Low-Pass Filtering Improves Behavioral Alignment of Vision Models
作者: Max Wolff, Thomas Klein, Evgenia Rusak, Felix Wichmann, Wieland Brendel
分类: cs.CV
发布日期: 2026-02-14
备注: 10 pages, 6 figures
💡 一句话要点
低通滤波显著提升视觉模型与人类视觉行为的一致性
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 低通滤波 视觉模型 行为一致性 深度神经网络 人类视觉 图像处理 高斯模糊
📋 核心要点
- 深度神经网络在视觉任务上表现优异,但与人类视觉行为存在差异,尤其在误差一致性和形状偏见方面。
- 该研究表明,生成模型表现出的更好的一致性,主要源于其图像预处理中的低通滤波效应。
- 通过在判别模型中引入低通滤波,显著提升了模型与人类视觉行为的一致性,甚至达到了新的SOTA。
📝 摘要(中文)
尽管深度神经网络(DNNs)在计算机视觉基准测试中表现出色,但在误差一致性和形状偏见方面,它们在模拟人类视觉行为方面仍有不足。最近的研究假设,通过生成式而非判别式分类器可以显著提高行为一致性,这对人类视觉模型具有深远的影响。本文表明,生成模型一致性的提高很大程度上可以归因于生成模型中看似无害的调整大小操作,该操作有效地充当了低通滤波器。在一系列受控实验中,我们表明,从判别模型(如CLIP)中移除高频空间信息可以显著提高其行为一致性。简单地在测试时模糊图像——而不是在模糊图像上训练——在模型与人类基准测试中实现了新的最先进的分数,缩小了DNN与人类观察者之间当前一致性差距的一半。此外,低通滤波器可能是最优的,我们通过直接优化滤波器以实现对齐来证明这一点。为了将最优滤波器的性能置于上下文中,我们计算了基准测试中所有可能的帕累托最优解的前沿,这在以前是未知的。我们通过观察到最优高斯滤波器的频谱大致匹配人类视觉系统实现的带通滤波器的频谱来解释我们的发现。我们表明,对比敏感度函数(描述人类检测正弦光栅所需的对比度阈值的倒数,作为时空频率的函数)可以通过特定宽度的高斯滤波器很好地近似,该宽度也最大化了误差一致性。
🔬 方法详解
问题定义:现有深度神经网络在计算机视觉任务中取得了显著成果,但它们在模拟人类视觉行为方面仍然存在差距。具体来说,模型在误差模式和形状偏见上与人类观察者存在差异。之前的研究认为,使用生成模型而非判别模型可以解决这个问题,但其根本原因尚不明确。
核心思路:本文的核心思路是,生成模型之所以表现出更好的人类行为一致性,是因为其图像预处理步骤中包含的图像缩放操作实际上起到了低通滤波器的作用,移除了图像中的高频信息。因此,通过在判别模型中显式地引入低通滤波,可以提升其与人类视觉行为的一致性。
技术框架:该研究主要通过实验来验证低通滤波对模型行为一致性的影响。实验流程包括:1) 选择判别模型(如CLIP);2) 在测试阶段对输入图像应用不同类型的低通滤波器(如高斯模糊);3) 使用模型进行图像分类或识别;4) 评估模型与人类观察者在误差一致性等指标上的表现。此外,研究还通过优化滤波器参数来寻找最佳的低通滤波效果。
关键创新:该研究的关键创新在于,它揭示了低通滤波在提升模型与人类视觉行为一致性方面的重要作用。与之前认为需要使用生成模型才能实现更好一致性的观点不同,该研究表明,通过简单的图像预处理技术(即低通滤波),就可以显著提升判别模型的行为一致性。
关键设计:研究中使用了高斯模糊作为主要的低通滤波器,并探索了不同模糊半径(即高斯核的标准差)对模型性能的影响。此外,研究还通过优化滤波器参数来寻找最佳的低通滤波效果。对比敏感度函数被用于分析人类视觉系统对不同频率信息的敏感度,并与最优高斯滤波器的频谱进行比较。
🖼️ 关键图片
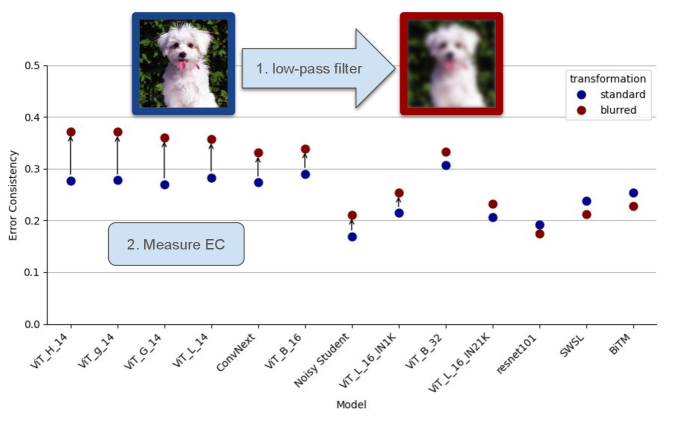
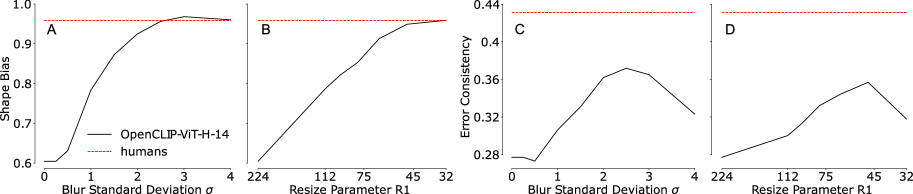
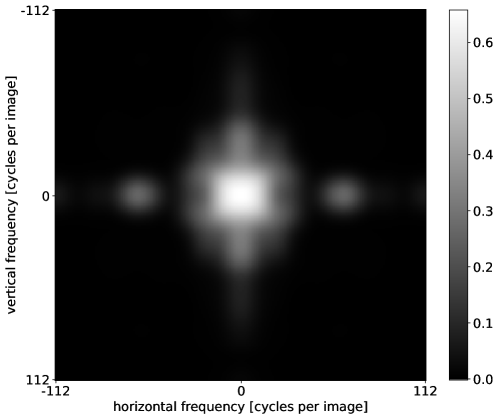
📊 实验亮点
研究表明,在判别模型(如CLIP)中加入低通滤波,可以显著提高其与人类视觉行为的一致性。通过在测试时对图像进行模糊处理,模型在模型与人类基准测试中取得了新的SOTA分数,将DNN与人类观察者之间的一致性差距缩小了一半。此外,研究还发现,最优高斯滤波器的频谱与人类视觉系统的带通滤波器频谱近似匹配。
🎯 应用场景
该研究成果可应用于提升计算机视觉系统在人机交互、自动驾驶等领域的性能。通过模拟人类视觉特性,可以使模型更好地理解和处理真实世界的图像,从而提高系统的鲁棒性和可靠性。此外,该研究也为开发更符合人类视觉特性的新型视觉模型提供了新的思路。
📄 摘要(原文)
Despite their impressive performance on computer vision benchmarks, Deep Neural Networks (DNNs) still fall short of adequately modeling human visual behavior, as measured by error consistency and shape bias. Recent work hypothesized that behavioral alignment can be drastically improved through \emph{generative} -- rather than \emph{discriminative} -- classifiers, with far-reaching implications for models of human vision. Here, we instead show that the increased alignment of generative models can be largely explained by a seemingly innocuous resizing operation in the generative model which effectively acts as a low-pass filter. In a series of controlled experiments, we show that removing high-frequency spatial information from discriminative models like CLIP drastically increases their behavioral alignment. Simply blurring images at test-time -- rather than training on blurred images -- achieves a new state-of-the-art score on the model-vs-human benchmark, halving the current alignment gap between DNNs and human observers. Furthermore, low-pass filters are likely optimal, which we demonstrate by directly optimizing filters for alignment. To contextualize the performance of optimal filters, we compute the frontier of all possible pareto-optimal solutions to the benchmark, which was formerly unknown. We explain our findings by observing that the frequency spectrum of optimal Gaussian filters roughly matches the spectrum of band-pass filters implemented by the human visual system. We show that the contrast sensitivity function, describing the inverse of the contrast threshold required for humans to detect a sinusoidal grating as a function of spatiotemporal frequency, is approximated well by Gaussian filters of the specific width that also maximizes error consistency.