Curriculum-DPO++: Direct Preference Optimization via Data and Model Curricula for Text-to-Image Generation
作者: Florinel-Alin Croitoru, Vlad Hondru, Radu Tudor Ionescu, Nicu Sebe, Mubarak Shah
分类: cs.CV, cs.AI, cs.LG
发布日期: 2026-02-13
备注: arXiv admin note: substantial text overlap with arXiv:2405.13637
🔗 代码/项目: GITHUB
💡 一句话要点
Curriculum-DPO++:通过数据和模型课程学习优化文本到图像生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本到图像生成 直接偏好优化 课程学习 模型容量 低秩适应
📋 核心要点
- 现有RLHF和DPO方法忽略了偏好学习的难度差异,导致文本到图像生成任务中优化效率低下。
- Curriculum-DPO++结合数据级和模型级课程学习,动态增加去噪网络的学习能力,优化偏好学习过程。
- 实验结果表明,Curriculum-DPO++在文本对齐、美学和人类偏好方面均优于Curriculum-DPO及其他先进方法。
📝 摘要(中文)
直接偏好优化(DPO)已被证明是人类反馈强化学习(RLHF)的一种有效替代方案。然而,RLHF和DPO都没有考虑到学习某些偏好比学习其他偏好更困难这一事实,导致优化过程并非最优。为了解决文本到图像生成中的这一问题,我们最近提出了Curriculum-DPO,一种按难度组织图像对的方法。在本文中,我们介绍Curriculum-DPO++,一种增强方法,它将原始数据级课程与一种新的模型级课程相结合。更准确地说,我们建议随着训练的进行,动态地增加去噪网络的学习能力。我们通过两种机制来实现这种能力提升。首先,我们使用原始Curriculum-DPO中使用的可训练层的一个子集来初始化模型。随着训练的进行,我们依次解冻层,直到配置与完整基线架构匹配。其次,由于微调是基于低秩适应(LoRA)的,我们为低秩矩阵的维度实现了一个渐进式调度。我们使用比基线小得多的维度来初始化低秩矩阵,而不是保持固定的容量。随着训练的进行,我们逐步增加它们的秩,允许容量增长,直到收敛到与Curriculum-DPO中相同的秩值。此外,我们提出了一种替代Curriculum-DPO所采用的排序策略。最后,我们在九个基准上将Curriculum-DPO++与Curriculum-DPO和其他最先进的偏好优化方法进行比较,在文本对齐、美学和人类偏好方面优于竞争方法。
🔬 方法详解
问题定义:现有直接偏好优化(DPO)方法在文本到图像生成任务中,没有充分考虑不同偏好学习的难度差异,导致训练效率和生成质量受限。模型难以有效学习所有偏好,尤其是在训练初期。
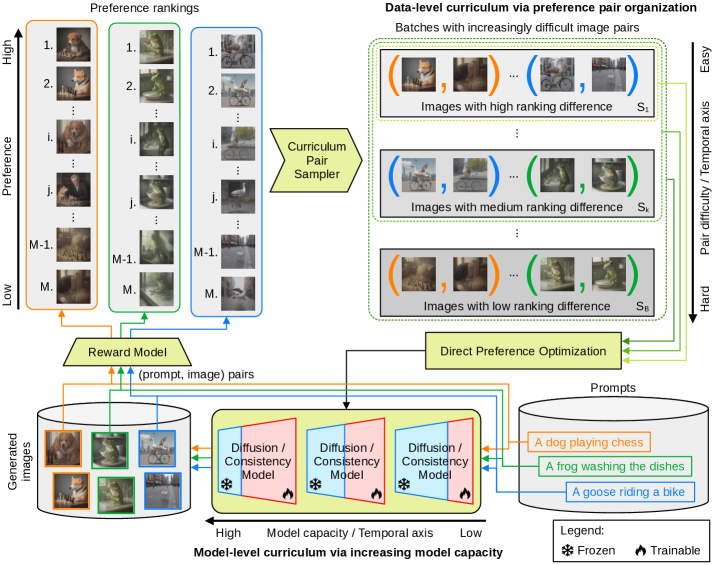
核心思路:Curriculum-DPO++的核心在于引入课程学习的思想,分别在数据层面和模型层面构建课程。数据层面沿用Curriculum-DPO的难度排序策略,模型层面则通过动态调整模型容量,使模型先学习简单的偏好,再逐步学习复杂的偏好。这种循序渐进的方式能够更有效地利用训练数据,提升模型性能。
技术框架:Curriculum-DPO++的整体框架基于DPO,主要包含以下几个阶段:1) 数据准备:构建图像对,并根据难度进行排序;2) 模型初始化:使用部分网络层或低秩矩阵初始化模型;3) 课程学习:逐步解冻网络层或增加低秩矩阵的秩;4) 偏好优化:使用DPO损失函数进行微调。该框架的关键在于模型层面的课程学习策略。
关键创新:Curriculum-DPO++的关键创新在于模型层面的课程学习。与传统的DPO方法相比,Curriculum-DPO++并非一开始就使用完整的模型进行训练,而是先使用一个容量较小的模型,然后逐步增加模型容量。这种方式能够避免模型在训练初期陷入局部最优,提高训练效率和泛化能力。
关键设计:模型层面的课程学习通过两种机制实现:1) 逐步解冻网络层:初始只训练部分网络层,随着训练的进行,逐步解冻剩余层;2) 渐进式低秩适应(LoRA):初始使用低秩矩阵,随着训练的进行,逐步增加低秩矩阵的秩。此外,论文还提出了一种替代的排序策略,用于数据层面的课程学习。具体参数设置和损失函数与DPO保持一致。
🖼️ 关键图片

📊 实验亮点
Curriculum-DPO++在九个基准测试中,相较于Curriculum-DPO和其他先进的偏好优化方法,在文本对齐、美学质量和人类偏好方面均取得了显著提升。实验结果表明,所提出的数据和模型课程学习策略能够有效提高文本到图像生成模型的性能。
🎯 应用场景
Curriculum-DPO++可应用于各种文本到图像生成任务,例如艺术创作、产品设计、游戏开发等。通过优化生成图像的质量和与文本描述的对齐程度,可以提升用户体验,并为相关产业带来更高的商业价值。该方法也可推广到其他生成任务,例如文本生成、视频生成等。
📄 摘要(原文)
Direct Preference Optimization (DPO) has been proposed as an effective and efficient alternative to reinforcement learning from human feedback (RLHF). However, neither RLHF nor DPO take into account the fact that learning certain preferences is more difficult than learning other preferences, rendering the optimization process suboptimal. To address this gap in text-to-image generation, we recently proposed Curriculum-DPO, a method that organizes image pairs by difficulty. In this paper, we introduce Curriculum-DPO++, an enhanced method that combines the original data-level curriculum with a novel model-level curriculum. More precisely, we propose to dynamically increase the learning capacity of the denoising network as training advances. We implement this capacity increase via two mechanisms. First, we initialize the model with only a subset of the trainable layers used in the original Curriculum-DPO. As training progresses, we sequentially unfreeze layers until the configuration matches the full baseline architecture. Second, as the fine-tuning is based on Low-Rank Adaptation (LoRA), we implement a progressive schedule for the dimension of the low-rank matrices. Instead of maintaining a fixed capacity, we initialize the low-rank matrices with a dimension significantly smaller than that of the baseline. As training proceeds, we incrementally increase their rank, allowing the capacity to grow until it converges to the same rank value as in Curriculum-DPO. Furthermore, we propose an alternative ranking strategy to the one employed by Curriculum-DPO. Finally, we compare Curriculum-DPO++ against Curriculum-DPO and other state-of-the-art preference optimization approaches on nine benchmarks, outperforming the competing methods in terms of text alignment, aesthetics and human preference. Our code is available at https://github.com/CroitoruAlin/Curriculum-DPO.