VAR-3D: View-aware Auto-Regressive Model for Text-to-3D Generation via a 3D Tokenizer
作者: Zongcheng Han, Dongyan Cao, Haoran Sun, Yu Hong
分类: cs.CV, cs.LG
发布日期: 2026-02-14
💡 一句话要点
提出VAR-3D模型,通过视角感知自回归方法提升文本到3D生成的质量和一致性
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 文本到3D生成 3D建模 自回归模型 向量量化 变分自编码器
📋 核心要点
- 现有文本到3D生成方法在学习离散3D表示时存在信息损失和几何一致性问题。
- VAR-3D通过视角感知的VQ-VAE将3D模型转换为离散token,并结合渲染监督训练。
- 实验表明,VAR-3D在生成质量和文本-3D对齐方面显著优于现有方法。
📝 摘要(中文)
本文提出了一种视角感知的自回归3D模型(VAR-3D),旨在解决文本到3D生成中的挑战。现有方法在学习离散3D表示时存在瓶颈,编码过程中容易丢失信息,导致量化前出现表示失真,向量量化进一步加剧了这个问题,最终降低了文本条件下的3D形状的几何一致性。此外,传统的两阶段训练范式导致了重建和文本条件自回归生成之间的目标不匹配。为了解决这些问题,VAR-3D集成了一个视角感知的3D向量量化变分自编码器(VQ-VAE),将复杂的3D模型几何结构转换为离散token。同时,引入了一种渲染监督训练策略,将离散token预测与视觉重建相结合,鼓励生成过程更好地保持视觉保真度和结构一致性,从而更好地与输入文本对齐。实验结果表明,VAR-3D在生成质量和文本-3D对齐方面均显著优于现有方法。
🔬 方法详解
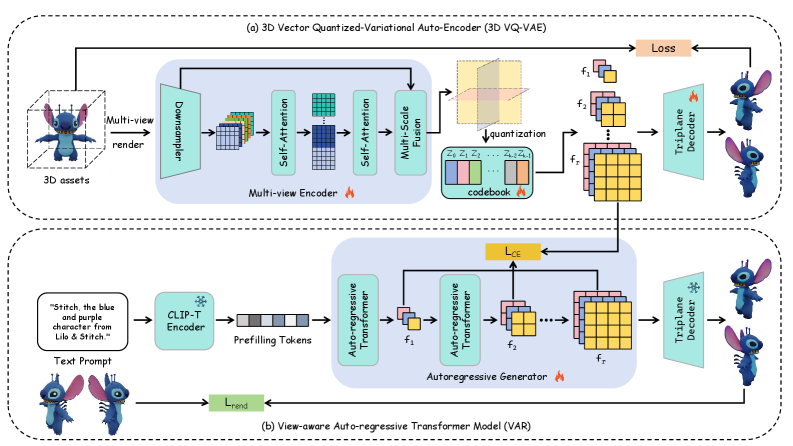
问题定义:文本到3D生成旨在根据给定的文本描述生成对应的3D模型。现有方法的主要痛点在于:1)3D表示学习过程中存在信息损失,导致几何结构失真;2)两阶段训练范式(先重建,后生成)导致目标不匹配,影响生成质量。
核心思路:VAR-3D的核心思路是利用视角感知的VQ-VAE将连续的3D几何结构转换为离散的token表示,从而简化生成过程。同时,通过渲染监督训练,将离散token预测与视觉重建相结合,确保生成结果在视觉上与输入文本描述一致。这样设计的目的是为了解决现有方法中存在的表示失真和目标不匹配问题。
技术框架:VAR-3D的整体框架包含两个主要模块:1)视角感知的3D VQ-VAE:负责将3D模型编码为离散token,并从token重建3D模型;2)自回归Transformer:基于文本描述,自回归地生成3D token序列。训练过程采用渲染监督策略,即在预测token的同时,利用渲染图像与真实图像之间的差异来指导token的生成。
关键创新:VAR-3D的关键创新点在于:1)视角感知的3D VQ-VAE:通过考虑不同视角的几何信息,提升3D表示的质量;2)渲染监督训练:将离散token预测与视觉重建相结合,弥合了重建和生成之间的差距,提升了生成结果的视觉保真度。与现有方法的本质区别在于,VAR-3D更加注重3D表示的质量和生成过程的视觉一致性。
关键设计:在视角感知的3D VQ-VAE中,使用了多视角渲染图像作为输入,并设计了专门的网络结构来处理不同视角的几何信息。渲染监督训练中,使用了L1损失和感知损失来衡量渲染图像与真实图像之间的差异。自回归Transformer采用了标准的Transformer结构,并针对3D token序列的特点进行了优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VAR-3D在ShapeNet数据集上取得了显著的性能提升。与现有方法相比,VAR-3D在生成质量和文本-3D对齐方面均有明显优势。具体而言,VAR-3D生成的3D模型在视觉保真度和结构一致性方面均优于现有方法,并且能够更好地与输入文本描述对齐。
🎯 应用场景
VAR-3D可应用于游戏开发、虚拟现实、产品设计等领域。例如,游戏开发者可以利用该模型快速生成符合特定描述的3D游戏资产;设计师可以根据文本描述快速生成产品原型。该研究的未来影响在于,它有望降低3D内容创作的门槛,促进3D技术的普及。
📄 摘要(原文)
Recent advances in auto-regressive transformers have achieved remarkable success in generative modeling. However, text-to-3D generation remains challenging, primarily due to bottlenecks in learning discrete 3D representations. Specifically, existing approaches often suffer from information loss during encoding, causing representational distortion before the quantization process. This effect is further amplified by vector quantization, ultimately degrading the geometric coherence of text-conditioned 3D shapes. Moreover, the conventional two-stage training paradigm induces an objective mismatch between reconstruction and text-conditioned auto-regressive generation. To address these issues, we propose View-aware Auto-Regressive 3D (VAR-3D), which intergrates a view-aware 3D Vector Quantized-Variational AutoEncoder (VQ-VAE) to convert the complex geometric structure of 3D models into discrete tokens. Additionally, we introduce a rendering-supervised training strategy that couples discrete token prediction with visual reconstruction, encouraging the generative process to better preserve visual fidelity and structural consistency relative to the input text. Experiments demonstrate that VAR-3D significantly outperforms existing methods in both generation quality and text-3D alignment.