RoadscapesQA: A Multitask, Multimodal Dataset for Visual Question Answering on Indian Roads
作者: Vijayasri Iyer, Maahin Rathinagiriswaran, Jyothikamalesh S
分类: cs.CV
发布日期: 2026-02-13
💡 一句话要点
RoadscapesQA:提出一个用于印度道路场景视觉问答的多任务多模态数据集。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 多模态数据集 道路场景理解 自动驾驶 印度道路环境
📋 核心要点
- 自动驾驶需要理解道路场景,现有方法在非结构化环境下的场景理解能力不足,面临挑战。
- RoadscapesQA数据集通过规则启发式方法推断场景属性,并生成QA对,促进场景理解任务。
- 该数据集包含印度各种道路场景,为视觉-语言模型在复杂环境下的应用提供了基准。
📝 摘要(中文)
本文提出了RoadscapesQA,一个多任务多模态数据集,包含多达9000张在各种印度驾驶环境中拍摄的图像,并附带人工验证的边界框。为了促进可扩展的场景理解,该数据集采用基于规则的启发式方法来推断各种场景属性,这些属性随后被用于生成问题-答案(QA)对,以支持对象定位、推理和场景理解等任务。RoadscapesQA数据集涵盖了来自印度城市和乡村的各种场景,包括高速公路、服务道路、乡村小路和拥挤的城市街道,并在白天和夜间设置下拍摄。RoadscapesQA旨在推进非结构化环境中视觉场景理解的研究。本文描述了数据收集和标注过程,展示了关键数据集统计信息,并为使用视觉-语言模型的图像QA任务提供了初始基线。
🔬 方法详解
问题定义:论文旨在解决在非结构化印度道路环境中进行视觉场景理解的问题。现有方法在处理复杂、多变的道路场景,特别是印度特有的交通状况和环境因素时,表现出不足。缺乏高质量、多样化的数据集是制约相关研究进展的关键瓶颈。
核心思路:论文的核心思路是构建一个大规模、多模态的视觉问答数据集,该数据集不仅包含图像和标注,还包含基于规则生成的问答对,从而促进模型学习场景中的对象关系、属性和推理能力。通过这种方式,模型可以更好地理解和解释复杂的道路场景。
技术框架:RoadscapesQA数据集的构建流程主要包括以下几个阶段:1) 数据采集:在印度各种道路环境中采集图像,包括城市和乡村、白天和夜晚等场景。2) 目标检测标注:对图像中的目标进行人工标注,生成边界框。3) 属性推断:利用基于规则的启发式方法,从标注的目标中推断出场景的各种属性。4) QA生成:基于推断的属性,自动生成问题-答案对,涵盖对象定位、推理和场景理解等任务。
关键创新:该论文的关键创新在于数据集的构建方法,特别是利用规则启发式方法自动生成QA对。这种方法可以有效地扩展数据集的规模,并覆盖各种场景和任务。此外,该数据集专注于印度道路环境,填补了现有数据集在该领域的空白。
关键设计:数据集包含9000张图像,涵盖多种印度道路场景。标注信息包括人工验证的边界框和自动生成的QA对。QA对的生成规则基于场景属性,例如对象类型、位置关系和环境条件。论文还提供了使用视觉-语言模型进行图像QA任务的初始基线,为后续研究提供参考。
🖼️ 关键图片
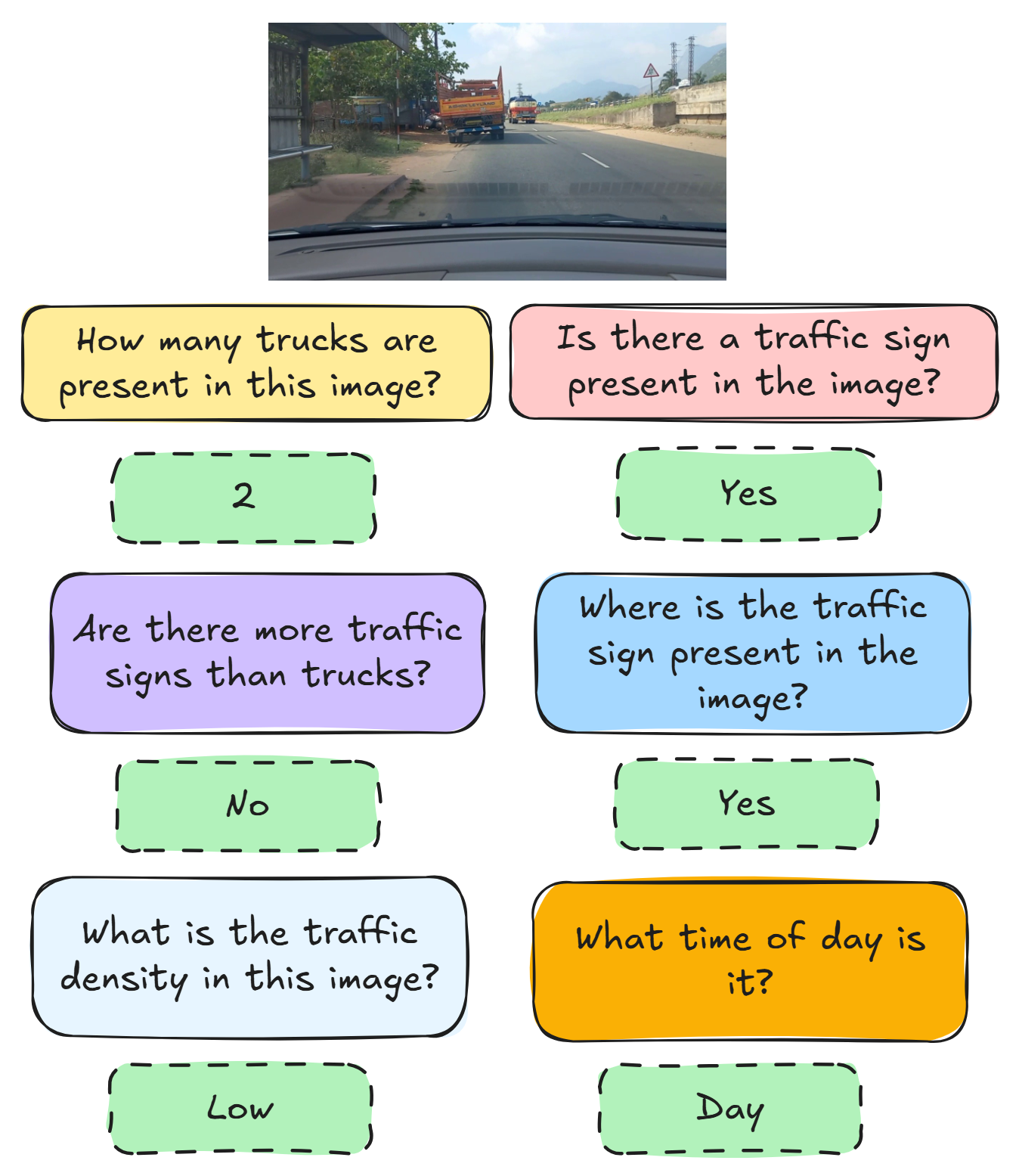

📊 实验亮点
论文构建了一个包含9000张图像的印度道路场景数据集,并利用规则启发式方法生成了大量的QA对。初步实验表明,现有的视觉-语言模型在该数据集上仍有很大的提升空间,为未来的研究提供了方向。该数据集的发布将促进非结构化道路环境下的视觉场景理解研究。
🎯 应用场景
RoadscapesQA数据集可用于训练和评估自动驾驶系统在复杂道路环境中的感知和决策能力。它还可以应用于智能交通系统,例如交通监控、事故检测和路径规划。该数据集的发布将促进计算机视觉和自然语言处理领域的研究,并推动相关技术在实际场景中的应用。
📄 摘要(原文)
Understanding road scenes is essential for autonomous driving, as it enables systems to interpret visual surroundings to aid in effective decision-making. We present Roadscapes, a multitask multimodal dataset consisting of upto 9,000 images captured in diverse Indian driving environments, accompanied by manually verified bounding boxes. To facilitate scalable scene understanding, we employ rule-based heuristics to infer various scene attributes, which are subsequently used to generate question-answer (QA) pairs for tasks such as object grounding, reasoning, and scene understanding. The dataset includes a variety of scenes from urban and rural India, encompassing highways, service roads, village paths, and congested city streets, captured in both daytime and nighttime settings. Roadscapes has been curated to advance research on visual scene understanding in unstructured environments. In this paper, we describe the data collection and annotation process, present key dataset statistics, and provide initial baselines for image QA tasks using vision-language models.