Conversational Image Segmentation: Grounding Abstract Concepts with Scalable Supervision
作者: Aadarsh Sahoo, Georgia Gkioxari
分类: cs.CV
发布日期: 2026-02-13
备注: Project webpage: https://glab-caltech.github.io/converseg/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出ConverSeg数据集和ConverSeg-Net,解决会话图像分割中抽象概念的像素级定位问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 会话图像分割 语言引导分割 数据集构建 AI数据引擎 语义理解 物理推理 意图识别
📋 核心要点
- 现有语言引导的图像分割方法主要关注类别和空间关系,缺乏对意图、功能和物理推理的理解。
- 本文提出ConverSeg数据集和ConverSeg-Net模型,利用AI驱动的数据引擎生成大规模训练数据,提升模型对抽象概念的理解能力。
- 实验表明,ConverSeg-Net在新的ConverSeg数据集上取得了显著提升,并在现有数据集上保持了竞争力。
📝 摘要(中文)
本文提出会话图像分割(CIS)任务,旨在将抽象的、意图驱动的概念转化为像素级的精确掩码。现有工作主要关注类别和空间查询,忽略了功能和物理推理。为此,本文引入了ConverSeg基准,涵盖实体、空间关系、意图、可供性、功能、安全和物理推理等方面。同时,提出了ConverSeg-Net,它融合了强大的分割先验知识和语言理解能力。此外,还提出了一个AI驱动的数据引擎,无需人工监督即可生成提示-掩码对。实验表明,现有的语言引导分割模型不足以应对CIS任务,而使用本文数据引擎训练的ConverSeg-Net在ConverSeg上取得了显著的性能提升,并在现有的语言引导分割基准上保持了强大的性能。
🔬 方法详解
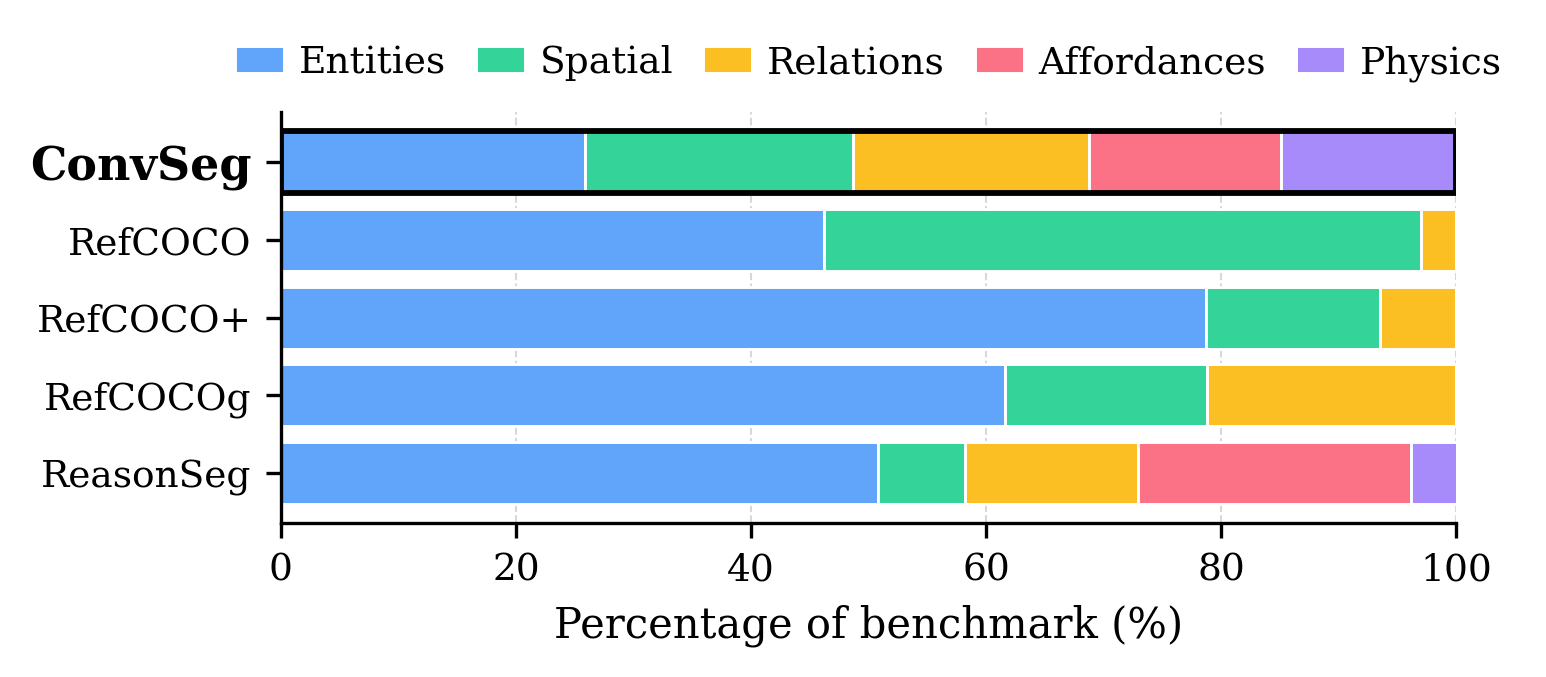
问题定义:现有语言引导的图像分割方法主要集中在基于类别和空间关系的查询,例如“最左边的苹果”。它们无法处理需要功能、意图、可供性、安全性和物理推理的复杂查询,例如“我应该把刀放在哪里才安全?”。这限制了它们在实际应用中的能力。
核心思路:本文的核心思路是构建一个包含丰富语义信息的数据集,并设计一个能够有效融合语言理解和图像分割的模型。通过大规模的数据训练,使模型能够理解抽象概念并将其转化为像素级别的分割掩码。
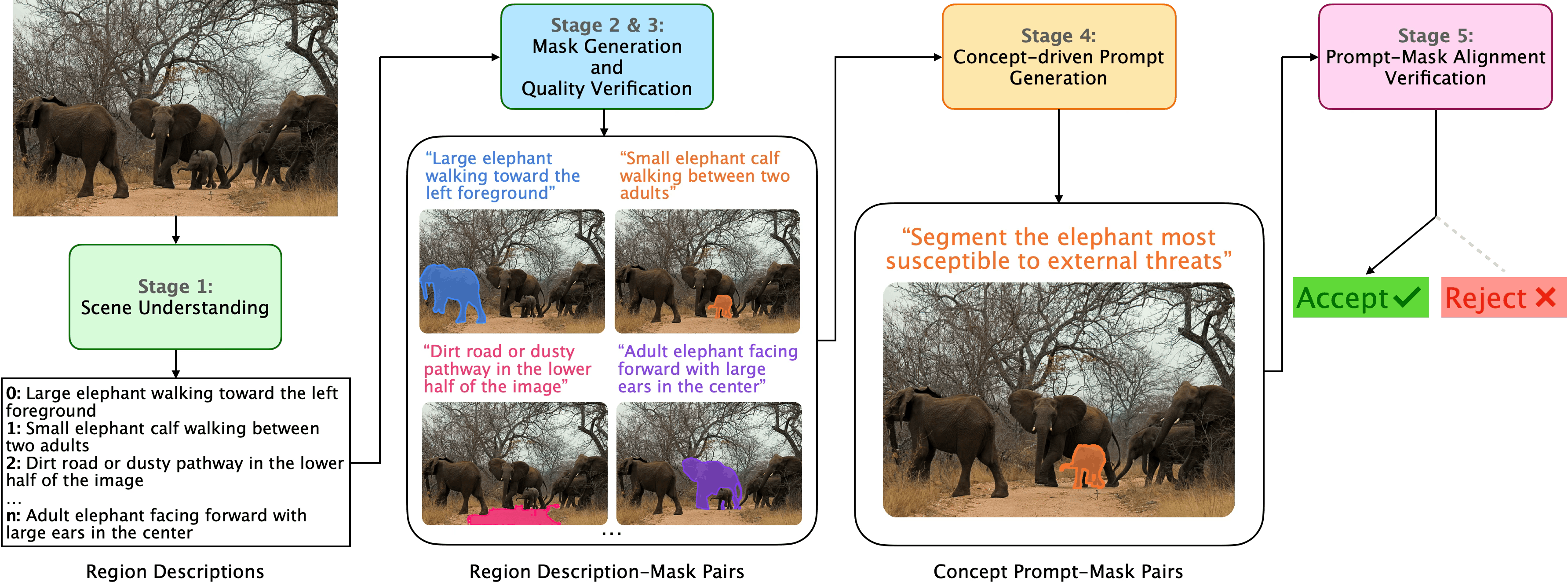
技术框架:ConverSeg-Net的整体架构包含两个主要部分:语言编码器和图像分割解码器。语言编码器负责将输入的文本提示转换为语义向量表示。图像分割解码器利用该语义向量,结合图像特征,生成像素级别的分割掩码。该框架还包含一个AI驱动的数据引擎,用于自动生成训练数据。
关键创新:本文的关键创新在于:1) 提出了一个新的会话图像分割任务和相应的ConverSeg数据集,该数据集包含更丰富的语义信息和更复杂的查询;2) 提出了一个AI驱动的数据引擎,可以自动生成大规模的训练数据,解决了数据标注的瓶颈问题;3) 设计了ConverSeg-Net,它能够有效融合语言理解和图像分割,从而更好地处理会话图像分割任务。
关键设计:ConverSeg-Net使用了预训练的语言模型(例如BERT)作为语言编码器,提取文本提示的语义特征。图像分割解码器可以采用不同的架构,例如Mask R-CNN或DeepLab。损失函数通常包括分割损失(例如交叉熵损失)和可选的对比学习损失,以提高模型对相似概念的区分能力。数据引擎使用程序化生成和规则来创建提示-掩码对,并使用过滤机制来保证数据的质量。
🖼️ 关键图片

📊 实验亮点
ConverSeg-Net在ConverSeg数据集上取得了显著的性能提升,相较于现有语言引导分割模型,在多个指标上均有大幅度提高。此外,ConverSeg-Net在现有的语言引导分割基准上,例如RefCOCO, RefCOCO+, G-Ref,也保持了具有竞争力的性能,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于智能家居、机器人导航、人机交互等领域。例如,机器人可以根据用户的自然语言指令,准确识别并分割图像中的目标物体,从而完成复杂的任务,如安全放置物品、寻找特定工具等。未来,该技术有望进一步提升机器人的智能化水平和服务能力。
📄 摘要(原文)
Conversational image segmentation grounds abstract, intent-driven concepts into pixel-accurate masks. Prior work on referring image grounding focuses on categorical and spatial queries (e.g., "left-most apple") and overlooks functional and physical reasoning (e.g., "where can I safely store the knife?"). We address this gap and introduce Conversational Image Segmentation (CIS) and ConverSeg, a benchmark spanning entities, spatial relations, intent, affordances, functions, safety, and physical reasoning. We also present ConverSeg-Net, which fuses strong segmentation priors with language understanding, and an AI-powered data engine that generates prompt-mask pairs without human supervision. We show that current language-guided segmentation models are inadequate for CIS, while ConverSeg-Net trained on our data engine achieves significant gains on ConverSeg and maintains strong performance on existing language-guided segmentation benchmarks. Project webpage: https://glab-caltech.github.io/converseg/