Towards Universal Video MLLMs with Attribute-Structured and Quality-Verified Instructions
作者: Yunheng Li, Hengrui Zhang, Meng-Hao Guo, Wenzhao Gao, Shaoyong Jia, Shaohui Jiao, Qibin Hou, Ming-Ming Cheng
分类: cs.CV
发布日期: 2026-02-13
备注: Project page: https://asid-caption.github.io/
💡 一句话要点
提出ASID-1M数据集与ASID-Captioner模型,提升通用视频多模态大模型在细粒度理解上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态学习 指令学习 数据集构建 数据验证
📋 核心要点
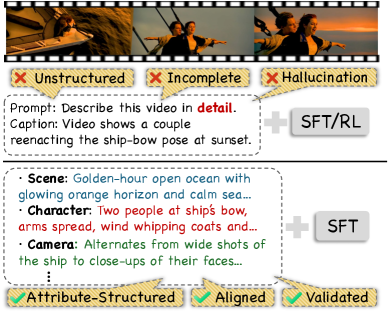
- 现有视频理解模型受限于视频-指令数据的质量,缺乏细粒度组织和可靠标注,导致模型性能受限。
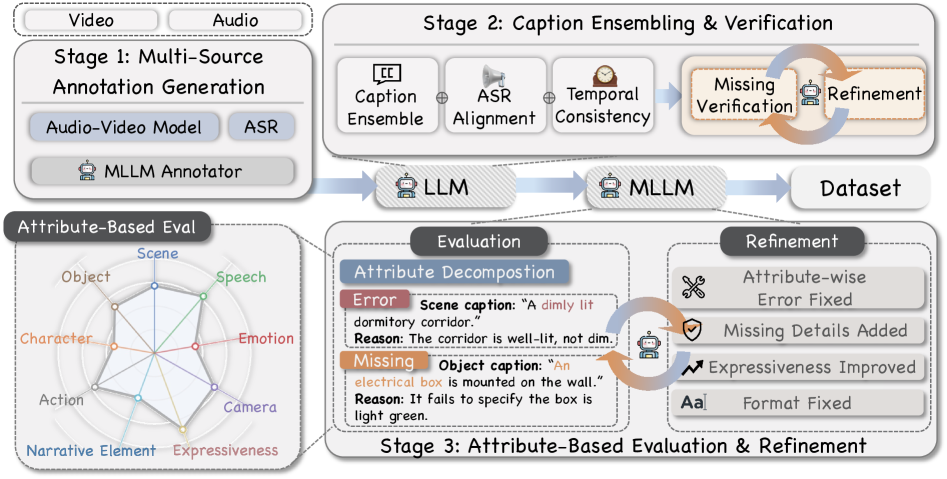
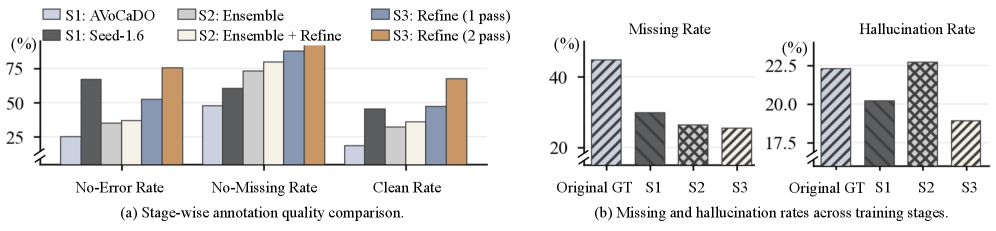
- 论文提出ASID-1M数据集,包含百万级细粒度视听指令标注,并设计ASID-Verify流程保证数据质量。
- 通过在ASID-1M上微调ASID-Captioner模型,在多个基准测试中取得了SOTA性能,提升了细粒度理解能力。
📝 摘要(中文)
通用的视频理解需要在各种真实场景中对随时间变化的细粒度视觉和音频信息进行建模。然而,现有模型的性能主要受到视频-指令数据的限制,这些数据将复杂的视听内容表示为单一、不完整的描述,缺乏细粒度的组织和可靠的标注。为了解决这个问题,我们引入了:(i)ASID-1M,一个包含一百万个结构化的、细粒度的视听指令标注的开源集合,具有单属性和多属性监督;(ii)ASID-Verify,一个可扩展的数据管理流程,用于标注,具有自动验证和细化,可强制描述与相应的视听内容之间的语义和时间一致性;(iii)ASID-Captioner,一个通过在ASID-1M上进行监督微调(SFT)训练的视频理解模型。在涵盖视听字幕、属性字幕、基于字幕的问答和基于字幕的时间定位的七个基准测试中进行的实验表明,ASID-Captioner提高了细粒度字幕质量,同时减少了幻觉并改善了指令遵循。它在开源模型中实现了最先进的性能,并且与Gemini-3-Pro相比具有竞争力。
🔬 方法详解
问题定义:现有视频多模态大模型在理解细粒度视听信息方面存在不足,主要原因是缺乏高质量的训练数据。现有的视频-指令数据集通常包含不完整、粗粒度的描述,并且标注质量难以保证,导致模型难以学习到细粒度的视听特征和关系。这限制了模型在复杂场景下的理解和推理能力。
核心思路:论文的核心思路是通过构建一个大规模、高质量、细粒度的视听指令数据集ASID-1M,并在此基础上训练一个视频理解模型ASID-Captioner,从而提升模型对细粒度视听信息的理解能力。通过引入属性结构化的标注方式和自动验证流程,保证数据的质量和细粒度,从而提升模型的性能。
技术框架:整体框架包含三个主要部分:ASID-1M数据集构建、ASID-Verify数据验证流程和ASID-Captioner模型训练。ASID-1M数据集包含百万级别的视听指令标注,涵盖单属性和多属性监督。ASID-Verify流程用于自动验证和细化标注,保证语义和时间一致性。ASID-Captioner模型通过在ASID-1M上进行监督微调(SFT)训练得到。
关键创新:论文的关键创新在于提出了属性结构化的标注方式和自动验证流程。属性结构化的标注方式能够提供更细粒度的视听信息描述,使得模型能够学习到更丰富的特征。自动验证流程能够有效地减少标注错误和不一致性,保证数据的质量。此外,大规模数据集的构建本身也是一个重要的贡献。
关键设计:ASID-Verify流程包含多个模块,用于自动检测和纠正标注错误,例如语义一致性检测和时间一致性检测。ASID-Captioner模型采用Transformer架构,并针对视频理解任务进行了优化。具体的网络结构和参数设置在论文中有详细描述。损失函数主要采用交叉熵损失,用于优化模型的生成能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ASID-Captioner在七个基准测试中取得了显著的性能提升,包括视听字幕、属性字幕、基于字幕的问答和基于字幕的时间定位。在开源模型中实现了SOTA性能,并且与Gemini-3-Pro相比具有竞争力。例如,在细粒度字幕生成任务上,ASID-Captioner显著降低了幻觉现象,提高了指令遵循能力。
🎯 应用场景
该研究成果可广泛应用于视频内容理解、智能视频分析、人机交互等领域。例如,可以用于自动生成视频摘要、视频内容检索、智能客服等应用。高质量的视频理解能力对于提升用户体验和智能化水平具有重要意义,未来可应用于自动驾驶、机器人等领域。
📄 摘要(原文)
Universal video understanding requires modeling fine-grained visual and audio information over time in diverse real-world scenarios. However, the performance of existing models is primarily constrained by video-instruction data that represents complex audiovisual content as single, incomplete descriptions, lacking fine-grained organization and reliable annotation. To address this, we introduce: (i) ASID-1M, an open-source collection of one million structured, fine-grained audiovisual instruction annotations with single- and multi-attribute supervision; (ii) ASID-Verify, a scalable data curation pipeline for annotation, with automatic verification and refinement that enforces semantic and temporal consistency between descriptions and the corresponding audiovisual content; and (iii) ASID-Captioner, a video understanding model trained via Supervised Fine-Tuning (SFT) on the ASID-1M. Experiments across seven benchmarks covering audiovisual captioning, attribute-wise captioning, caption-based QA, and caption-based temporal grounding show that ASID-Captioner improves fine-grained caption quality while reducing hallucinations and improving instruction following. It achieves state-of-the-art performance among open-source models and is competitive with Gemini-3-Pro.