Gaussian Sequences with Multi-Scale Dynamics for 4D Reconstruction from Monocular Casual Videos
作者: Can Li, Jie Gu, Jingmin Chen, Fangzhou Qiu, Lei Sun
分类: cs.CV, cs.RO
发布日期: 2026-02-14
💡 一句话要点
提出基于多尺度动态高斯序列的单目视频4D重建方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 4D重建 单目视频 动态场景 高斯序列 多尺度动态 新视角合成 机器人学习
📋 核心要点
- 单目视频4D重建具有高度不适定性,现有方法难以准确捕捉复杂动态场景。
- 论文提出多尺度动态机制,分解复杂运动场,并使用多尺度动态高斯序列进行表示。
- 实验表明,该方法在动态新视角合成任务上显著优于现有方法,重建效果更好。
📝 摘要(中文)
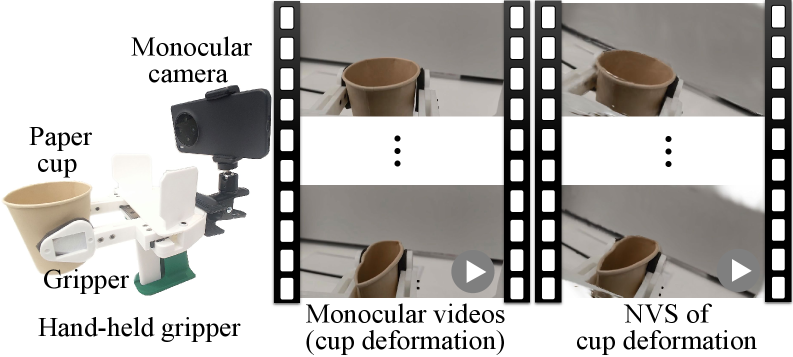
从日常视频中理解动态场景对于可扩展的机器人学习至关重要,然而,在严格的单目设置下进行四维(4D)重建仍然具有高度的不适定性。为了解决这个挑战,我们的关键见解是真实世界的动态呈现出从物体到粒子级别的多尺度规律性。为此,我们设计了多尺度动态机制,该机制分解了复杂的运动场。在此公式中,我们提出了具有多尺度动态的高斯序列,这是一种通过多层运动组合导出的动态3D高斯的新颖表示。这种分层结构大大减轻了重建的模糊性,并促进了物理上合理的动态。我们进一步结合了来自视觉基础模型的多模态先验来建立互补监督,约束了解空间并提高了重建保真度。我们的方法能够从单目日常视频中实现准确且全局一致的4D重建。在基准和真实世界操作数据集上的动态新视角合成(NVS)实验表明,与现有方法相比,有显著的改进。
🔬 方法详解
问题定义:论文旨在解决从单目日常视频中进行准确和全局一致的四维(4D)重建问题。现有的方法在处理动态场景时,由于单目视觉的固有歧义性以及复杂运动场建模的困难,往往难以获得高质量的重建结果,尤其是在缺乏先验知识的情况下。
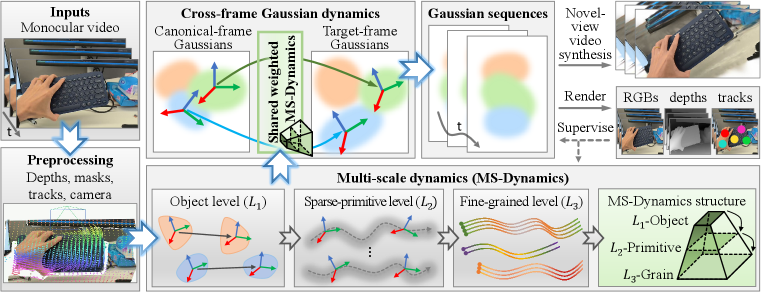
核心思路:论文的核心思路是利用真实世界动态的多尺度规律性。作者认为,从物体到粒子级别,动态场景呈现出不同尺度的运动模式。通过对复杂运动场进行分解,并利用多尺度动态高斯序列进行表示,可以有效地缓解重建的模糊性,并促进物理上合理的动态建模。此外,论文还引入了视觉基础模型的多模态先验作为互补监督,进一步约束解空间。
技术框架:该方法主要包含以下几个阶段:1) 多尺度动态机制:用于分解复杂的运动场,提取不同尺度的运动信息。2) 多尺度动态高斯序列表示:利用分解后的运动信息,构建动态3D高斯序列,用于表示动态场景。3) 多模态先验监督:引入视觉基础模型提供的先验知识,对重建过程进行约束。4) 优化与渲染:通过优化高斯参数,并使用可微渲染技术,生成最终的4D重建结果。
关键创新:该方法最重要的技术创新点在于提出了多尺度动态高斯序列表示。与传统的静态3D高斯表示相比,该方法能够显式地建模动态场景中的运动信息,从而更好地处理复杂运动。此外,多尺度动态机制的引入,使得模型能够捕捉不同尺度的运动模式,进一步提高了重建的准确性。
关键设计:论文中关键的设计包括:1) 多尺度动态机制的具体实现方式,例如如何选择合适的尺度分解方法。2) 多尺度动态高斯序列的参数化方式,例如如何表示每个高斯粒子的运动状态。3) 多模态先验监督的具体形式,例如如何利用视觉基础模型提取特征,并将其融入到损失函数中。4) 损失函数的设计,例如如何平衡重建误差、运动平滑性以及先验约束。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在动态新视角合成任务上取得了显著的提升。在基准数据集上,该方法在PSNR、SSIM等指标上均优于现有方法。在真实世界操作数据集上,该方法也能够生成更清晰、更逼真的动态场景,证明了其在实际应用中的潜力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实/增强现实等领域。例如,机器人可以利用该技术理解周围动态环境,从而做出更合理的决策。在自动驾驶领域,该技术可以帮助车辆更好地感知和预测其他车辆和行人的运动轨迹。在VR/AR领域,该技术可以创建更逼真的动态场景,提升用户体验。
📄 摘要(原文)
Understanding dynamic scenes from casual videos is critical for scalable robot learning, yet four-dimensional (4D) reconstruction under strictly monocular settings remains highly ill-posed. To address this challenge, our key insight is that real-world dynamics exhibits a multi-scale regularity from object to particle level. To this end, we design the multi-scale dynamics mechanism that factorizes complex motion fields. Within this formulation, we propose Gaussian sequences with multi-scale dynamics, a novel representation for dynamic 3D Gaussians derived through compositions of multi-level motion. This layered structure substantially alleviates ambiguity of reconstruction and promotes physically plausible dynamics. We further incorporate multi-modal priors from vision foundation models to establish complementary supervision, constraining the solution space and improving the reconstruction fidelity. Our approach enables accurate and globally consistent 4D reconstruction from monocular casual videos. Experiments of dynamic novel-view synthesis (NVS) on benchmark and real-world manipulation datasets demonstrate considerable improvements over existing methods.