Training-Free Acceleration for Document Parsing Vision-Language Model with Hierarchical Speculative Decoding
作者: Wenhui Liao, Hongliang Li, Pengyu Xie, Xinyu Cai, Yufan Shen, Yi Xin, Qi Qin, Shenglong Ye, Tianbin Li, Ming Hu, Junjun He, Yihao Liu, Wenhai Wang, Min Dou, Bin Fu, Botian Shi, Yu Qiao, Lianwen Jin
分类: cs.CV
发布日期: 2026-02-13
备注: Preliminary version of an ongoing project; the paper will be refined and extended in subsequent revisions
💡 一句话要点
提出基于分层推测解码的文档解析VLM无训练加速方法,提升长文档处理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档解析 视觉语言模型 推测解码 无训练加速 长文档处理
📋 核心要点
- 现有基于VLM的文档解析模型在处理长文档时,由于自回归生成长序列,推理速度慢。
- 论文提出一种基于分层推测解码的无训练加速方法,利用轻量级模型生成草稿,VLM并行验证。
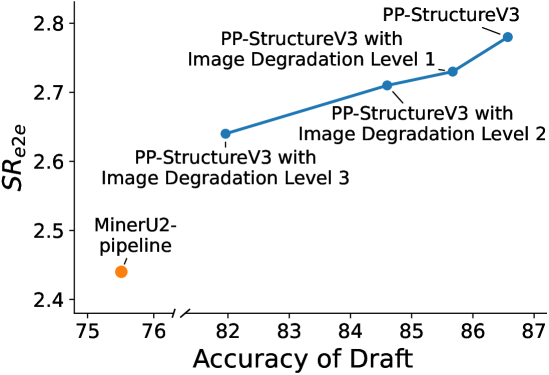
- 实验表明,该方法在OmniDocBench上实现了2.42倍的无损加速,在长文档解析任务上高达4.89倍。
📝 摘要(中文)
文档解析是多模态理解中的一项基础任务,支持信息抽取和智能文档分析等广泛的下游应用。基于VLM的端到端方法凭借强大的语义建模和鲁棒的泛化能力,已成为近年来的主流范式。然而,由于在处理长文档时必须自回归地生成长token序列,这些模型通常存在显著的推理延迟。本文受文档解析中常见的极长输出和复杂布局结构的启发,提出了一种无需训练且高效的加速方法。借鉴推测解码的思想,我们采用轻量级的文档解析流程作为草稿模型来预测批量的未来token,而更精确的VLM并行验证这些草稿预测。此外,我们通过将每个页面划分为独立的区域,进一步利用文档的布局结构特性,从而能够使用相同的草稿-验证策略并行解码每个区域。然后,根据自然的阅读顺序组装最终的预测结果。实验结果表明了我们方法的有效性:在通用OmniDocBench上,我们的方法为dots.ocr模型提供了2.42倍的无损加速,并在长文档解析任务上实现了高达4.89倍的加速。我们将发布我们的代码,以方便重现和未来的研究。
🔬 方法详解
问题定义:论文旨在解决基于VLM的文档解析模型在处理长文档时推理速度慢的问题。现有方法需要自回归地生成长token序列,计算成本高昂,严重影响了实际应用效率。
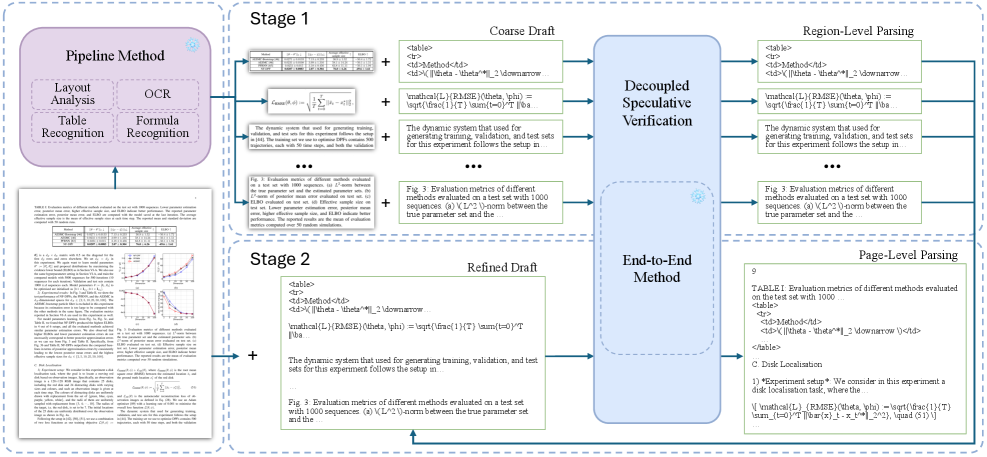
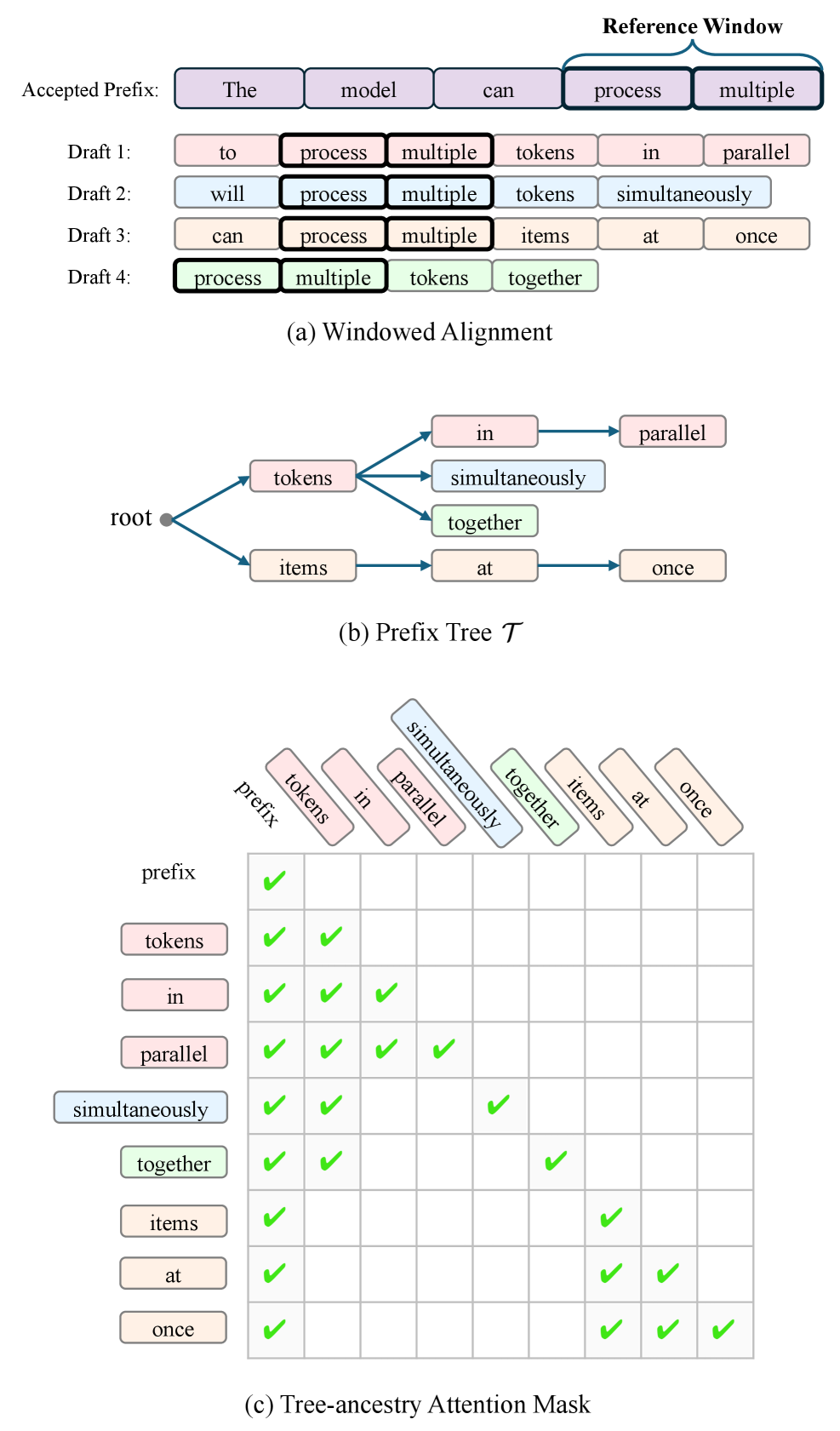
核心思路:论文的核心思路是借鉴推测解码的思想,利用一个轻量级的草稿模型快速生成候选token序列,然后由更精确的VLM模型并行验证这些候选token,从而避免VLM的串行自回归解码过程,达到加速的目的。同时,针对文档的布局特性,将页面划分为独立区域并行处理。
技术框架:整体框架包含以下几个主要模块:1) 轻量级草稿模型:用于快速生成候选token序列;2) VLM验证模型:用于并行验证草稿模型生成的token序列的正确性;3) 区域划分模块:将文档页面划分为多个独立的区域,以便并行处理;4) 序列组装模块:根据自然阅读顺序将各个区域的解析结果组装成完整的文档解析结果。
关键创新:最重要的技术创新点在于将推测解码的思想应用于文档解析VLM,并结合文档的布局特性进行区域划分和并行处理。与传统的自回归解码相比,该方法能够显著减少VLM的计算量,从而实现加速。此外,该方法是training-free的,无需额外的训练数据或模型微调。
关键设计:草稿模型可以选择轻量级的文档解析pipeline,例如基于OCR的传统方法。区域划分策略可以根据文档的实际布局进行调整,例如基于文本块或表格等结构进行划分。VLM验证模型可以使用预训练的文档解析VLM,例如LayoutLMv3或dots.ocr。序列组装模块需要考虑文档的自然阅读顺序,例如从左到右、从上到下。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在通用OmniDocBench数据集上,对dots.ocr模型实现了2.42倍的无损加速。在长文档解析任务上,加速效果更为显著,达到了4.89倍。这些结果充分证明了该方法在提升文档解析VLM推理效率方面的有效性,且无需任何额外的训练。
🎯 应用场景
该研究成果可广泛应用于各种需要快速文档解析的场景,例如自动化办公、财务报表处理、法律文档分析、医学影像报告解读等。通过提升文档解析效率,可以显著降低人工成本,提高工作效率,并为下游应用提供更及时、准确的数据支持。未来,该方法有望进一步推广到其他长序列生成任务中。
📄 摘要(原文)
Document parsing is a fundamental task in multimodal understanding, supporting a wide range of downstream applications such as information extraction and intelligent document analysis. Benefiting from strong semantic modeling and robust generalization, VLM-based end-to-end approaches have emerged as the mainstream paradigm in recent years. However, these models often suffer from substantial inference latency, as they must auto-regressively generate long token sequences when processing long-form documents. In this work, motivated by the extremely long outputs and complex layout structures commonly found in document parsing, we propose a training-free and highly efficient acceleration method. Inspired by speculative decoding, we employ a lightweight document parsing pipeline as a draft model to predict batches of future tokens, while the more accurate VLM verifies these draft predictions in parallel. Moreover, we further exploit the layout-structured nature of documents by partitioning each page into independent regions, enabling parallel decoding of each region using the same draft-verify strategy. The final predictions are then assembled according to the natural reading order. Experimental results demonstrate the effectiveness of our approach: on the general-purpose OmniDocBench, our method provides a 2.42x lossless acceleration for the dots.ocr model, and achieves up to 4.89x acceleration on long-document parsing tasks. We will release our code to facilitate reproducibility and future research.