Motion Prior Distillation in Time Reversal Sampling for Generative Inbetweening
作者: Wooseok Jeon, Seunghyun Shin, Dongmin Shin, Hae-Gon Jeon
分类: cs.CV
发布日期: 2026-02-13 (更新: 2026-02-19)
备注: Accepted at ICLR 2026. Project page: https://vvsjeon.github.io/MPD/
💡 一句话要点
提出运动先验蒸馏方法,解决生成式视频插帧中的时序不连贯问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频插帧 生成模型 扩散模型 运动先验 蒸馏学习
📋 核心要点
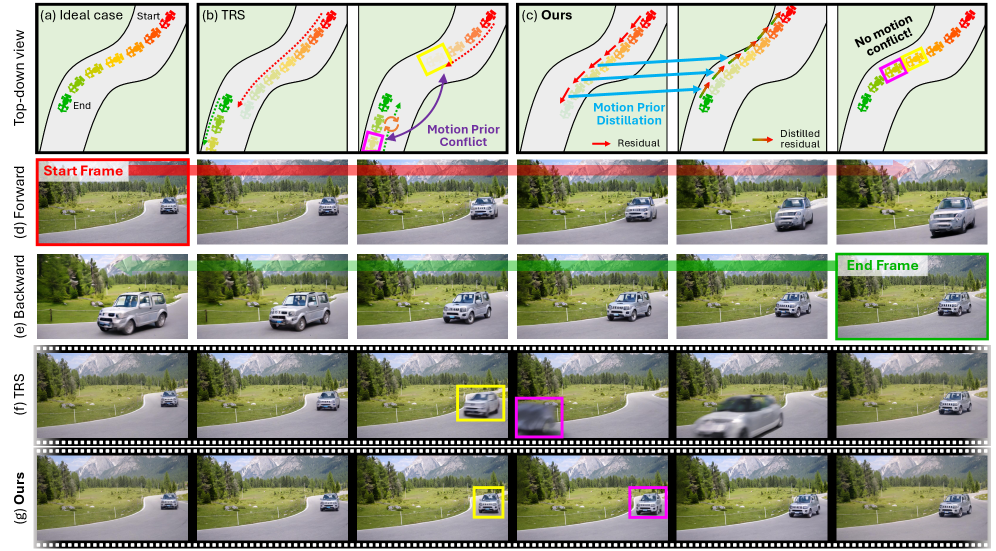
- 现有视频插帧方法在融合正向和反向路径时,由于运动先验不一致,容易产生时序不连贯和视觉伪影。
- 论文提出运动先验蒸馏(MPD)方法,将正向路径的运动残差提炼到反向路径,从而抑制双向不匹配。
- 实验结果表明,MPD方法在标准基准测试和用户研究中均表现出优越的性能,能够生成时间连贯性更好的插帧结果。
📝 摘要(中文)
图像到视频(I2V)扩散模型的最新进展显著推动了生成式视频插帧领域的发展,其目标是在两个关键帧之间生成语义上合理的帧。特别是,利用大规模预训练I2V模型的生成先验而无需额外训练的推理时采样策略,变得越来越流行。然而,现有的推理时采样,无论是并行融合正向和反向路径,还是顺序交替它们,通常会由于两条生成路径之间的不对齐而遭受时间不连续性和不良视觉伪影。这是因为每条路径都遵循由其自身条件帧引起的运动先验。在这项工作中,我们提出了运动先验蒸馏(MPD),这是一种简单而有效的推理时蒸馏技术,通过将正向路径的运动残差蒸馏到反向路径中来抑制双向不匹配。我们的方法可以有意识地避免对末端条件路径进行去噪,从而避免路径的模糊性,并产生具有前向运动先验的更具时间连贯性的插帧结果。我们不仅在标准基准上进行了定量评估,还进行了广泛的用户研究,以证明我们的方法在实际场景中的有效性。
🔬 方法详解
问题定义:论文旨在解决生成式视频插帧任务中,由于正向和反向扩散路径的运动先验不一致,导致生成视频帧在时间上不连贯,出现视觉伪影的问题。现有方法要么并行融合正反向路径,要么交替进行,但都无法有效解决运动先验的冲突,使得生成的视频帧在时间维度上出现跳变和不自然的过渡。
核心思路:论文的核心思路是通过运动先验蒸馏,将正向路径的运动信息传递给反向路径,从而使两条路径的运动先验对齐。具体来说,就是将正向路径的运动残差作为一种“指导”,融入到反向路径的生成过程中,使得反向路径在生成帧时,能够更好地遵循正向路径的运动趋势,从而减少两条路径之间的差异。
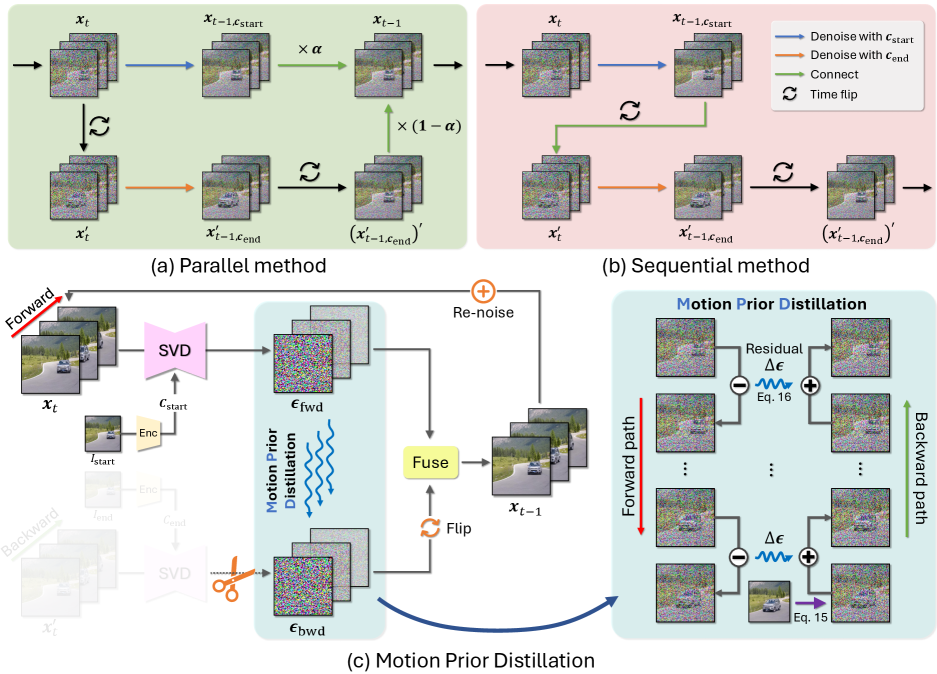
技术框架:MPD方法的整体框架基于时间反演采样。首先,利用正向扩散过程从起始帧生成噪声图像。然后,通过反向扩散过程,从噪声图像逐步恢复中间帧,同时利用运动先验蒸馏模块,将正向路径的运动残差信息注入到反向路径中。该过程迭代进行,直到生成最终的插帧结果。主要模块包括:正向扩散模块、反向扩散模块和运动先验蒸馏模块。
关键创新:论文的关键创新在于提出了运动先验蒸馏(MPD)技术,这是一种在推理时进行的蒸馏方法,不需要额外的训练。MPD通过将正向路径的运动残差注入到反向路径中,有效地对齐了正反向路径的运动先验,从而减少了时间不连贯性和视觉伪影。与现有方法相比,MPD避免了直接对末端条件路径进行去噪,减少了路径的模糊性,提高了生成结果的质量。
关键设计:MPD的关键设计在于如何有效地提取和利用正向路径的运动残差。具体来说,论文通过计算正向路径中相邻两个时间步的图像差异,得到运动残差。然后,将该运动残差作为条件信息,输入到反向扩散模型的去噪网络中,引导反向路径的生成过程。论文还可能涉及到对运动残差进行归一化或加权等处理,以更好地控制蒸馏的强度和效果。具体的损失函数设计可能包括重建损失和运动一致性损失等,以保证生成结果的质量和时间连贯性。
🖼️ 关键图片

📊 实验亮点
论文通过在标准基准测试上进行定量评估,证明了MPD方法的有效性。实验结果表明,MPD方法在生成视频插帧方面,能够显著提高时间连贯性和视觉质量。此外,论文还进行了广泛的用户研究,结果表明,用户更倾向于选择由MPD方法生成的视频插帧结果,这进一步验证了该方法在实际应用中的价值。
🎯 应用场景
该研究成果可广泛应用于视频编辑、电影制作、游戏开发等领域。例如,可以用于生成高质量的慢动作视频,修复老旧视频中的缺失帧,或者在游戏中创建更流畅的角色动画。此外,该技术还可以应用于虚拟现实和增强现实等新兴领域,提升用户体验和沉浸感。
📄 摘要(原文)
Recent progress in image-to-video (I2V) diffusion models has significantly advanced the field of generative inbetweening, which aims to generate semantically plausible frames between two keyframes. In particular, inference-time sampling strategies, which leverage the generative priors of large-scale pre-trained I2V models without additional training, have become increasingly popular. However, existing inference-time sampling, either fusing forward and backward paths in parallel or alternating them sequentially, often suffers from temporal discontinuities and undesirable visual artifacts due to the misalignment between the two generated paths. This is because each path follows the motion prior induced by its own conditioning frame. In this work, we propose Motion Prior Distillation (MPD), a simple yet effective inference-time distillation technique that suppresses bidirectional mismatch by distilling the motion residual of the forward path into the backward path. Our method can deliberately avoid denoising the end-conditioned path which causes the ambiguity of the path, and yield more temporally coherent inbetweening results with the forward motion prior. We not only perform quantitative evaluations on standard benchmarks, but also conduct extensive user studies to demonstrate the effectiveness of our approach in practical scenarios.