EchoTorrent: Towards Swift, Sustained, and Streaming Multi-Modal Video Generation
作者: Rang Meng, Weipeng Wu, Yingjie Yin, Yuming Li, Chenguang Ma
分类: cs.CV
发布日期: 2026-02-14
💡 一句话要点
EchoTorrent:面向快速、稳定和流式多模态视频生成的新框架
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态视频生成 流式推理 知识蒸馏 时间一致性 音频-唇音同步 扩散模型 长序列建模
📋 核心要点
- 现有方法在多模态视频生成中存在延迟高、时间稳定性差的问题,难以满足实时流式应用的需求。
- EchoTorrent通过多教师训练、自适应CFG校准、混合长尾强制和VAE解码器精炼等技术,提升生成视频的质量和效率。
- 实验结果表明,EchoTorrent在时间一致性、身份保持和音频-唇音同步方面均有显著提升,实现了高质量的流式视频生成。
📝 摘要(中文)
近期的多模态视频生成模型在视觉质量上取得了显著进展,但其过高的延迟和有限的时间稳定性阻碍了实时部署。流式推理进一步加剧了这些问题,导致显著的多模态退化,例如空间模糊、时间漂移和唇音不同步,从而造成了效率与性能之间无法解决的权衡。为此,我们提出了EchoTorrent,一种新颖的架构,包含四个方面的设计:(1)多教师训练,在不同的偏好领域上微调预训练模型,以获得专门的领域专家,这些专家依次将领域特定的知识转移给学生模型;(2)自适应CFG校准(ACC-DMD),通过分阶段的时空调度来校准DMD中的音频CFG增强误差,消除冗余的CFG计算,并实现每步单次推理;(3)混合长尾强制,通过因果-双向混合架构,在长时程自rollout训练期间仅在尾部帧上强制对齐,有效地缓解了流式模式下的时空退化,同时提高了对参考帧的保真度;(4)VAE解码器精炼器,通过VAE解码器的像素域优化来恢复高频细节,同时避免潜在空间模糊。大量的实验和分析表明,EchoTorrent实现了少量迭代的自回归生成,并具有显著扩展的时间一致性、身份保持和音频-唇音同步。
🔬 方法详解
问题定义:论文旨在解决多模态视频生成中,尤其是在流式推理场景下,生成视频的延迟高、时间一致性差、身份保持不佳以及音频-唇音同步困难等问题。现有方法在追求视觉质量的同时,往往忽略了效率,导致无法满足实时应用的需求。
核心思路:EchoTorrent的核心思路是通过多方面的优化,在保证生成视频质量的前提下,显著降低延迟并提升时间稳定性。具体而言,通过知识蒸馏加速推理,通过自适应校准减少计算冗余,通过混合强制提升长时依赖,并通过像素域优化增强细节。
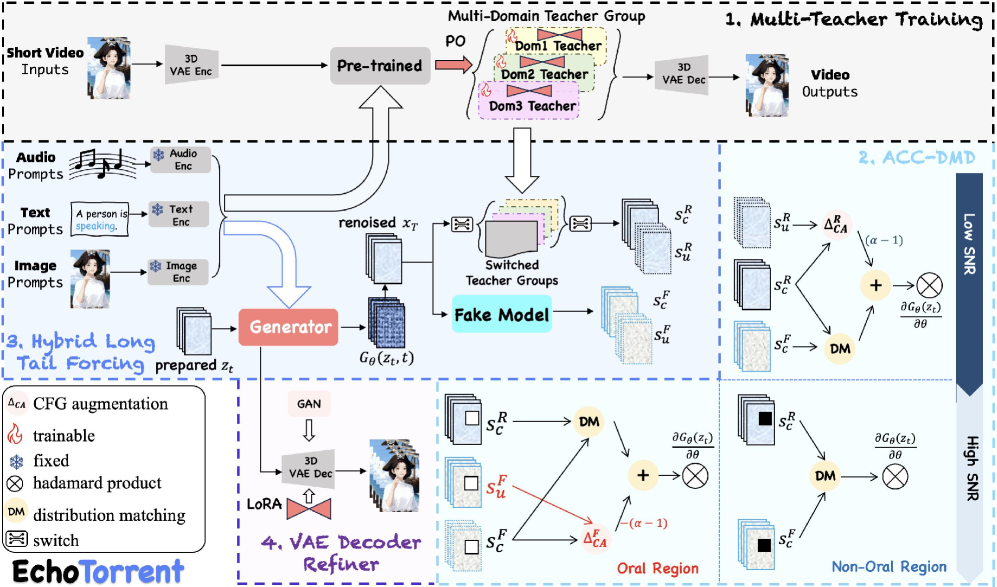
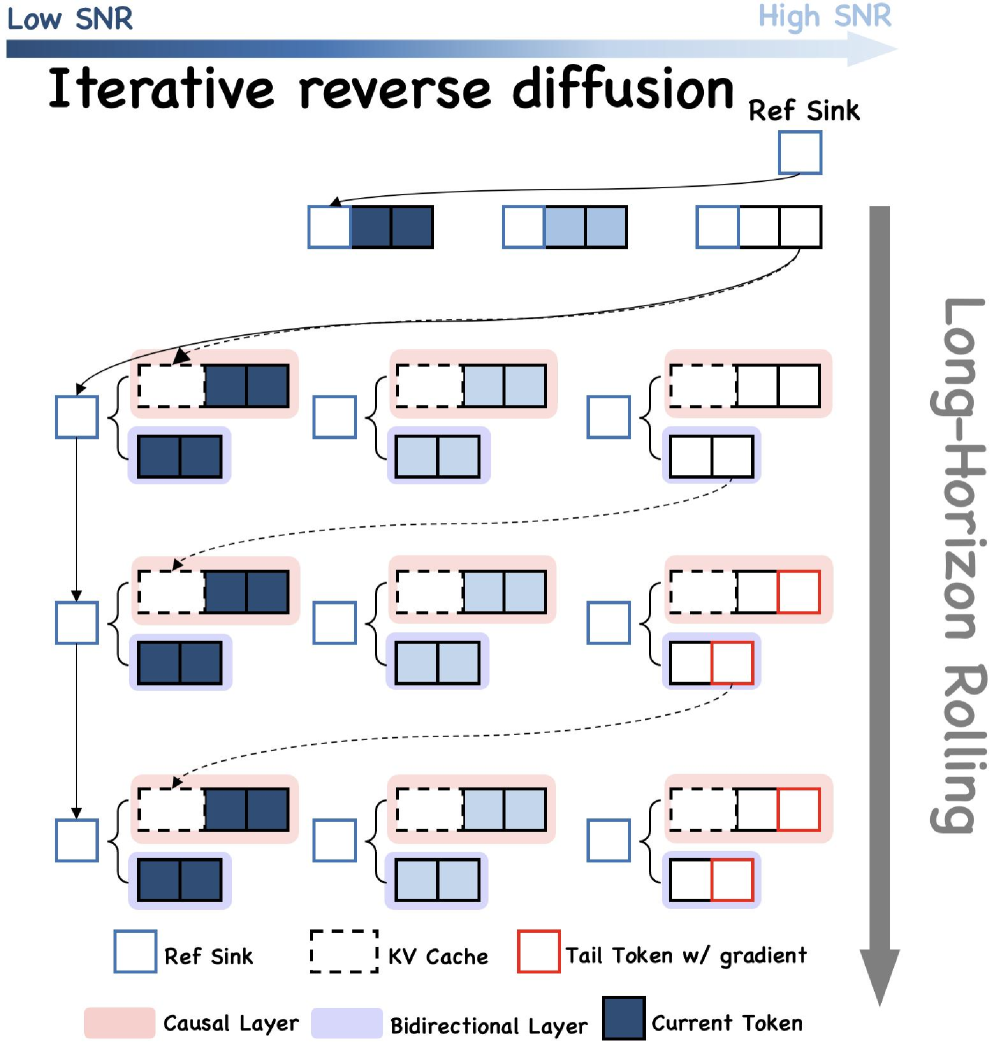
技术框架:EchoTorrent的整体框架包含四个主要模块:(1) 多教师训练:利用多个在不同领域微调的专家模型,通过知识蒸馏提升学生模型的性能。(2) 自适应CFG校准 (ACC-DMD):针对扩散模型中的音频条件增强误差进行校准,减少计算量。(3) 混合长尾强制:在训练过程中,对长序列的尾部帧进行强制对齐,提升时间一致性。(4) VAE解码器精炼器:通过像素域优化,恢复生成视频的高频细节。
关键创新:EchoTorrent的关键创新在于其综合性的优化策略,它不仅仅关注单一方面的性能提升,而是通过多模块协同工作,实现了在延迟、时间稳定性、身份保持和音频-唇音同步等多个方面的平衡。自适应CFG校准和混合长尾强制是两个较为突出的创新点,前者减少了计算冗余,后者提升了长时依赖建模能力。
关键设计:多教师训练中,教师模型的选择和知识蒸馏策略至关重要。自适应CFG校准中,时空调度的设计需要仔细考虑。混合长尾强制中,因果-双向混合架构的设计能够有效利用上下文信息。VAE解码器精炼器中,损失函数的选择和优化策略直接影响细节恢复的效果。具体的参数设置和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
EchoTorrent在实验中表现出显著的性能提升,实现了更长的时间一致性、更好的身份保持和更准确的音频-唇音同步。具体的性能数据,例如延迟降低的百分比、时间一致性指标的提升幅度等,需要在论文中查找(未知)。与现有基线方法相比,EchoTorrent在多个指标上均取得了显著的优势。
🎯 应用场景
EchoTorrent在实时视频会议、虚拟主播、AI内容创作等领域具有广泛的应用前景。它可以用于生成高质量、低延迟的虚拟形象,提升用户体验。此外,该技术还可以应用于视频修复、视频增强等领域,具有重要的实际价值和商业潜力。
📄 摘要(原文)
Recent multi-modal video generation models have achieved high visual quality, but their prohibitive latency and limited temporal stability hinder real-time deployment. Streaming inference exacerbates these issues, leading to pronounced multimodal degradation, such as spatial blurring, temporal drift, and lip desynchronization, which creates an unresolved efficiency-performance trade-off. To this end, we propose EchoTorrent, a novel schema with a fourfold design: (1) Multi-Teacher Training fine-tunes a pre-trained model on distinct preference domains to obtain specialized domain experts, which sequentially transfer domain-specific knowledge to a student model; (2) Adaptive CFG Calibration (ACC-DMD), which calibrates the audio CFG augmentation errors in DMD via a phased spatiotemporal schedule, eliminating redundant CFG computations and enabling single-pass inference per step; (3) Hybrid Long Tail Forcing, which enforces alignment exclusively on tail frames during long-horizon self-rollout training via a causal-bidirectional hybrid architecture, effectively mitigates spatiotemporal degradation in streaming mode while enhancing fidelity to reference frames; and (4) VAE Decoder Refiner through pixel-domain optimization of the VAE decoder to recover high-frequency details while circumventing latent-space ambiguities. Extensive experiments and analysis demonstrate that EchoTorrent achieves few-pass autoregressive generation with substantially extended temporal consistency, identity preservation, and audio-lip synchronization.