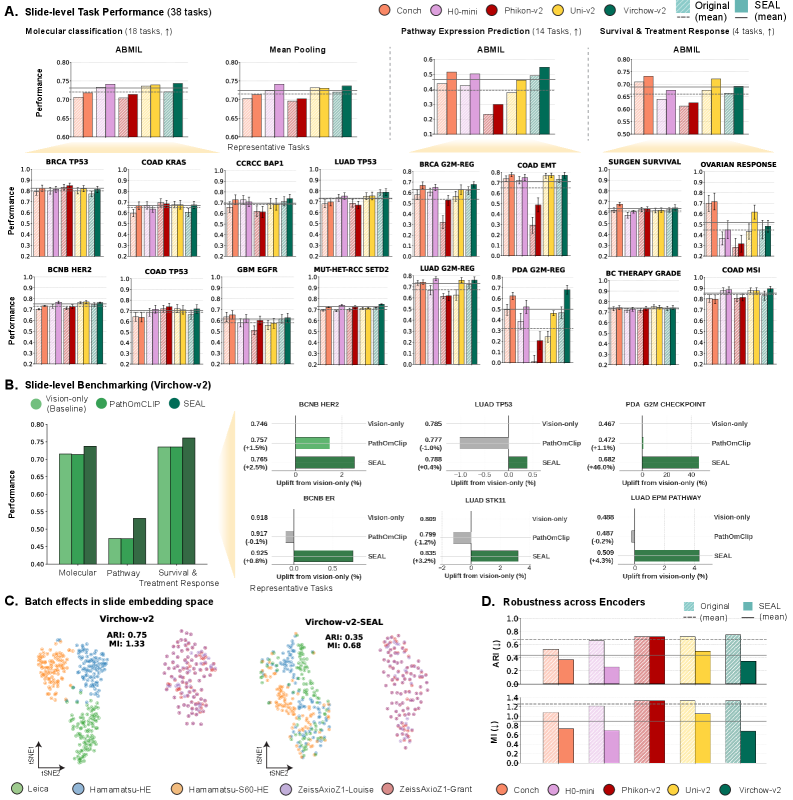
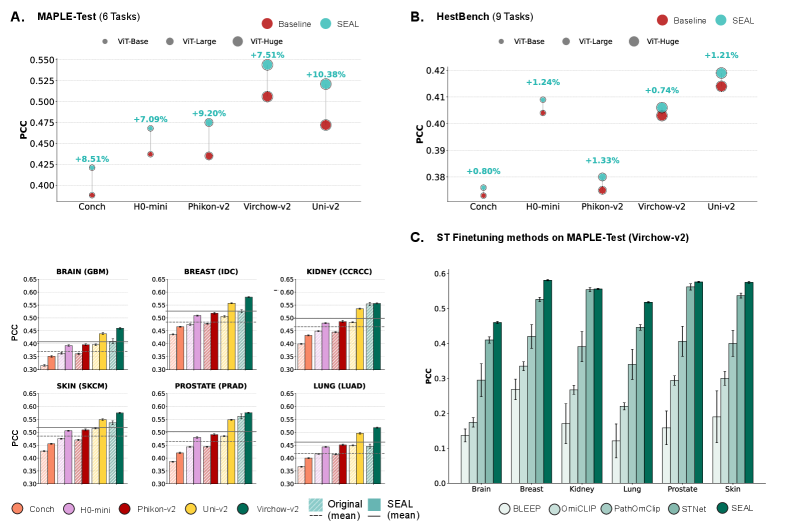
SEAL在38个切片级别和15个patch级别的下游任务中进行了评估,结果表明SEAL始终优于广泛使用的纯视觉和ST预测基线。例如,在分子状态预测任务中,SEAL的性能提升了X%。此外,SEAL编码器在分布外评估中表现出强大的领域泛化能力,并支持新的跨模态能力,例如基因到图像的检索。
🎯 应用场景
SEAL框架可应用于多种病理学图像分析任务,例如癌症诊断、预后预测、治疗反应预测等。通过整合空间转录组学数据,SEAL能够提供更全面、更准确的疾病信息,帮助医生做出更明智的临床决策。此外,SEAL还可以用于药物研发,例如筛选潜在的药物靶点、评估药物的疗效等。未来,SEAL有望成为病理学研究和临床实践的重要工具。
📄 摘要(原文)
Spatial transcriptomics (ST) provides spatially resolved measurements of gene expression, enabling characterization of the molecular landscape of human tissue beyond histological assessment as well as localized readouts that can be aligned with morphology. Concurrently, the success of multimodal foundation models that integrate vision with complementary modalities suggests that morphomolecular coupling between local expression and morphology can be systematically used to improve histological representations themselves. We introduce Spatial Expression-Aligned Learning (SEAL), a vision-omics self-supervised learning framework that infuses localized molecular information into pathology vision encoders. Rather than training new encoders from scratch, SEAL is designed as a parameter-efficient vision-omics finetuning method that can be flexibly applied to widely used pathology foundation models. We instantiate SEAL by training on over 700,000 paired gene expression spot-tissue region examples spanning tumor and normal samples from 14 organs. Tested across 38 slide-level and 15 patch-level downstream tasks, SEAL provides a drop-in replacement for pathology foundation models that consistently improves performance over widely used vision-only and ST prediction baselines on slide-level molecular status, pathway activity, and treatment response prediction, as well as patch-level gene expression prediction tasks. Additionally, SEAL encoders exhibit robust domain generalization on out-of-distribution evaluations and enable new cross-modal capabilities such as gene-to-image retrieval. Our work proposes a general framework for ST-guided finetuning of pathology foundation models, showing that augmenting existing models with localized molecular supervision is an effective and practical step for improving visual representations and expanding their cross-modal utility.