LeafNet: A Large-Scale Dataset and Comprehensive Benchmark for Foundational Vision-Language Understanding of Plant Diseases
作者: Khang Nguyen Quoc, Phuong D. Dao, Luyl-Da Quach
分类: cs.CV, cs.AI
发布日期: 2026-02-14 (更新: 2026-02-20)
备注: 26 pages, 13 figures and 8 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出LeafNet大规模植物病害视觉-语言数据集与LeafBench基准,促进农业领域多模态理解。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 植物病害诊断 视觉-语言模型 多模态学习 农业应用 数据集 基准测试 深度学习
📋 核心要点
- 现有视觉-语言模型在植物病理学等特定农业领域的应用受限于缺乏大规模、全面的多模态数据集和基准。
- 构建LeafNet数据集和LeafBench基准,包含植物叶片图像、疾病信息和问答对,用于评估和提升VLMs在植物病害理解方面的能力。
- 实验表明,微调的VLMs在植物病害诊断方面优于传统视觉模型,但细粒度识别仍有提升空间,LeafBench可促进相关研究。
📝 摘要(中文)
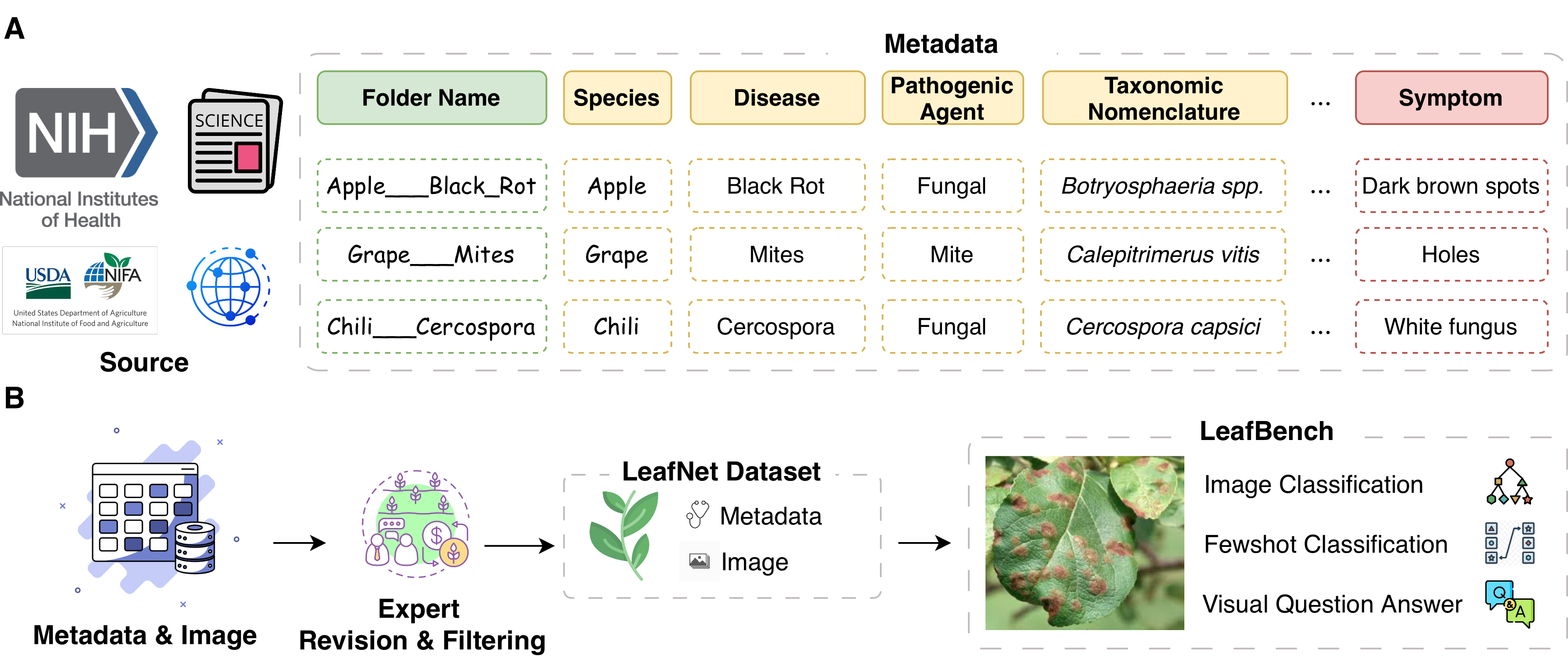
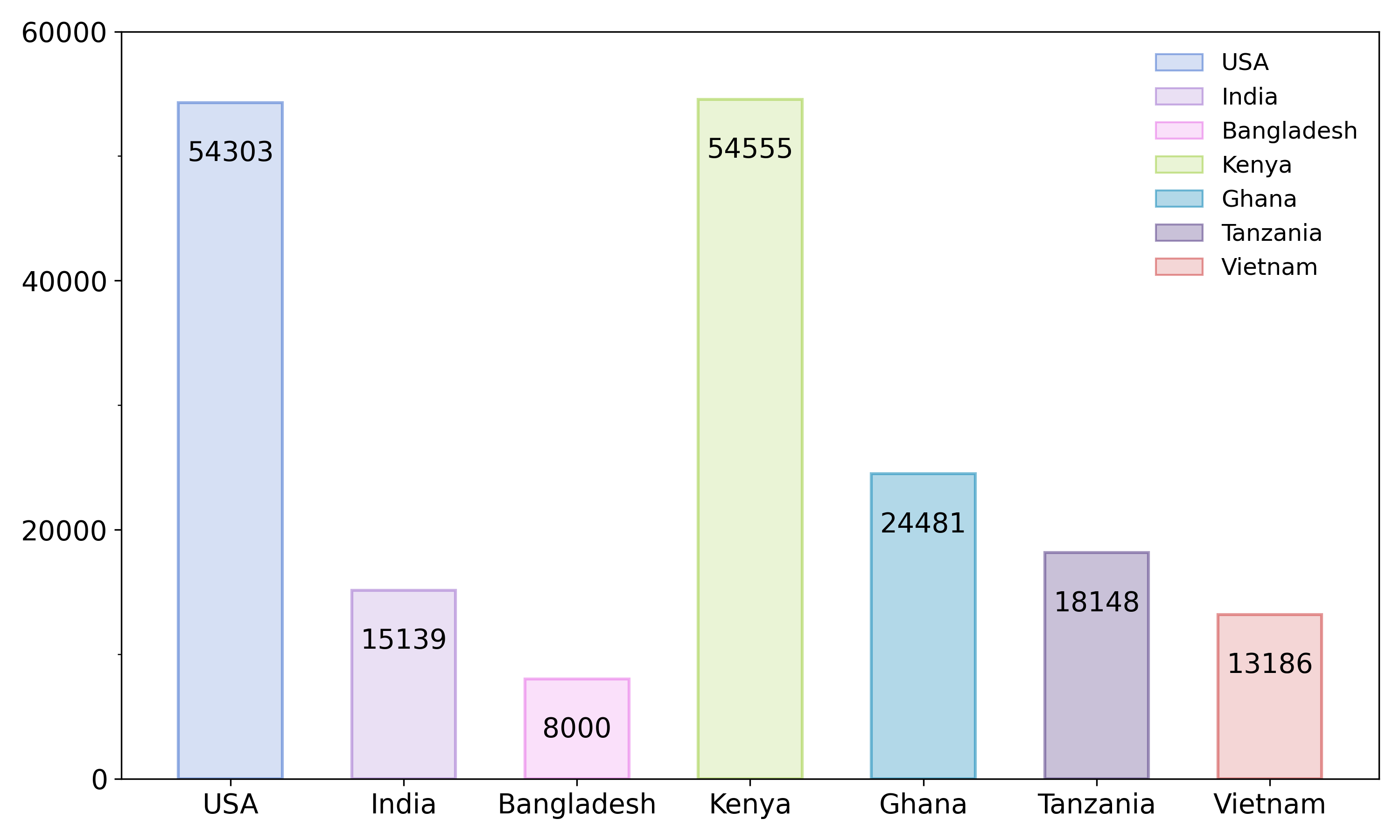
本文提出了LeafNet,一个全面的多模态数据集,以及LeafBench,一个视觉问答基准,旨在系统地评估视觉-语言模型(VLMs)在理解植物病害方面的能力。LeafNet包含186,000张叶片数字图像,涵盖97种疾病类别,并配有元数据,生成了13,950个问答对,涵盖六个关键农业任务。这些问题评估了植物病理学理解的各个方面,包括视觉症状识别、分类关系和诊断推理。在LeafBench上对12个最先进的VLMs进行基准测试,揭示了它们在疾病理解能力方面的显著差异。研究表明,性能因任务而异:二元健康/患病分类的准确率超过90%,而细粒度的病原体和物种识别的准确率低于65%。视觉模型和VLMs之间的直接比较证明了多模态架构的关键优势:微调的VLMs优于传统的视觉模型,证实了整合语言表示可以显著提高诊断精度。这些发现突出了当前VLMs在植物病理学应用中的关键差距,并强调了LeafBench作为可靠的AI辅助植物病害诊断方法进步评估框架的必要性。
🔬 方法详解
问题定义:现有视觉-语言模型(VLMs)在通用领域取得了显著进展,但在植物病理学等特定农业领域的应用仍然受限。主要痛点在于缺乏大规模、高质量、涵盖多种疾病类型和诊断任务的多模态数据集,以及相应的评估基准,难以有效训练和评估VLMs在植物病害理解方面的能力。
核心思路:本文的核心思路是构建一个大规模的植物病害多模态数据集LeafNet,并基于此设计一个视觉问答基准LeafBench。通过提供丰富的图像-文本数据和多样化的诊断任务,旨在促进VLMs在植物病害识别、诊断和推理方面的研究,并为模型性能评估提供标准化的平台。
技术框架:LeafNet数据集包含186,000张叶片图像,涵盖97种疾病类别,并配有元数据。LeafBench基准基于LeafNet数据集构建,包含13,950个问答对,涵盖六个关键农业任务,包括视觉症状识别、分类关系和诊断推理。研究人员可以使用LeafBench对VLMs进行评估,并根据评估结果改进模型。
关键创新:该研究的关键创新在于构建了一个大规模、全面的植物病害多模态数据集LeafNet,并基于此设计了一个视觉问答基准LeafBench。与现有数据集相比,LeafNet涵盖了更多的疾病类别,并提供了更丰富的元数据和问答对,能够更全面地评估VLMs在植物病害理解方面的能力。
关键设计:LeafBench中的问答对设计涵盖了六个关键农业任务,包括:1) 二元健康/患病分类;2) 病害类型识别;3) 病原体识别;4) 植物物种识别;5) 病害严重程度评估;6) 治疗方案推荐。这些任务的设计旨在全面评估VLMs在植物病害诊断和推理方面的能力。实验中,作者使用了12个最先进的VLMs进行基准测试,并分析了它们在不同任务上的性能表现。
🖼️ 关键图片

📊 实验亮点
在LeafBench基准测试中,微调的VLMs在植物病害诊断方面优于传统的视觉模型,证明了多模态信息融合的有效性。二元健康/患病分类的准确率超过90%,但细粒度的病原体和物种识别的准确率仍低于65%,表明现有VLMs在细粒度识别方面仍有提升空间。LeafBench为评估和改进VLMs在植物病害理解方面的能力提供了一个有价值的平台。
🎯 应用场景
该研究成果可应用于AI辅助的植物病害诊断系统,帮助农民和农业专家快速准确地识别植物病害,从而采取及时的防治措施,减少作物损失,提高农业生产效率。未来,该数据集和基准可以促进更先进的VLMs在农业领域的应用,例如智能农场管理、精准农业等。
📄 摘要(原文)
Foundation models and vision-language pre-training have significantly advanced Vision-Language Models (VLMs), enabling multimodal processing of visual and linguistic data. However, their application in domain-specific agricultural tasks, such as plant pathology, remains limited due to the lack of large-scale, comprehensive multimodal image--text datasets and benchmarks. To address this gap, we introduce LeafNet, a comprehensive multimodal dataset, and LeafBench, a visual question-answering benchmark developed to systematically evaluate the capabilities of VLMs in understanding plant diseases. The dataset comprises 186,000 leaf digital images spanning 97 disease classes, paired with metadata, generating 13,950 question-answer pairs spanning six critical agricultural tasks. The questions assess various aspects of plant pathology understanding, including visual symptom recognition, taxonomic relationships, and diagnostic reasoning. Benchmarking 12 state-of-the-art VLMs on our LeafBench dataset, we reveal substantial disparity in their disease understanding capabilities. Our study shows performance varies markedly across tasks: binary healthy--diseased classification exceeds 90% accuracy, while fine-grained pathogen and species identification remains below 65%. Direct comparison between vision-only models and VLMs demonstrates the critical advantage of multimodal architectures: fine-tuned VLMs outperform traditional vision models, confirming that integrating linguistic representations significantly enhances diagnostic precision. These findings highlight critical gaps in current VLMs for plant pathology applications and underscore the need for LeafBench as a rigorous framework for methodological advancement and progress evaluation toward reliable AI-assisted plant disease diagnosis. Code is available at https://github.com/EnalisUs/LeafBench.