Human-Aligned MLLM Judges for Fine-Grained Image Editing Evaluation: A Benchmark, Framework, and Analysis
作者: Runzhou Liu, Hailey Weingord, Sejal Mittal, Prakhar Dungarwal, Anusha Nandula, Bo Ni, Samyadeep Basu, Hongjie Chen, Nesreen K. Ahmed, Li Li, Jiayi Zhang, Koustava Goswami, Subhojyoti Mukherjee, Branislav Kveton, Puneet Mathur, Franck Dernoncourt, Yue Zhao, Yu Wang, Ryan A. Rossi, Zhengzhong Tu, Hongru Du
分类: cs.CV, cs.CL
发布日期: 2026-02-13
💡 一句话要点
提出基于MLLM的细粒度图像编辑评估框架,解决传统指标粗糙、缺乏可解释性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像编辑评估 多模态大语言模型 细粒度评估 人工评估对齐 基准数据集
📋 核心要点
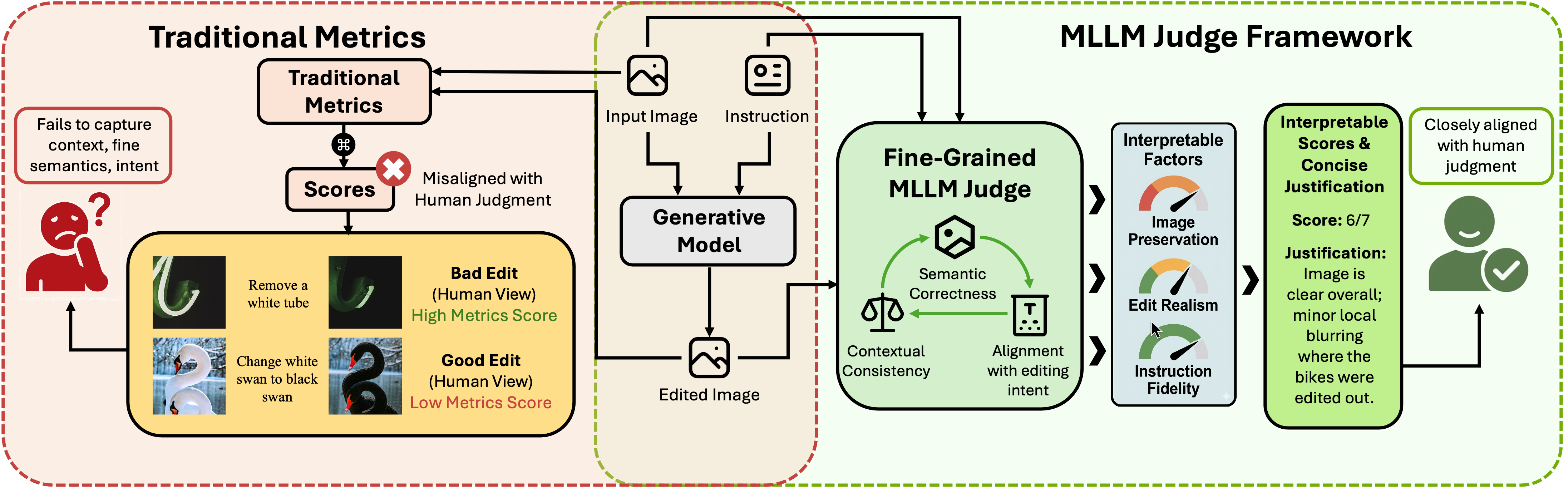
- 传统图像编辑评估指标粒度粗糙,缺乏可解释性,难以捕捉人类感知和意图的关键方面。
- 提出基于MLLM的细粒度评估框架,将评估分解为图像保持、编辑质量和指令保真度等多个可解释因素。
- 构建了包含人工评估、MLLM评估、模型输出和传统指标的新基准,验证了MLLM评判器与人类评估的高度一致性。
📝 摘要(中文)
本文提出了一种细粒度的多模态大语言模型(MLLM)作为评判器的图像编辑评估框架,该框架将常见的评估概念分解为十二个细粒度的、可解释的因素,涵盖图像保持、编辑质量和指令保真度。基于此,本文构建了一个新的人工验证的基准,整合了人工判断、基于MLLM的评估、模型输出和传统指标,涵盖了各种图像编辑任务。通过广泛的人工研究,表明所提出的MLLM评判器在细粒度上与人工评估高度一致,支持将其用作可靠且可扩展的评估器。进一步证明,传统的图像编辑指标通常不能很好地代表这些因素,无法区分过度编辑或语义不精确的输出,而本文的评判器在离线和在线设置中提供了更直观和信息丰富的评估。这项工作提出了一个基准、一个原则性的分解以及经验证据,将细粒度的MLLM评判器定位为研究、比较和改进图像编辑方法的实用基础。
🔬 方法详解
问题定义:图像编辑模型的评估一直面临挑战,现有指标通常过于粗糙,缺乏可解释性,无法准确捕捉人类对图像编辑质量的细粒度感知,例如编辑的可控性、定位的准确性以及对用户指令的忠实程度。传统指标容易奖励视觉上合理的输出,而忽略了语义的准确性和编辑的意图。
核心思路:核心在于利用多模态大语言模型(MLLM)的强大能力,将其作为评判器,对图像编辑结果进行细粒度的评估。通过将评估任务分解为多个可解释的因素,例如图像内容保持、编辑质量和指令遵循程度,从而更全面、更准确地评估图像编辑模型的效果。这种方法旨在弥合传统指标与人类感知之间的差距。
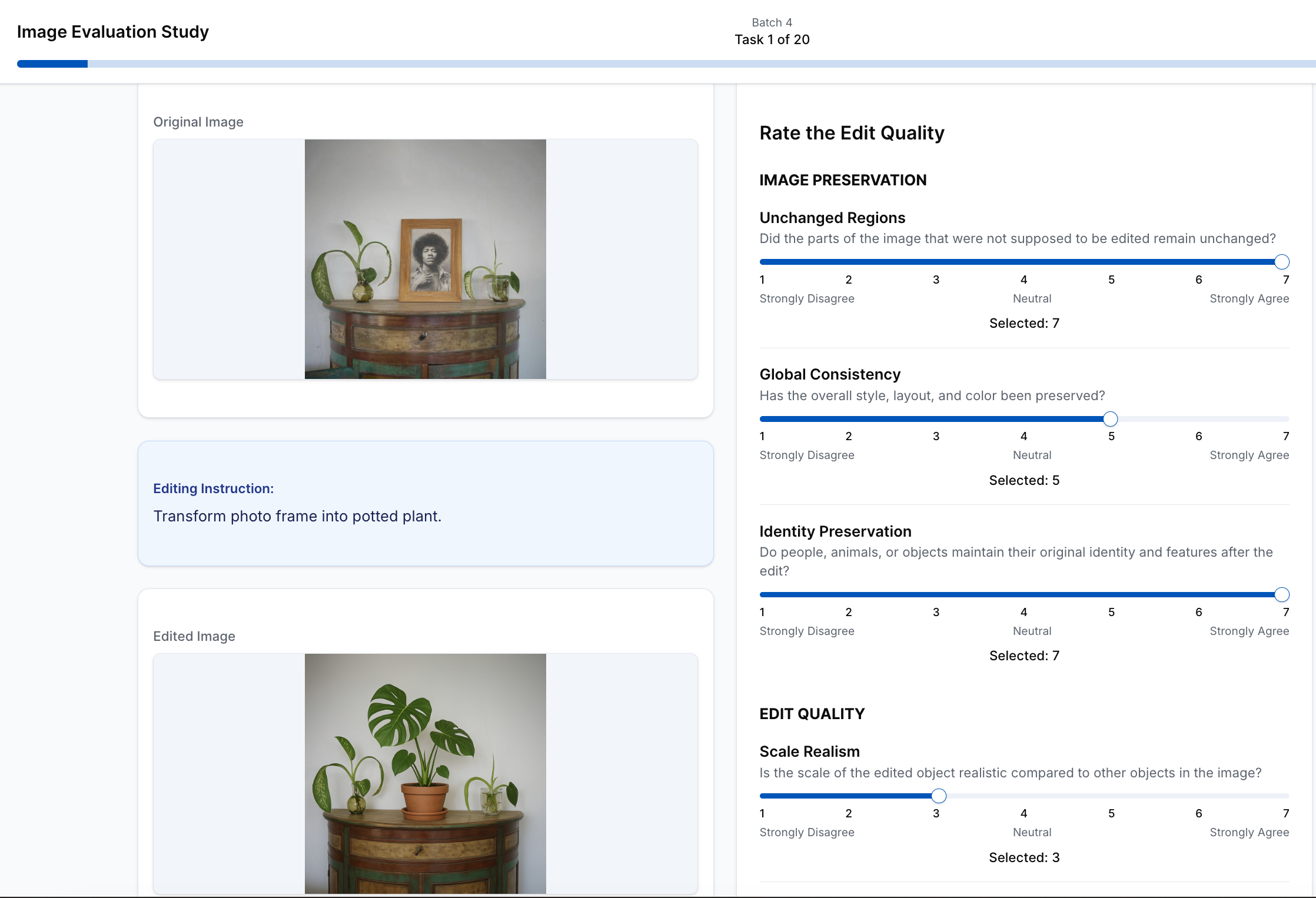
技术框架:该框架包含以下几个主要组成部分:1) 定义细粒度的评估因素(12个);2) 构建包含人工评估、MLLM评估、模型输出和传统指标的综合基准数据集;3) 使用MLLM对图像编辑结果进行评估,并与人工评估进行对比;4) 分析MLLM评估结果,并与传统指标进行比较,以验证MLLM评估的有效性。
关键创新:最重要的创新在于将MLLM引入图像编辑评估领域,并将其应用于细粒度的评估任务。与传统的基于像素或特征相似度的指标不同,MLLM能够理解图像的语义信息,并根据用户指令评估编辑结果的质量。此外,将评估分解为多个可解释的因素,使得评估结果更具透明性和可解释性。
关键设计:论文中定义了12个细粒度的评估因素,这些因素涵盖了图像编辑的各个方面,例如内容保持、风格迁移、对象添加/删除等。MLLM的具体选择和prompt的设计对评估结果至关重要,论文中应该有详细描述。损失函数方面,主要目标是使MLLM的评估结果与人工评估结果尽可能一致,可以使用回归损失或排序损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的MLLM评判器与人工评估结果高度一致,显著优于传统的图像编辑指标。具体而言,MLLM评判器在区分过度编辑或语义不精确的输出方面表现出色,能够提供更直观和信息丰富的评估。该研究还构建了一个包含人工评估、MLLM评估、模型输出和传统指标的综合基准数据集,为后续研究提供了便利。
🎯 应用场景
该研究成果可广泛应用于图像编辑模型的开发、测试和改进。通过使用MLLM评判器,开发者可以更准确地评估模型的性能,并针对性地进行优化。此外,该方法还可以用于自动图像编辑系统的质量控制,确保生成的图像符合用户的期望。未来,该方法有望扩展到视频编辑、3D模型编辑等领域。
📄 摘要(原文)
Evaluating image editing models remains challenging due to the coarse granularity and limited interpretability of traditional metrics, which often fail to capture aspects important to human perception and intent. Such metrics frequently reward visually plausible outputs while overlooking controllability, edit localization, and faithfulness to user instructions. In this work, we introduce a fine-grained Multimodal Large Language Model (MLLM)-as-a-Judge framework for image editing that decomposes common evaluation notions into twelve fine-grained interpretable factors spanning image preservation, edit quality, and instruction fidelity. Building on this formulation, we present a new human-validated benchmark that integrates human judgments, MLLM-based evaluations, model outputs, and traditional metrics across diverse image editing tasks. Through extensive human studies, we show that the proposed MLLM judges align closely with human evaluations at a fine granularity, supporting their use as reliable and scalable evaluators. We further demonstrate that traditional image editing metrics are often poor proxies for these factors, failing to distinguish over-edited or semantically imprecise outputs, whereas our judges provide more intuitive and informative assessments in both offline and online settings. Together, this work introduces a benchmark, a principled factorization, and empirical evidence positioning fine-grained MLLM judges as a practical foundation for studying, comparing, and improving image editing approaches.