WISE: A Multimodal Search Engine for Visual Scenes, Audio, Objects, Faces, Speech, and Metadata
作者: Prasanna Sridhar, Horace Lee, David M. S. Pinto, Andrew Zisserman, Abhishek Dutta
分类: cs.IR, cs.CV
发布日期: 2026-02-13
备注: Software: https://www.robots.ox.ac.uk/~vgg/software/wise/ , Online demos: https://www.robots.ox.ac.uk/~vgg/software/wise/demo/ , Example Queries: https://www.robots.ox.ac.uk/~vgg/software/wise/examples/
🔗 代码/项目: GITLAB
💡 一句话要点
WISE:一个用于视觉场景、音频、对象、人脸、语音和元数据的多模态搜索引擎
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 搜索引擎 视听数据 向量搜索 开源软件 自然语言查询 反向图像搜索
📋 核心要点
- 现有方法在整合多模态信息进行高效检索方面存在挑战,用户需要机器学习专业知识才能使用。
- WISE通过集成多种模态的检索能力,并采用向量搜索技术,实现了高效且易于使用的多模态搜索引擎。
- WISE已应用于各种实际用例,证明了其在处理大规模视听数据检索方面的有效性和实用性。
📝 摘要(中文)
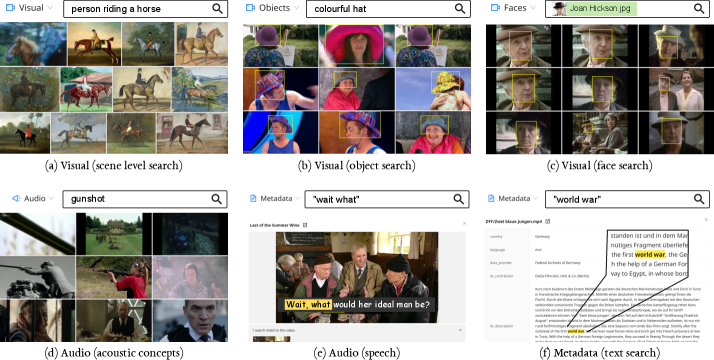
本文介绍了一个名为WISE的开源视听搜索引擎,它将一系列多模态检索功能集成到一个实用的工具中,用户无需具备机器学习专业知识即可使用。WISE支持图像和视频中场景级别(例如,空旷的街道)和对象级别(例如,马)的自然语言和反向图像查询;基于人脸的特定个体搜索;使用文本(例如,木头吱吱作响)或音频文件进行声学事件的音频检索;搜索自动转录的语音;以及按用户提供的元数据进行过滤。通过组合跨模态的查询可以获得丰富的见解——例如,通过应用对象查询“火车”和元数据查询“德国”从历史档案中检索德国火车,或者在某个地方搜索人脸。通过采用向量搜索技术,WISE可以扩展到支持对数百万张图像或数千小时视频的高效检索。其模块化架构有助于集成新模型。WISE可以本地部署用于私有或敏感的集合,并且已应用于各种实际用例。我们的代码是开源的,可在https://gitlab.com/vgg/wise/wise 获取。
🔬 方法详解
问题定义:现有搜索引擎通常专注于单一模态的检索,缺乏对多模态信息的有效整合。此外,许多现有的多模态检索系统需要用户具备专业的机器学习知识才能使用,限制了其应用范围。WISE旨在解决这些问题,提供一个易于使用、能够处理多种模态信息并支持大规模数据检索的搜索引擎。
核心思路:WISE的核心思路是将各种模态的信息(视觉、音频、文本、元数据)嵌入到统一的向量空间中,然后利用向量搜索技术进行高效检索。通过这种方式,用户可以使用自然语言、图像、音频等多种方式进行查询,并可以组合不同模态的查询条件,从而获得更丰富的检索结果。
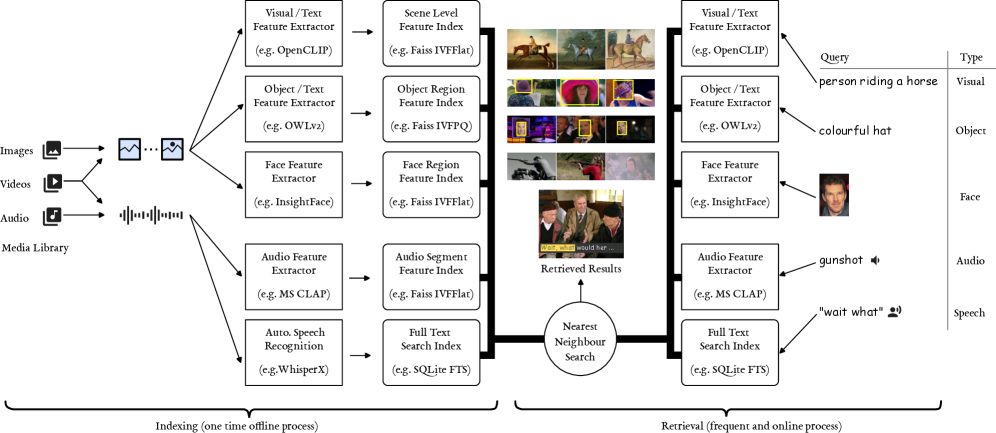
技术框架:WISE的整体架构是一个模块化的系统,包含以下主要模块:1) 特征提取模块:负责从各种模态的数据中提取特征向量。2) 向量索引模块:负责构建和维护特征向量的索引,以便进行高效的向量搜索。3) 查询处理模块:负责解析用户的查询,并将其转换为向量查询。4) 检索模块:负责在向量索引中搜索与查询向量最相似的向量,并返回相应的检索结果。5) 用户界面:提供用户友好的界面,方便用户进行查询和浏览检索结果。
关键创新:WISE最重要的技术创新点在于其多模态融合和向量搜索技术。通过将不同模态的信息嵌入到统一的向量空间中,WISE能够实现跨模态的检索。此外,WISE采用高效的向量搜索技术,可以支持对大规模数据的快速检索。与现有方法相比,WISE更加灵活、易于使用,并且能够处理更多种类的模态信息。
关键设计:WISE的关键设计包括:1) 使用预训练的深度学习模型提取各种模态的特征向量。2) 采用近似最近邻搜索(ANN)算法进行高效的向量搜索。3) 提供灵活的查询接口,允许用户组合不同模态的查询条件。4) 采用模块化架构,方便集成新的模型和功能。
🖼️ 关键图片

📊 实验亮点
WISE通过集成多种模态的检索能力,实现了高效且易于使用的多模态搜索引擎。该系统能够处理数百万张图像或数千小时的视频,并已应用于各种实际用例,证明了其在大规模视听数据检索方面的有效性和实用性。开源代码的发布也促进了该技术的进一步发展和应用。
🎯 应用场景
WISE可应用于各种领域,例如:数字图书馆、视频监控、内容审核、多媒体教学、智能安防等。它可以帮助用户快速找到所需的视听信息,提高工作效率,并为决策提供支持。未来,WISE有望成为一个通用的多模态信息检索平台,为各行各业提供服务。
📄 摘要(原文)
In this paper, we present WISE, an open-source audiovisual search engine which integrates a range of multimodal retrieval capabilities into a single, practical tool accessible to users without machine learning expertise. WISE supports natural-language and reverse-image queries at both the scene level (e.g. empty street) and object level (e.g. horse) across images and videos; face-based search for specific individuals; audio retrieval of acoustic events using text (e.g. wood creak) or an audio file; search over automatically transcribed speech; and filtering by user-provided metadata. Rich insights can be obtained by combining queries across modalities -- for example, retrieving German trains from a historical archive by applying the object query "train" and the metadata query "Germany", or searching for a face in a place. By employing vector search techniques, WISE can scale to support efficient retrieval over millions of images or thousands of hours of video. Its modular architecture facilitates the integration of new models. WISE can be deployed locally for private or sensitive collections, and has been applied to various real-world use cases. Our code is open-source and available at https://gitlab.com/vgg/wise/wise.