ForgeryVCR: Visual-Centric Reasoning via Efficient Forensic Tools in MLLMs for Image Forgery Detection and Localization
作者: Youqi Wang, Shen Chen, Haowei Wang, Rongxuan Peng, Taiping Yao, Shunquan Tan, Changsheng Chen, Bin Li, Shouhong Ding
分类: cs.CV
发布日期: 2026-02-15
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出ForgeryVCR,利用多模态大语言模型和取证工具实现图像伪造检测与定位
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像伪造检测 多模态大语言模型 视觉推理 取证工具 战略工具学习
📋 核心要点
- 现有MLLM在图像伪造检测中依赖文本描述细微篡改痕迹,易产生幻觉,无法有效捕捉像素级不一致性。
- ForgeryVCR通过集成取证工具箱,将隐蔽的篡改痕迹转化为显式的视觉信息,进行视觉中心推理。
- 采用战略工具学习范式,通过监督微调和强化学习,使MLLM学会主动调用多视图推理路径,提升检测性能。
📝 摘要(中文)
现有的用于图像伪造检测和定位的多模态大语言模型(MLLMs)主要采用以文本为中心的思维链(CoT)范式。然而,强迫这些模型以文本方式描述难以察觉的低级篡改痕迹不可避免地导致幻觉,因为语言模态不足以捕捉这种精细的像素级不一致性。为了克服这个问题,我们提出了ForgeryVCR,该框架结合了一个取证工具箱,通过以视觉为中心的推理将难以察觉的痕迹转化为显式的视觉中间表示。为了实现高效的工具利用,我们引入了一种战略工具学习的后训练范式,包括用于监督微调(SFT)的增益驱动轨迹构建,以及随后由工具效用奖励指导的强化学习(RL)优化。这种范式使MLLM能够成为一个主动的决策者,学习自发地调用多视图推理路径,包括用于精细检查的局部放大,以及对压缩历史、噪声残差和频域中不可见的不一致性的分析。大量的实验表明,ForgeryVCR在检测和定位任务中都达到了最先进(SOTA)的性能,展示了卓越的泛化性和鲁棒性,同时工具冗余度最小。项目主页见https://youqiwong.github.io/projects/ForgeryVCR/。
🔬 方法详解
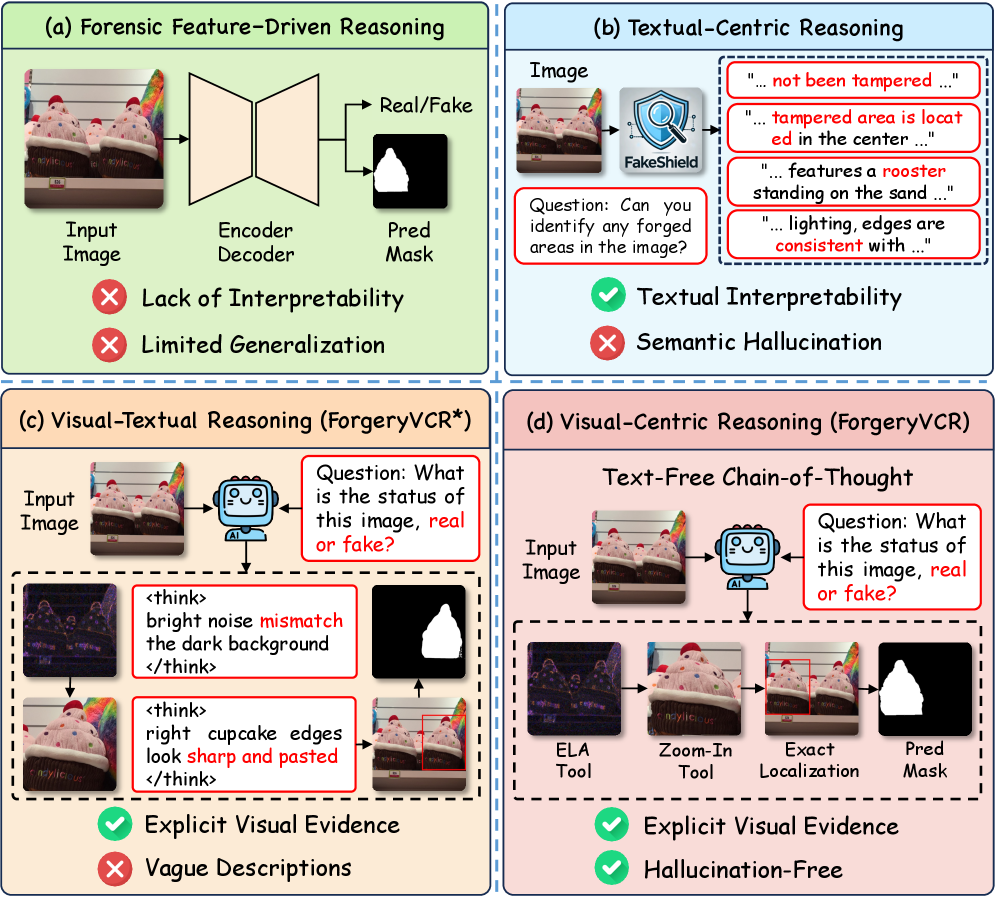
问题定义:现有基于多模态大语言模型(MLLM)的图像伪造检测方法,主要依赖于文本描述图像中的篡改痕迹。然而,图像篡改往往涉及细微的像素级变化,这些变化难以用自然语言精确描述,导致模型产生幻觉,影响检测精度。现有方法缺乏有效利用图像本身信息的能力,难以捕捉到图像中的细微不一致性。
核心思路:ForgeryVCR的核心思路是将图像取证工具集成到MLLM中,使模型能够直接分析图像的底层特征,例如噪声、压缩痕迹和频率域信息。通过将难以察觉的篡改痕迹转化为显式的视觉中间表示,模型可以更有效地进行推理和判断,从而提高检测精度和鲁棒性。这种方法的核心在于利用视觉信息来辅助文本推理,避免过度依赖文本描述。
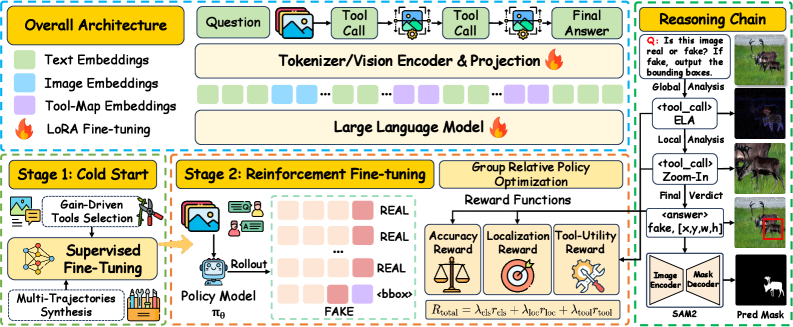
技术框架:ForgeryVCR的整体框架包括以下几个主要模块:1) 图像输入模块:接收待检测的图像。2) 取证工具箱:包含多种图像取证工具,例如噪声分析、压缩历史分析和频率域分析等。3) MLLM推理模块:利用MLLM对图像和取证工具的输出进行推理,判断图像是否被篡改,并定位篡改区域。4) 战略工具学习模块:通过监督微调和强化学习,优化MLLM对取证工具的使用策略。整个流程是,输入图像后,MLLM根据图像内容和自身策略,选择合适的取证工具进行分析,然后结合原始图像和工具的输出进行推理,最终输出检测结果。
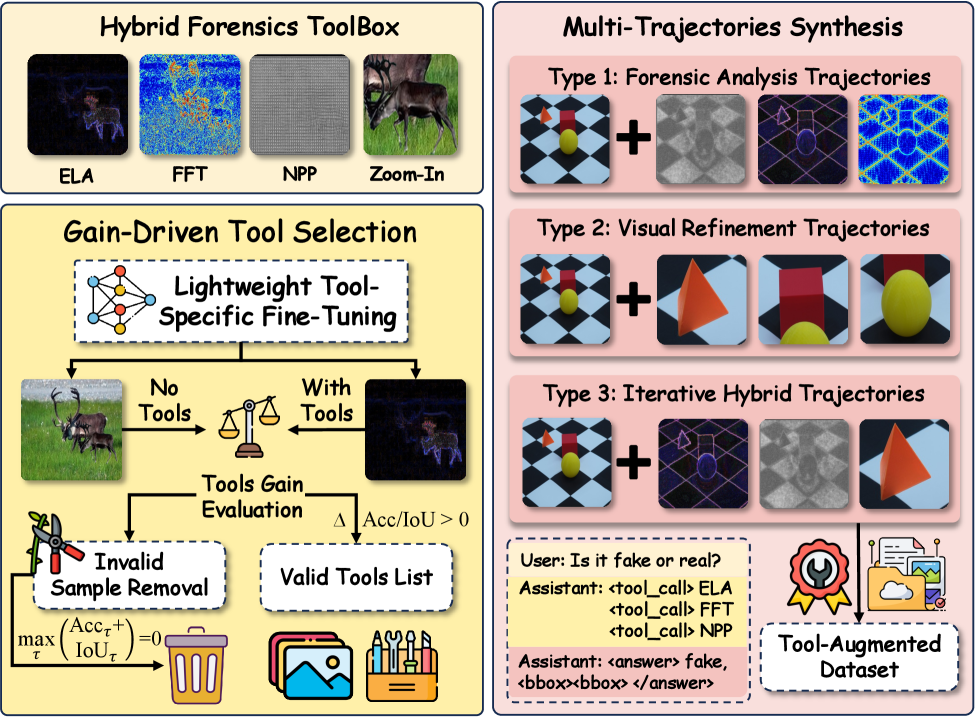
关键创新:ForgeryVCR最重要的技术创新点在于战略工具学习范式。该范式使MLLM能够主动学习如何有效地利用取证工具,而不是被动地接受工具的输出。通过增益驱动的轨迹构建和工具效用奖励,模型可以学习到最优的工具使用策略,从而提高检测性能。与现有方法相比,ForgeryVCR能够更有效地利用图像信息,减少对文本描述的依赖,从而提高检测精度和鲁棒性。
关键设计:在战略工具学习中,采用了增益驱动的轨迹构建方法,用于生成高质量的监督微调数据。同时,设计了工具效用奖励函数,用于指导强化学习过程。该奖励函数根据工具的输出对检测结果的贡献程度进行评估,从而鼓励模型选择更有用的工具。此外,还采用了局部放大技术,使模型能够更精细地检查图像中的篡改痕迹。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
ForgeryVCR在图像伪造检测和定位任务中取得了最先进的性能。实验结果表明,该方法在多个数据集上均优于现有方法,尤其是在泛化性和鲁棒性方面表现突出。通过战略工具学习,模型能够有效地利用取证工具,减少工具冗余,提高检测效率。
🎯 应用场景
ForgeryVCR可应用于数字媒体内容安全、新闻真实性验证、金融欺诈检测等领域。通过自动检测和定位图像伪造,有助于维护网络信息安全,防止虚假信息传播,保障社会诚信。未来可扩展到视频伪造检测,具有广阔的应用前景。
📄 摘要(原文)
Existing Multimodal Large Language Models (MLLMs) for image forgery detection and localization predominantly operate under a text-centric Chain-of-Thought (CoT) paradigm. However, forcing these models to textually characterize imperceptible low-level tampering traces inevitably leads to hallucinations, as linguistic modalities are insufficient to capture such fine-grained pixel-level inconsistencies. To overcome this, we propose ForgeryVCR, a framework that incorporates a forensic toolbox to materialize imperceptible traces into explicit visual intermediates via Visual-Centric Reasoning. To enable efficient tool utilization, we introduce a Strategic Tool Learning post-training paradigm, encompassing gain-driven trajectory construction for Supervised Fine-Tuning (SFT) and subsequent Reinforcement Learning (RL) optimization guided by a tool utility reward. This paradigm empowers the MLLM to act as a proactive decision-maker, learning to spontaneously invoke multi-view reasoning paths including local zoom-in for fine-grained inspection and the analysis of invisible inconsistencies in compression history, noise residuals, and frequency domains. Extensive experiments reveal that ForgeryVCR achieves state-of-the-art (SOTA) performance in both detection and localization tasks, demonstrating superior generalization and robustness with minimal tool redundancy. The project page is available at https://youqiwong.github.io/projects/ForgeryVCR/.