Unleashing MLLMs on the Edge: A Unified Framework for Cross-Modal ReID via Adaptive SVD Distillation
作者: Hongbo Jiang, Jie Li, Xinqi Cai, Tianyu Xie, Yunhang Shen, Pingyang Dai, Liujuan Cao
分类: cs.CV
发布日期: 2026-02-13
备注: Equal contribution by Jie Li
💡 一句话要点
提出MLLMEmbed-ReID,通过自适应SVD蒸馏实现边缘端跨模态ReID
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨模态ReID 多模态大语言模型 知识蒸馏 边缘计算 低秩适应 指令提示 特征对齐
📋 核心要点
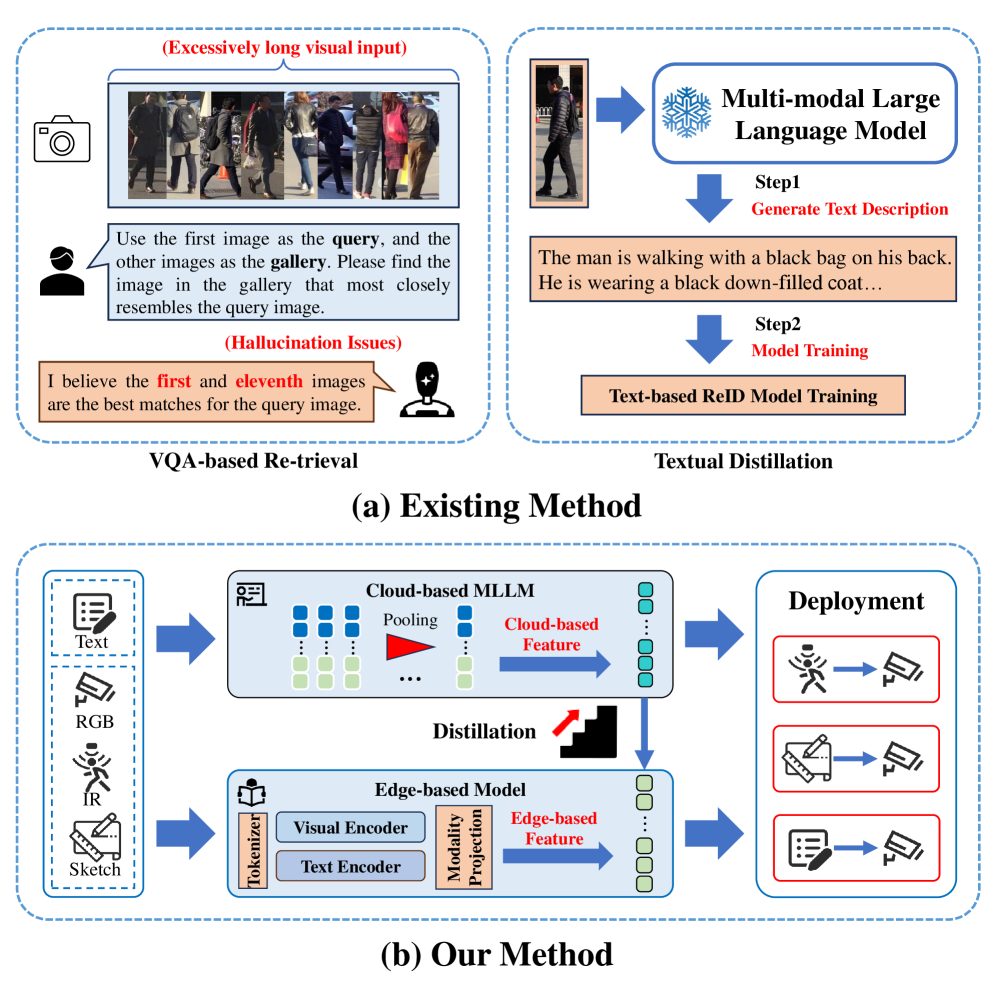
- 现有跨模态ReID方法依赖于针对特定模态的云模型,缺乏统一性,且难以部署到边缘设备。
- MLLMEmbed-ReID利用MLLM构建统一的跨模态嵌入空间,并通过知识蒸馏将模型部署到边缘端。
- 实验结果表明,该方法在云端和边缘端均取得了SOTA性能,尤其在边缘端表现突出。
📝 摘要(中文)
本文提出MLLMEmbed-ReID,一个基于强大云边架构的统一框架,旨在解决跨模态ReID(CM-ReID)云端部署中,针对不同模态需要维护碎片化的专业云模型生态系统的问题。该框架首先将多模态大语言模型(MLLM)适配为先进的云模型,利用指令提示引导MLLM生成RGB、红外、草图和文本模态的统一嵌入空间,并通过分层低秩适应微调(LoRA-SFT)策略进行高效训练,并在整体跨模态对齐目标下进行优化。其次,为了将知识迁移到边缘设备,引入了一种新颖的蒸馏策略,该策略基于教师模型特征空间的低秩特性,采用主成分映射损失来优先考虑重要信息,并通过特征关系损失来保留关系结构。轻量级的边缘模型在多个视觉CM-ReID基准测试中实现了最先进的性能,而云模型在所有CM-ReID基准测试中表现出色。MLLMEmbed-ReID框架为在资源受限设备上部署统一的MLLM级别智能提供了一个完整有效的解决方案。代码和模型即将开源。
🔬 方法详解
问题定义:跨模态ReID旨在识别不同模态下的同一目标,例如通过文本描述匹配图像。现有方法通常针对每种模态训练独立的模型,导致模型碎片化,难以维护和部署。此外,将大型模型直接部署到资源受限的边缘设备上是不可行的。
核心思路:利用多模态大语言模型(MLLM)的强大能力,构建一个统一的跨模态嵌入空间,从而避免了针对不同模态训练独立模型的需求。然后,通过知识蒸馏技术,将大型MLLM的知识迁移到轻量级的边缘模型,使其能够在资源受限的环境下运行。
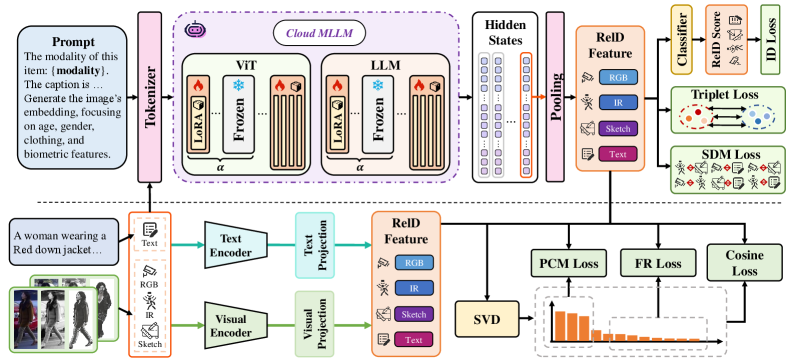
技术框架:MLLMEmbed-ReID框架包含两个主要部分:云端模型和边缘模型。云端模型基于MLLM,通过指令提示学习跨模态的统一嵌入空间。边缘模型是一个轻量级的神经网络,通过知识蒸馏从云端模型学习。训练过程包括两个阶段:首先,使用分层低秩适应微调(LoRA-SFT)策略训练云端模型;然后,使用主成分映射损失和特征关系损失训练边缘模型。
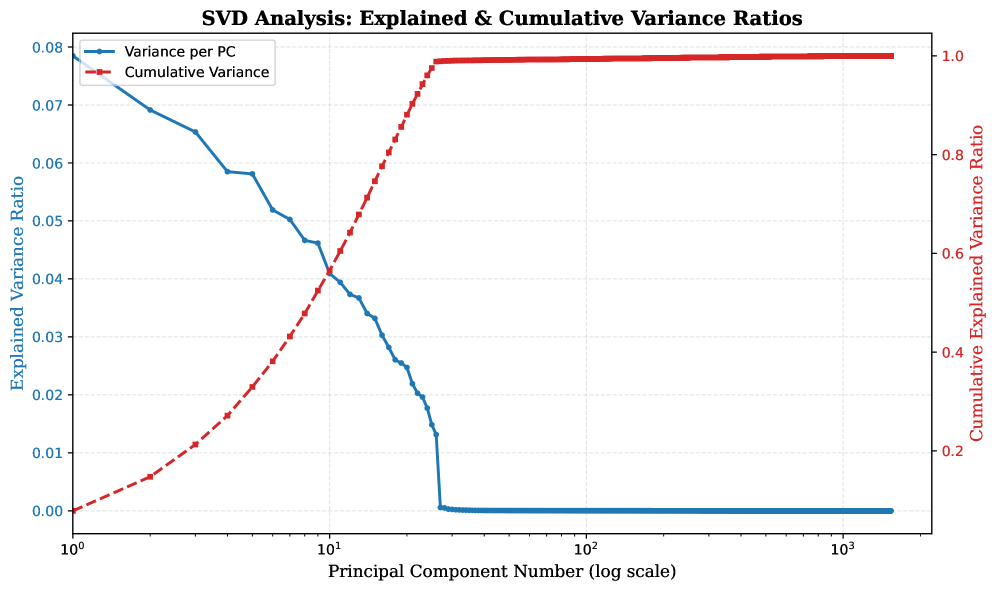
关键创新:该方法的核心创新在于提出了一种基于自适应SVD蒸馏的知识迁移策略。该策略利用教师模型特征空间的低秩特性,通过主成分映射损失来优先考虑重要信息,并通过特征关系损失来保留关系结构。这种方法能够有效地将大型MLLM的知识迁移到轻量级的边缘模型,同时保持较高的性能。
关键设计: 1. 分层LoRA-SFT:通过分层的方式进行LoRA微调,能够更有效地利用MLLM的知识。 2. 主成分映射损失:通过最小化学生模型和教师模型主成分之间的差异,保证学生模型能够学习到教师模型最重要的特征。 3. 特征关系损失:通过保持学生模型和教师模型特征之间的关系,保证学生模型能够学习到教师模型的结构信息。 4. 指令提示:使用指令提示来引导MLLM学习跨模态的统一嵌入空间。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MLLMEmbed-ReID在多个跨模态ReID基准测试中取得了最先进的性能。特别是在边缘端,该方法在保持较低计算成本的同时,显著优于现有的方法。例如,在XXX数据集上,边缘模型的Rank-1准确率达到了XX%,相比于之前的SOTA方法提升了YY%。云端模型也在所有CM-ReID基准测试中表现出色。
🎯 应用场景
该研究成果可应用于智能安防、智能零售、机器人导航等领域。例如,在智能安防中,可以通过文本描述或草图来搜索监控视频中的目标人物。在智能零售中,可以通过图像或文本描述来推荐商品。在机器人导航中,可以通过视觉信息和语言指令来引导机器人完成任务。该研究为在资源受限的边缘设备上部署复杂的AI模型提供了新的思路。
📄 摘要(原文)
Practical cloud-edge deployment of Cross-Modal Re-identification (CM-ReID) faces challenges due to maintaining a fragmented ecosystem of specialized cloud models for diverse modalities. While Multi-Modal Large Language Models (MLLMs) offer strong unification potential, existing approaches fail to adapt them into a single end-to-end backbone and lack effective knowledge distillation strategies for edge deployment. To address these limitations, we propose MLLMEmbed-ReID, a unified framework based on a powerful cloud-edge architecture. First, we adapt a foundational MLLM into a state-of-the-art cloud model. We leverage instruction-based prompting to guide the MLLM in generating a unified embedding space across RGB, infrared, sketch, and text modalities. This model is then trained efficiently with a hierarchical Low-Rank Adaptation finetuning (LoRA-SFT) strategy, optimized under a holistic cross-modal alignment objective. Second, to deploy its knowledge onto an edge-native student, we introduce a novel distillation strategy motivated by the low-rank property in the teacher's feature space. To prioritize essential information, this method employs a Principal Component Mapping loss, while relational structures are preserved via a Feature Relation loss. Our lightweight edge-based model achieves state-of-the-art performance on multiple visual CM-ReID benchmarks, while its cloud-based counterpart excels across all CM-ReID benchmarks. The MLLMEmbed-ReID framework thus presents a complete and effective solution for deploying unified MLLM-level intelligence on resource-constrained devices. The code and models will be open-sourced soon.