T2MBench: A Benchmark for Out-of-Distribution Text-to-Motion Generation
作者: Bin Yang, Rong Ou, Weisheng Xu, Jiaqi Xiong, Xintao Li, Taowen Wang, Luyu Zhu, Xu Jiang, Jing Tan, Renjing Xu
分类: cs.CV
发布日期: 2026-02-14
💡 一句话要点
提出T2MBench基准,用于评估文本到动作生成模型在分布外场景的泛化能力
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 文本到动作生成 分布外泛化 基准测试 动作评估 自然语言处理
📋 核心要点
- 现有文本到动作生成评估缺乏对分布外文本输入的系统性评估,限制了模型泛化能力的衡量。
- 构建OOD提示数据集,并提出统一的评估框架,包含LLM评估、多因素动作评估和细粒度准确性评估。
- 实验表明现有模型在细粒度准确性方面表现不足,为未来模型设计和评估提供了指导。
📝 摘要(中文)
现有的文本到动作生成评估主要集中在分布内文本输入和有限的评估标准上,这限制了它们系统地评估模型在复杂分布外(OOD)文本条件下的泛化和动作生成能力。为了解决这个局限性,我们提出了一个专门为OOD文本到动作评估设计的基准,其中包括对14个代表性基线模型的全面分析以及从评估结果中得出的两个数据集。具体来说,我们构建了一个包含1025个文本描述的OOD提示数据集。基于此提示数据集,我们引入了一个统一的评估框架,该框架集成了基于LLM的评估、多因素动作评估和细粒度准确性评估。我们的实验结果表明,虽然不同的基线模型在文本到动作的语义对齐、动作泛化和物理质量等领域表现出优势,但大多数模型在细粒度准确性评估方面难以取得强大的性能。这些发现突出了现有方法在OOD场景中的局限性,并为未来生产级文本到动作模型的设计和评估提供了实践指导。
🔬 方法详解
问题定义:现有文本到动作生成模型评估主要集中在分布内数据,缺乏对模型在分布外(OOD)数据上的泛化能力的有效评估。这使得我们难以了解模型在面对真实世界复杂文本描述时的性能表现,阻碍了模型的进一步优化和实际应用。现有评估指标也较为单一,无法全面衡量生成动作的质量。
核心思路:为了解决上述问题,论文提出了一个专门针对OOD文本到动作生成的基准测试T2MBench。核心思路是构建一个包含多样化OOD文本描述的数据集,并设计一个综合性的评估框架,从多个维度评估生成动作的质量,从而更全面地了解模型的性能。
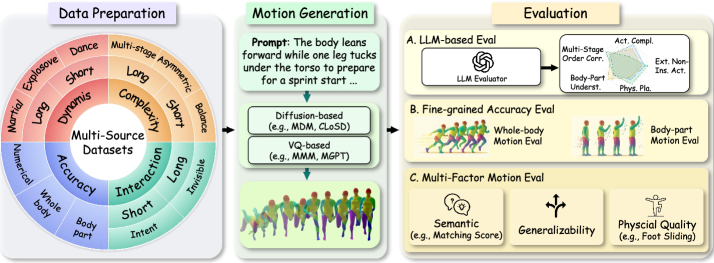
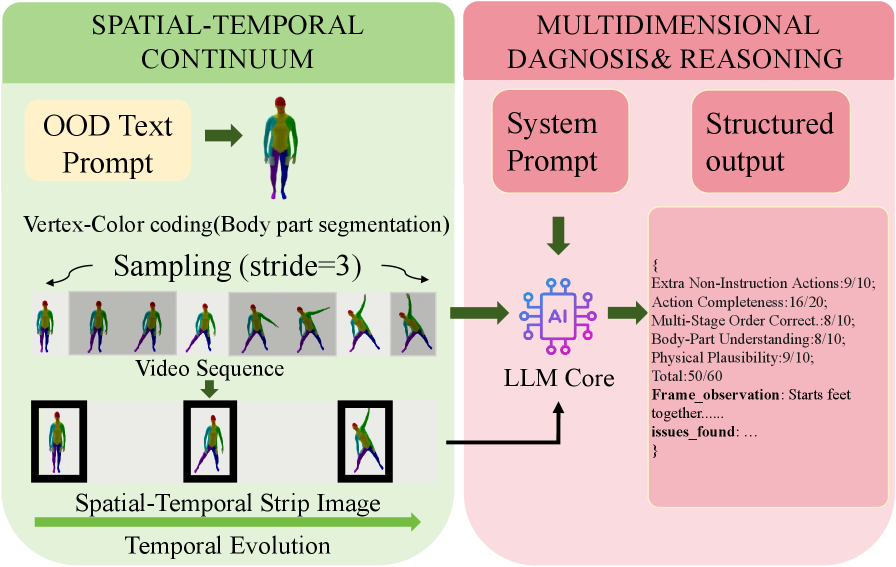
技术框架:T2MBench包含以下几个主要组成部分: 1. OOD提示数据集:包含1025个文本描述,旨在覆盖各种OOD场景。 2. 统一评估框架:包含三个主要模块: a. 基于LLM的评估:利用大型语言模型评估文本和生成动作之间的语义一致性。 b. 多因素动作评估:从动作的自然性、多样性、物理合理性等多个方面进行评估。 c. 细粒度准确性评估:评估生成动作在细节上的准确性,例如动作的时序、幅度等。 3. 基线模型评估:对14个代表性的文本到动作生成模型进行评估,并分析它们的优缺点。
关键创新:T2MBench的关键创新在于其针对OOD场景的设计和综合性的评估框架。与以往的评估方法相比,T2MBench更关注模型在面对未知文本描述时的泛化能力,并从多个维度评估生成动作的质量,从而更全面地了解模型的性能。
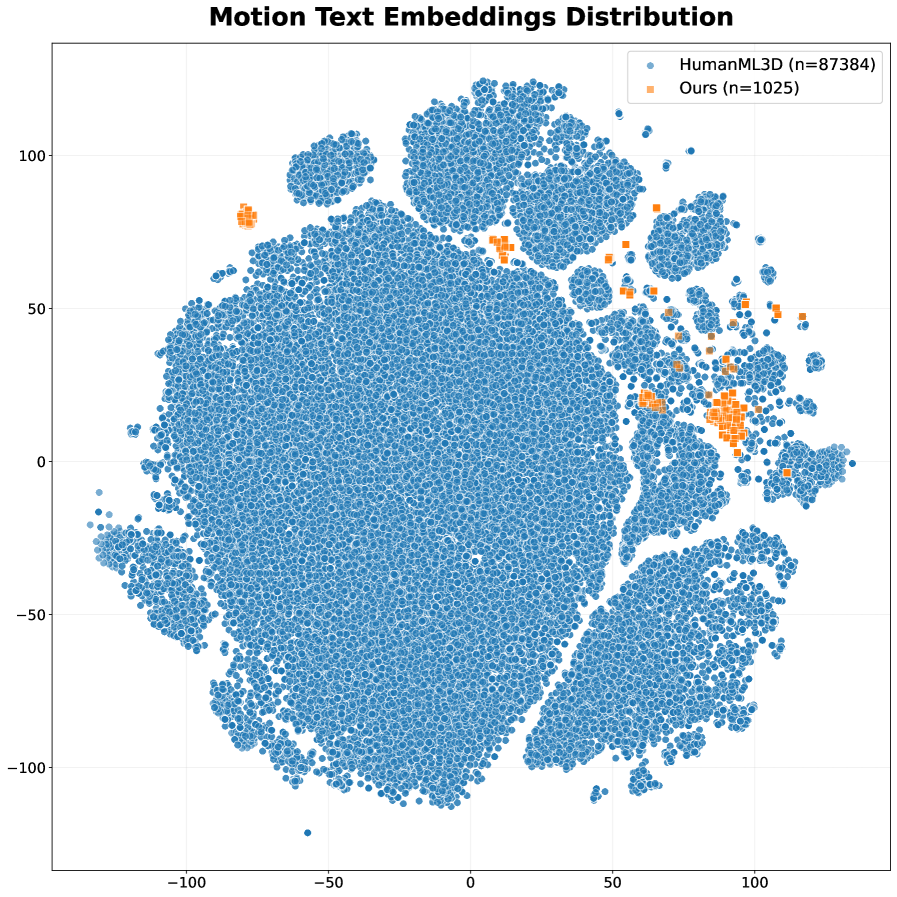
关键设计:OOD提示数据集的设计考虑了多种OOD场景,例如长文本描述、复杂场景描述、罕见动作描述等。评估框架中的多因素动作评估和细粒度准确性评估采用了多种指标,例如FID、Diversity、动作幅度误差等。基于LLM的评估则利用了预训练语言模型的强大语义理解能力,从而更准确地评估文本和动作之间的语义一致性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有文本到动作生成模型在T2MBench基准上表现不佳,尤其是在细粒度准确性评估方面。例如,大多数模型在生成具有精确时序和幅度的动作时存在困难。这些结果揭示了现有方法在OOD场景中的局限性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于动画制作、游戏开发、虚拟现实等领域。通过提高文本到动作生成模型的泛化能力,可以更方便地根据文本描述生成高质量的动作,从而降低人工成本,提高创作效率。未来,该研究还可以促进人机交互的发展,例如,用户可以通过自然语言指令控制机器人执行各种复杂动作。
📄 摘要(原文)
Most existing evaluations of text-to-motion generation focus on in-distribution textual inputs and a limited set of evaluation criteria, which restricts their ability to systematically assess model generalization and motion generation capabilities under complex out-of-distribution (OOD) textual conditions. To address this limitation, we propose a benchmark specifically designed for OOD text-to-motion evaluation, which includes a comprehensive analysis of 14 representative baseline models and the two datasets derived from evaluation results. Specifically, we construct an OOD prompt dataset consisting of 1,025 textual descriptions. Based on this prompt dataset, we introduce a unified evaluation framework that integrates LLM-based Evaluation, Multi-factor Motion evaluation, and Fine-grained Accuracy Evaluation. Our experimental results reveal that while different baseline models demonstrate strengths in areas such as text-to-motion semantic alignment, motion generalizability, and physical quality, most models struggle to achieve strong performance with Fine-grained Accuracy Evaluation. These findings highlight the limitations of existing methods in OOD scenarios and offer practical guidance for the design and evaluation of future production-level text-to-motion models.