CoCoEdit: Content-Consistent Image Editing via Region Regularized Reinforcement Learning
作者: Yuhui Wu, Chenxi Xie, Ruibin Li, Liyi Chen, Qiaosi Yi, Lei Zhang
分类: cs.CV
发布日期: 2026-02-15
💡 一句话要点
CoCoEdit:通过区域正则化强化学习实现内容一致的图像编辑
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像编辑 内容一致性 强化学习 区域正则化 像素级相似度
📋 核心要点
- 现有图像编辑模型主要关注目标对象和区域的编辑效果,容易导致非目标区域产生不希望的变化。
- CoCoEdit通过区域正则化强化学习,结合像素级相似度奖励和区域正则化器,确保编辑质量和内容一致性。
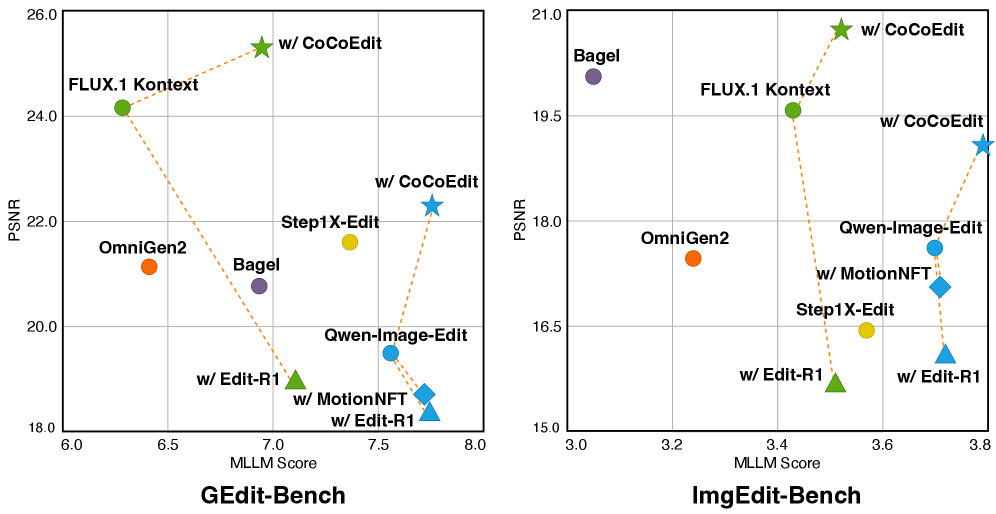
- 实验结果表明,CoCoEdit在编辑质量和内容一致性方面均优于现有方法,并在PSNR/SSIM指标和人类主观评分上有所提升。
📝 摘要(中文)
本文提出了一种后训练框架CoCoEdit,用于实现内容一致的图像编辑,该框架通过区域正则化强化学习实现。首先,我们通过改进的指令和掩码来扩充现有的编辑数据集,从中整理出4万个多样且高质量的样本作为训练集。然后,我们引入像素级相似度奖励来补充基于MLLM的奖励,使模型能够在编辑过程中确保编辑质量和内容一致性。为了克服奖励的空间不可知性,我们提出了一种基于区域的正则化器,旨在为高奖励样本保留非编辑区域,同时鼓励低奖励样本的编辑效果。在评估方面,我们为GEdit-Bench和ImgEdit-Bench标注了编辑掩码,引入像素级相似度指标来衡量内容一致性和编辑质量。将CoCoEdit应用于Qwen-Image-Edit和FLUX-Kontext,我们不仅获得了与最先进模型相比具有竞争力的编辑分数,而且在内容一致性方面也显著提高,这通过PSNR/SSIM指标和人类主观评分来衡量。
🔬 方法详解
问题定义:现有图像编辑方法在编辑目标区域时,往往忽略了对非目标区域的保护,导致内容不一致的问题。例如,在修改图像中人物的服装时,背景可能发生不希望的改变。现有方法缺乏对全局内容一致性的有效约束,使得编辑结果难以令人满意。
核心思路:CoCoEdit的核心思路是通过强化学习,训练一个能够同时优化编辑质量和内容一致性的模型。通过引入像素级相似度奖励和区域正则化器,引导模型在编辑过程中更好地权衡编辑效果和内容保护。像素级相似度奖励鼓励编辑后的图像与原始图像在非编辑区域保持一致,而区域正则化器则根据奖励值自适应地调整对非编辑区域的保护力度。
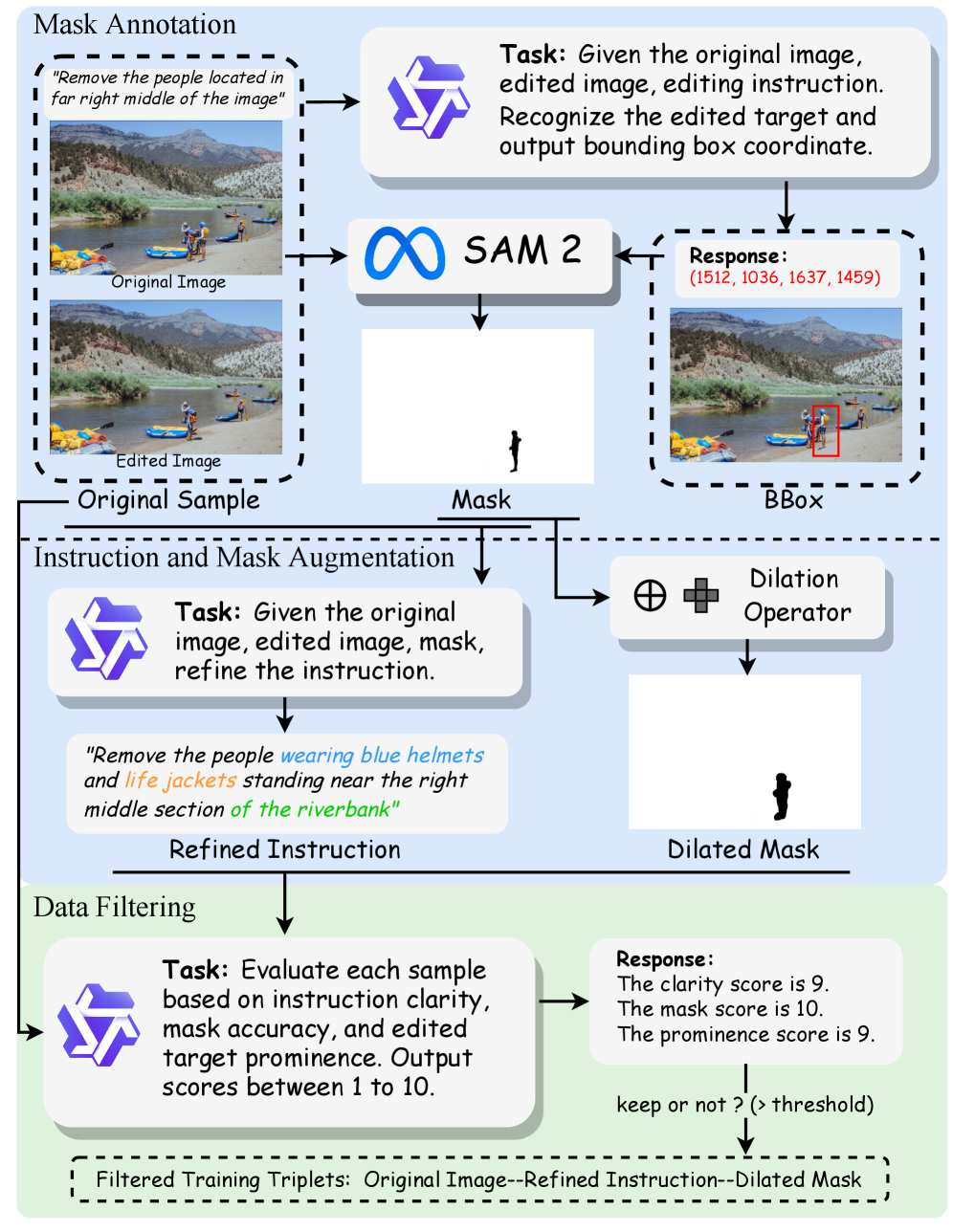
技术框架:CoCoEdit是一个后训练框架,可以应用于现有的图像编辑模型。其主要流程包括:1) 数据集构建:通过改进的指令和掩码扩充现有数据集,构建高质量的训练集。2) 奖励函数设计:结合基于MLLM的奖励和像素级相似度奖励,评估编辑结果的质量和内容一致性。3) 区域正则化:根据奖励值,对非编辑区域进行正则化,鼓励高奖励样本保持内容一致,低奖励样本进行有效编辑。4) 强化学习训练:使用强化学习算法,训练模型以最大化奖励函数,从而实现内容一致的图像编辑。
关键创新:CoCoEdit的关键创新在于:1) 提出了像素级相似度奖励,能够更精细地衡量内容一致性。2) 引入了区域正则化器,能够根据奖励值自适应地调整对非编辑区域的保护力度,克服了奖励函数的空间不可知性。3) 构建了高质量的训练数据集,为强化学习提供了充足的训练样本。
关键设计:像素级相似度奖励采用PSNR和SSIM等指标来衡量编辑前后非编辑区域的相似度。区域正则化器通过对非编辑区域的像素值进行约束,防止其发生过大的改变。强化学习算法采用PPO(Proximal Policy Optimization)等算法,以稳定地训练模型。数据集构建过程中,采用了数据增强技术,增加了数据的多样性。
🖼️ 关键图片

📊 实验亮点
CoCoEdit在Qwen-Image-Edit和FLUX-Kontext上进行了实验,结果表明,该方法不仅获得了与最先进模型相比具有竞争力的编辑分数,而且在内容一致性方面也显著提高。具体而言,通过PSNR/SSIM指标和人类主观评分,CoCoEdit在内容一致性方面取得了显著的提升,证明了其有效性。
🎯 应用场景
CoCoEdit具有广泛的应用前景,例如照片修复、图像风格迁移、虚拟试穿等。它可以应用于电商平台,帮助用户更好地展示商品;也可以应用于社交媒体,让用户轻松创作出高质量的图像内容。此外,该技术还可以应用于游戏开发、电影制作等领域,提高图像编辑的效率和质量,具有重要的实际价值和未来影响。
📄 摘要(原文)
Image editing has achieved impressive results with the development of large-scale generative models. However, existing models mainly focus on the editing effects of intended objects and regions, often leading to unwanted changes in unintended regions. We present a post-training framework for Content-Consistent Editing (CoCoEdit) via region regularized reinforcement learning. We first augment existing editing datasets with refined instructions and masks, from which 40K diverse and high quality samples are curated as training set. We then introduce a pixel-level similarity reward to complement MLLM-based rewards, enabling models to ensure both editing quality and content consistency during the editing process. To overcome the spatial-agnostic nature of the rewards, we propose a region-based regularizer, aiming to preserve non-edited regions for high-reward samples while encouraging editing effects for low-reward samples. For evaluation, we annotate editing masks for GEdit-Bench and ImgEdit-Bench, introducing pixel-level similarity metrics to measure content consistency and editing quality. Applying CoCoEdit to Qwen-Image-Edit and FLUX-Kontext, we achieve not only competitive editing scores with state-of-the-art models, but also significantly better content consistency, measured by PSNR/SSIM metrics and human subjective ratings.