Vision Token Reduction via Attention-Driven Self-Compression for Efficient Multimodal Large Language Models
作者: Omer Faruk Deniz, Ruiyu Mao, Ruochen Li, Yapeng Tian, Latifur Khan
分类: cs.CV, cs.AI, cs.CL
发布日期: 2026-02-13
备注: 2025 IEEE International Conference on Big Data (BigData)
💡 一句话要点
提出ADSC,利用LLM注意力机制自压缩视觉tokens,提升多模态大模型的效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token压缩 注意力机制 模型剪枝 计算效率 KV-cache优化
📋 核心要点
- 现有MLLM处理大量视觉tokens导致计算成本高昂,且现有剪枝方法存在通用性不足或与FlashAttention不兼容的问题。
- ADSC利用LLM的注意力机制自适应地压缩视觉tokens,无需额外模块或修改注意力机制,与FlashAttention兼容。
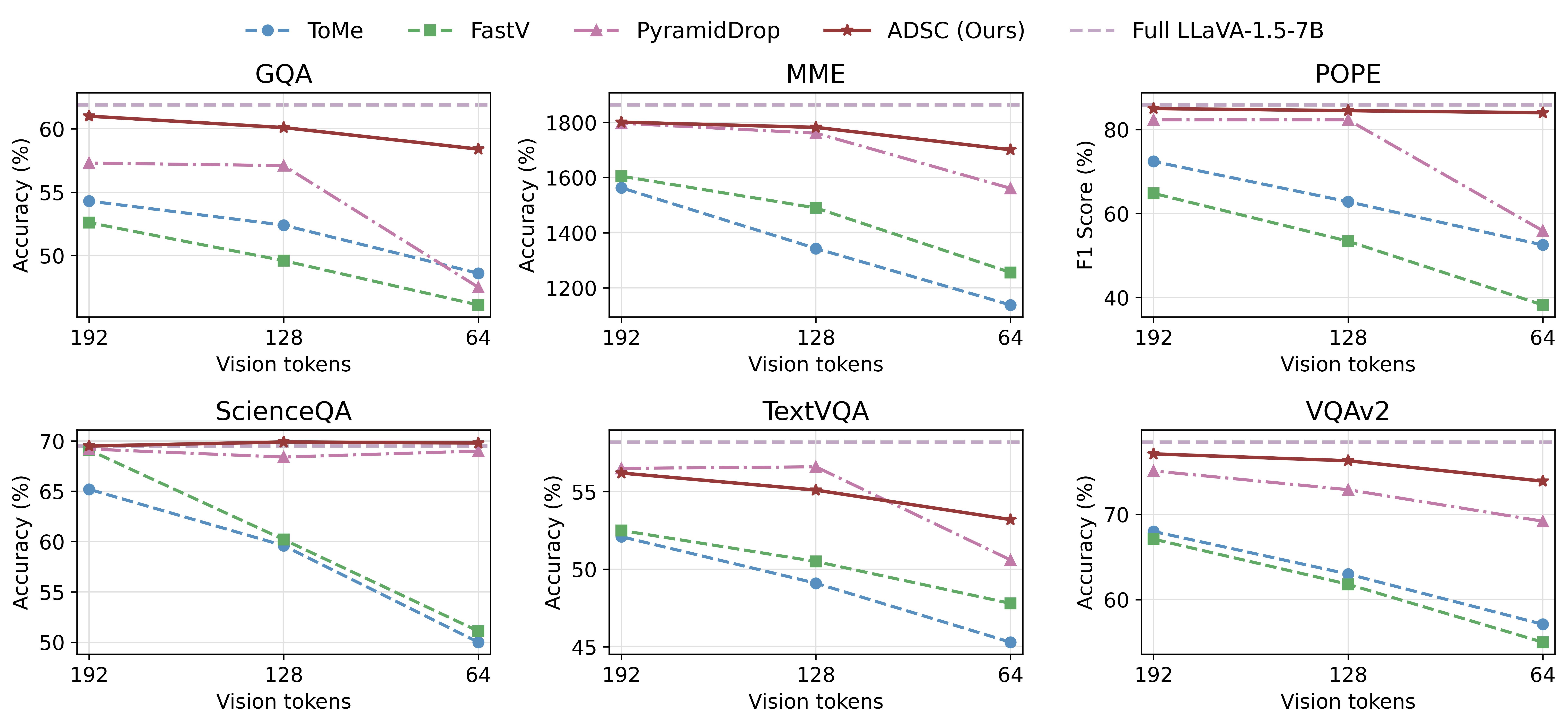
- 实验表明,ADSC在显著降低计算成本和内存占用的同时,保持了较高的模型性能,优于现有剪枝方法。
📝 摘要(中文)
多模态大型语言模型(MLLM)因需要通过所有LLM层处理大量的视觉tokens而产生巨大的计算成本。现有的剪枝方法要么在LLM之前操作,由于编码器-投影器设计的多样性而限制了通用性,要么在LLM内部使用与FlashAttention不兼容的启发式方法。本文采取了一种不同的方法:不是识别不重要的tokens,而是将LLM本身视为压缩的最佳指导。观察到更深层自然地传递视觉到文本的信息,本文引入了注意力驱动的自压缩(ADSC),这是一种简单、广泛适用的方法,仅使用LLM的注意力机制逐步减少视觉tokens。该方法在选定的层应用均匀的token下采样,形成瓶颈,鼓励模型将信息重组和压缩到剩余的tokens中。它不需要分数计算、辅助模块或注意力修改,并且与FlashAttention完全兼容。应用于LLaVA-1.5,ADSC减少了53.7%的FLOPs和56.7%的峰值KV-cache内存,同时保留了原始模型98.2%的性能。在多个基准测试中,它在效率和准确性方面都优于先前的剪枝方法。至关重要的是,在高压缩率下,本文的方法保持了鲁棒性,而基于启发式的方法则急剧下降。
🔬 方法详解
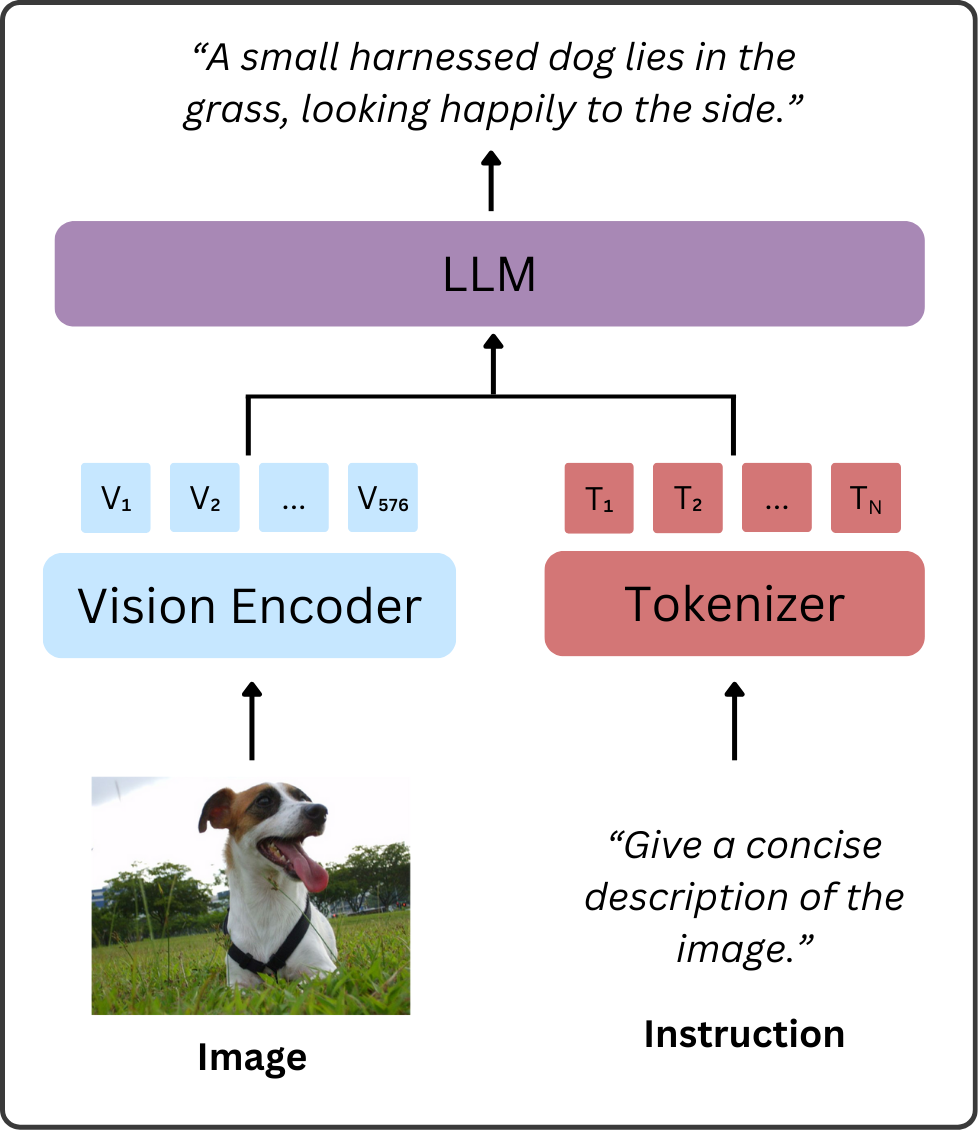
问题定义:多模态大语言模型(MLLM)在处理图像等视觉信息时,需要将图像分割成多个视觉tokens,并通过LLM进行处理。由于视觉tokens数量庞大,导致计算量和内存消耗巨大。现有的剪枝方法要么依赖于特定的编码器-投影器设计,通用性较差;要么与FlashAttention等高效计算框架不兼容,无法充分利用硬件加速。
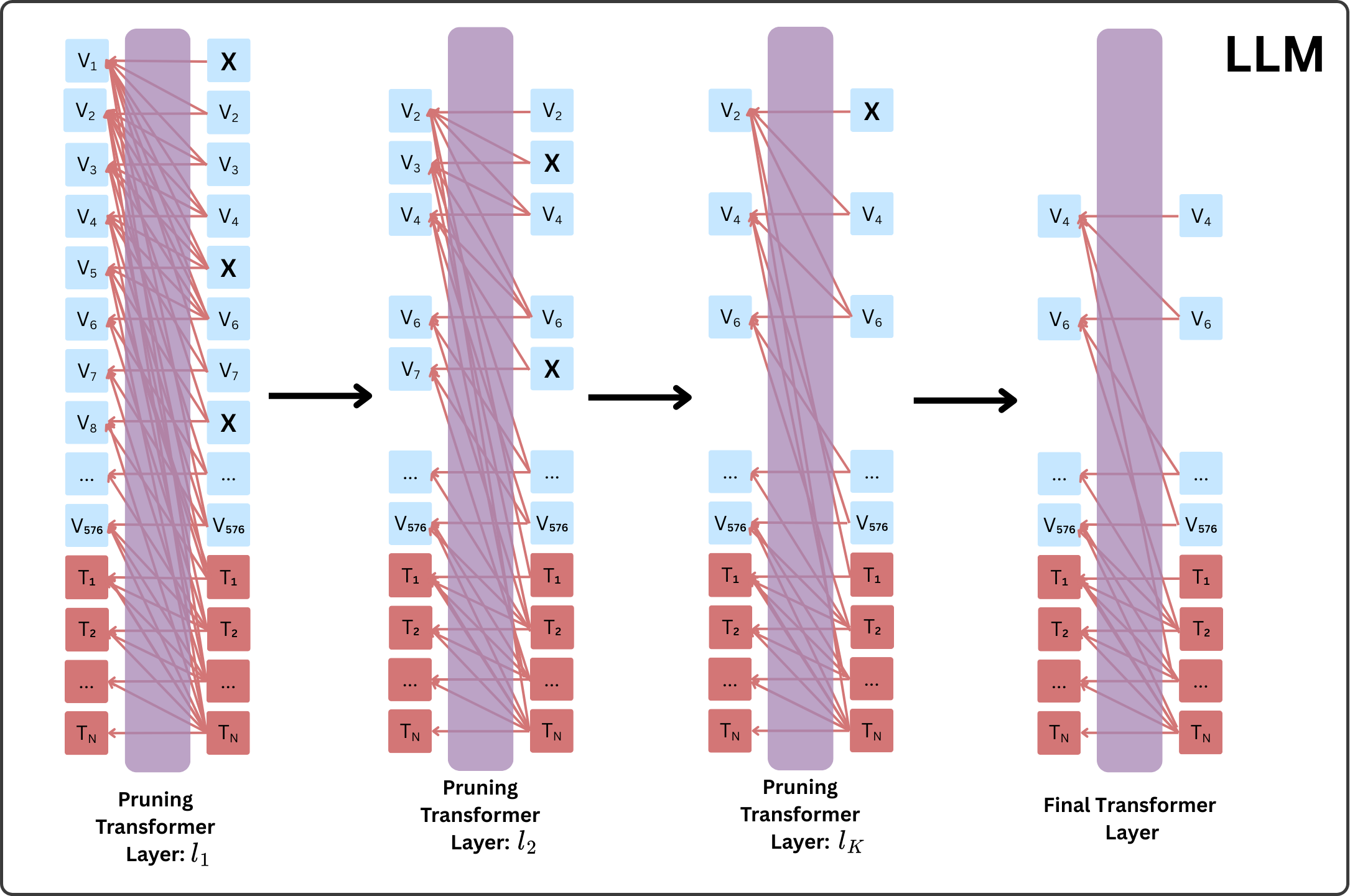
核心思路:论文的核心思路是利用LLM自身的注意力机制来指导视觉tokens的压缩。作者观察到,LLM的深层网络能够更好地提取视觉信息并将其融入文本信息中。因此,可以通过在LLM的特定层引入token下采样,形成信息瓶颈,迫使模型将重要信息压缩到剩余的tokens中。
技术框架:ADSC方法主要包含以下几个步骤:1)选择LLM中的若干层作为压缩层;2)在选定的压缩层中,对视觉tokens进行均匀下采样,减少tokens数量;3)在下采样后,模型继续进行前向传播,利用剩余的tokens进行后续处理。整个过程无需修改LLM的结构或训练方式。
关键创新:ADSC的关键创新在于利用LLM自身的注意力机制进行自压缩,无需额外的评分计算或辅助模块。与传统的剪枝方法相比,ADSC更加通用,可以应用于不同的MLLM架构,并且与FlashAttention等高效计算框架兼容。此外,ADSC通过在特定层引入信息瓶颈,迫使模型学习更有效的视觉信息表示。
关键设计:ADSC的关键设计包括:1)压缩层的选择:作者通过实验发现,选择LLM的中间层作为压缩层可以获得更好的性能;2)下采样比例:作者通过实验确定了合适的下采样比例,以在计算效率和模型性能之间取得平衡;3)均匀下采样:ADSC采用均匀下采样,避免了引入额外的偏差,保证了模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ADSC在LLaVA-1.5上减少了53.7%的FLOPs和56.7%的峰值KV-cache内存,同时保留了原始模型98.2%的性能。在多个基准测试中,ADSC在效率和准确性方面均优于现有的剪枝方法,尤其是在高压缩率下,ADSC表现出更强的鲁棒性。
🎯 应用场景
该研究成果可广泛应用于各种多模态大语言模型,尤其是在资源受限的场景下,如移动设备、边缘计算等。通过降低计算成本和内存占用,可以使MLLM在这些平台上更高效地运行,从而实现更广泛的应用,例如智能助手、图像理解、视频分析等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) incur significant computational cost from processing numerous vision tokens through all LLM layers. Prior pruning methods operate either before the LLM, limiting generality due to diverse encoder-projector designs or within the LLM using heuristics that are incompatible with FlashAttention. We take a different approach: rather than identifying unimportant tokens, we treat the LLM itself as the optimal guide for compression. Observing that deeper layers naturally transmit vision-to-text information, we introduce Attention-Driven Self-Compression (ADSC), a simple, broadly applicable method that progressively reduces vision tokens using only the LLM's attention mechanism. Our method applies uniform token downsampling at selected layers, forming bottlenecks that encourage the model to reorganize and compress information into the remaining tokens. It requires no score computation, auxiliary modules, or attention modification, and remains fully compatible with FlashAttention. Applied to LLaVA-1.5, ADSC reduces FLOPs by 53.7% and peak KV-cache memory by 56.7%, while preserving 98.2% of the original model performance. Across multiple benchmarks, it outperforms prior pruning approaches in both efficiency and accuracy. Crucially, under high compression ratios, our method remains robust while heuristic-based techniques degrade sharply.