A generalizable foundation model for intraoperative understanding across surgical procedures
作者: Kanggil Park, Yongjun Jeon, Soyoung Lim, Seonmin Park, Jongmin Shin, Jung Yong Kim, Sehyeon An, Jinsoo Rhu, Jongman Kim, Gyu-Seong Choi, Namkee Oh, Kyu-Hwan Jung
分类: cs.CV
发布日期: 2026-02-14
💡 一句话要点
ZEN:一种通用的术中理解基础模型,可跨多种外科手术泛化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手术视频理解 基础模型 自监督学习 多教师蒸馏 跨手术泛化 术中辅助 手术培训
📋 核心要点
- 现有的手术AI模型通常针对特定任务设计,缺乏跨手术和机构的泛化能力,限制了其应用。
- 论文提出ZEN,一种基于自监督多教师蒸馏框架训练的通用术中手术视频理解基础模型。
- 实验结果表明,ZEN在多个下游任务中优于现有模型,并展现出强大的跨手术泛化能力。
📝 摘要(中文)
在微创手术中,临床决策依赖于实时的视觉解读,但术中感知在不同外科医生和手术之间差异很大。这种可变性限制了一致的评估、培训和可靠的人工智能系统的开发,因为大多数外科人工智能模型都是为狭义定义的任务而设计的,并且不能跨手术或机构泛化。本文介绍ZEN,一种通用的术中手术视频理解基础模型,使用自监督多教师蒸馏框架,在来自超过21种手术的400多万帧图像上进行训练。我们策划了一个大型且多样化的数据集,并在统一的基准测试中系统地评估了多种表征学习策略。在20个下游任务以及完全微调、冻结骨干、少样本和零样本设置中,ZEN始终优于现有的外科基础模型,并展示了强大的跨手术泛化能力。这些结果表明朝着手术场景理解的统一表征迈出了一步,并支持术中辅助和手术培训评估的未来应用。
🔬 方法详解
问题定义:现有手术AI模型通常针对特定手术或任务设计,泛化能力差,无法适应不同手术场景和机构的需求。这限制了AI在术中辅助、手术培训等方面的应用。
核心思路:论文的核心思路是训练一个通用的手术视频理解基础模型,使其能够学习到与手术过程相关的通用视觉表征,从而可以泛化到不同的手术类型和任务中。通过自监督学习和多教师蒸馏,模型可以从大量未标注的手术视频数据中学习,并利用多个教师模型的知识来提高性能。
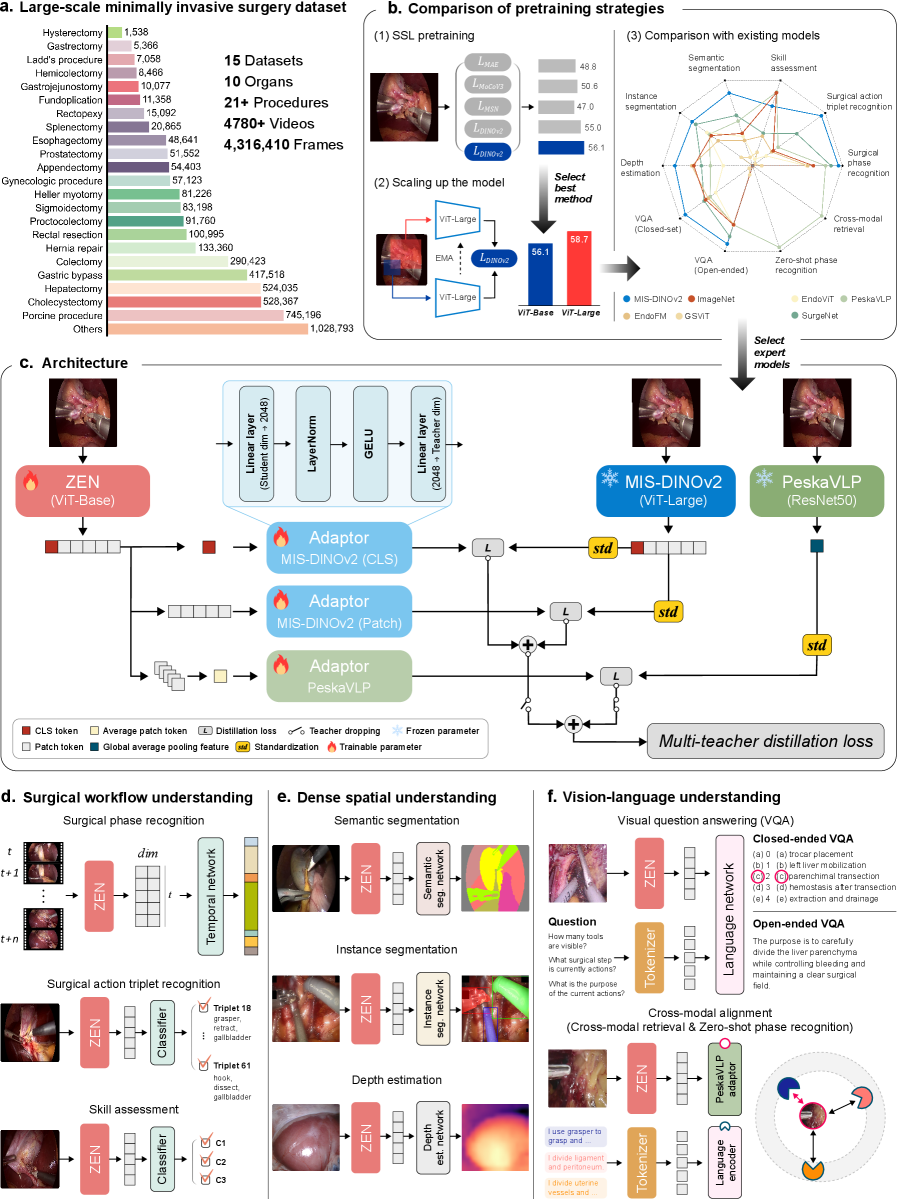
技术框架:ZEN的整体框架包括以下几个主要模块:1) 数据集构建:构建包含多种手术类型的大规模手术视频数据集。2) 自监督预训练:使用自监督学习方法(例如对比学习)在大量未标注数据上预训练模型,学习通用的视觉表征。3) 多教师蒸馏:利用多个预训练好的教师模型,将它们的知识蒸馏到学生模型中,提高学生模型的性能和泛化能力。4) 下游任务微调:在具体的下游任务上微调预训练好的模型,例如手术器械识别、手术步骤分割等。
关键创新:ZEN的关键创新在于:1) 提出了一个通用的手术视频理解基础模型,可以跨多种手术类型泛化。2) 使用自监督多教师蒸馏框架,有效地利用了大量未标注的手术视频数据和多个教师模型的知识。3) 构建了一个大规模且多样化的手术视频数据集,为模型的训练提供了充足的数据支持。
关键设计:在自监督预训练阶段,使用了对比学习损失函数,鼓励模型学习到对数据增强不变的表征。在多教师蒸馏阶段,使用了KL散度损失函数,衡量学生模型和教师模型输出之间的差异。网络结构方面,使用了Transformer作为主干网络,以捕捉手术视频中的时序信息。数据集包含了超过21种手术的400万帧图像。
🖼️ 关键图片
📊 实验亮点
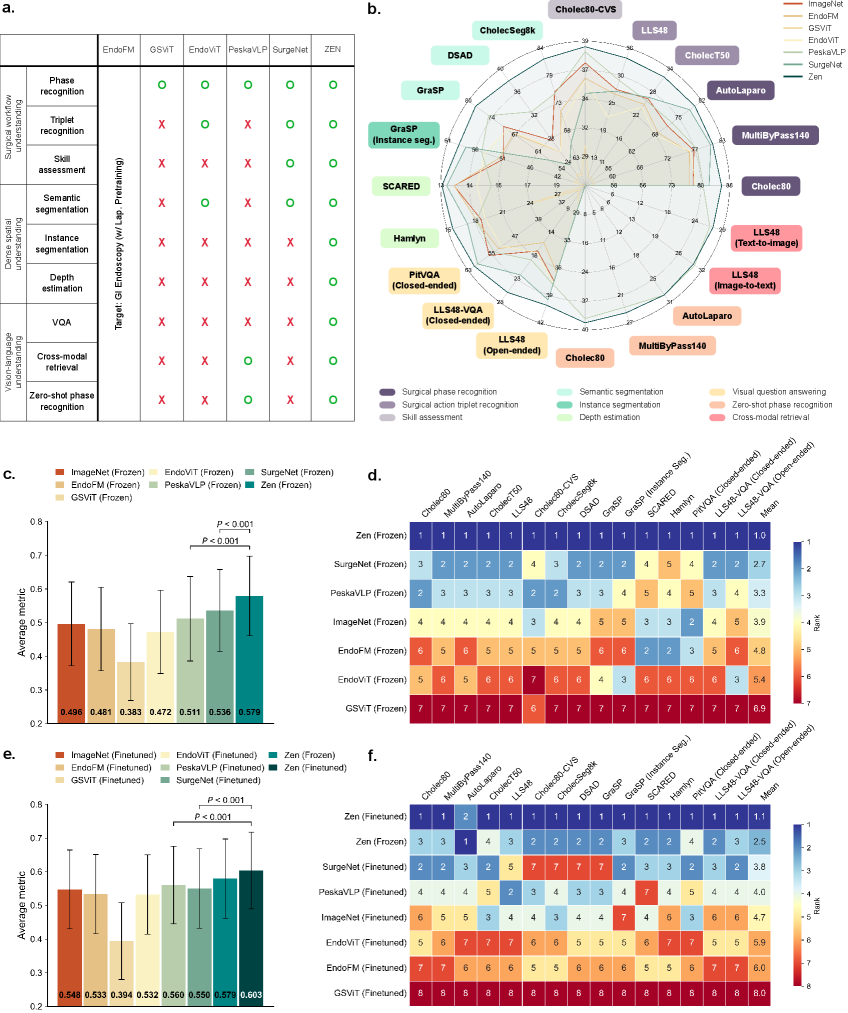
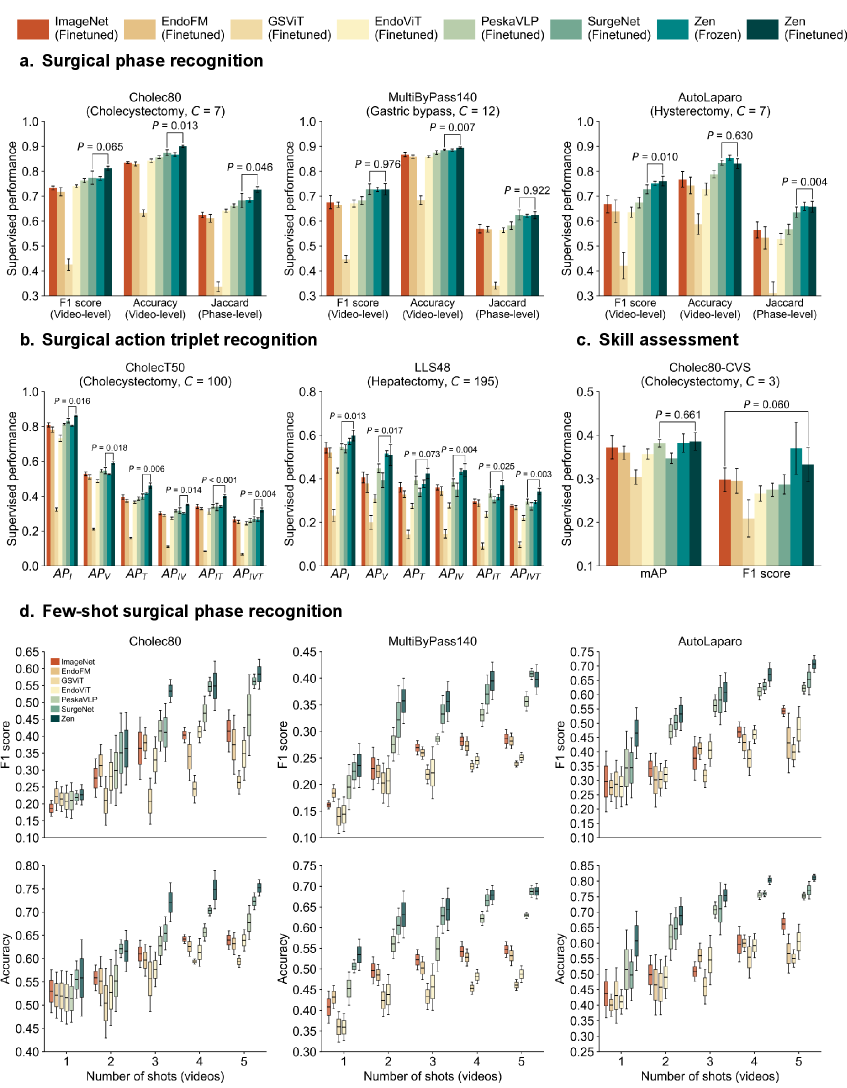
ZEN在20个下游任务中表现出色,包括全微调、冻结骨干、少样本和零样本设置。它始终优于现有的手术基础模型,并展示了强大的跨手术泛化能力。例如,在手术器械识别任务中,ZEN的性能显著优于其他模型,证明了其学习到的通用视觉表征的有效性。
🎯 应用场景
该研究成果可应用于术中辅助系统,例如实时手术器械识别、手术步骤导航等,从而提高手术效率和安全性。此外,该模型还可用于手术培训评估,为外科医生提供个性化的反馈和指导。未来,该模型有望成为构建智能化手术室的关键组成部分。
📄 摘要(原文)
In minimally invasive surgery, clinical decisions depend on real-time visual interpretation, yet intraoperative perception varies substantially across surgeons and procedures. This variability limits consistent assessment, training, and the development of reliable artificial intelligence systems, as most surgical AI models are designed for narrowly defined tasks and do not generalize across procedures or institutions. Here we introduce ZEN, a generalizable foundation model for intraoperative surgical video understanding trained on more than 4 million frames from over 21 procedures using a self-supervised multi-teacher distillation framework. We curated a large and diverse dataset and systematically evaluated multiple representation learning strategies within a unified benchmark. Across 20 downstream tasks and full fine-tuning, frozen-backbone, few-shot and zero-shot settings, ZEN consistently outperforms existing surgical foundation models and demonstrates robust cross-procedure generalization. These results suggest a step toward unified representations for surgical scene understanding and support future applications in intraoperative assistance and surgical training assessment.