QuEPT: Quantized Elastic Precision Transformers with One-Shot Calibration for Multi-Bit Switching
作者: Ke Xu, Yixin Wang, Zhongcheng Li, Hao Cui, Jinshui Hu, Xingyi Zhang
分类: cs.CV, cs.AI
发布日期: 2026-02-13
备注: Accepted by AAAI 2026
🔗 代码/项目: GITHUB
💡 一句话要点
QuEPT:一种用于Transformer的多比特切换的量化弹性精度单次校准方案。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 弹性精度量化 后训练量化 Transformer 多比特切换 低秩适配器 模型压缩 大型语言模型
📋 核心要点
- Transformer模型的巨大存储和优化成本限制了弹性量化的研究,尤其是在大型语言模型中。
- QuEPT通过单次校准重建分块多比特误差,动态适应不同比特宽度,并支持实时切换量化策略。
- 实验结果表明,QuEPT在性能上可与当前最优的后训练量化方法媲美甚至更优。
📝 摘要(中文)
本文提出QuEPT,一种高效的后训练量化方案,通过在小数据切片上进行单次校准来重建分块多比特误差。它可以通过级联不同的低秩适配器来动态适应各种预定义的比特宽度,并支持均匀量化和混合精度量化之间的实时切换,而无需重复优化。为了提高准确性和鲁棒性,我们引入了多比特Token融合(MB-ToMe),以动态融合跨不同比特宽度的token特征,从而提高比特宽度切换期间的鲁棒性。此外,我们提出了多比特级联低秩适配器(MB-CLoRA)来加强比特宽度组之间的相关性,进一步提高QuEPT的整体性能。大量实验表明,QuEPT实现了与现有最先进的后训练量化方法相当或更好的性能。
🔬 方法详解
问题定义:论文旨在解决Transformer模型在弹性精度量化中面临的挑战,特别是如何在不进行重复优化的情况下,支持多比特宽度之间的动态切换。现有方法通常需要针对每种比特宽度进行单独训练或微调,计算和存储成本高昂。此外,如何在不同比特宽度之间保持模型性能的鲁棒性也是一个关键问题。
核心思路:QuEPT的核心思路是利用单次校准来重建分块多比特误差,从而实现不同比特宽度之间的动态切换。通过级联不同的低秩适配器,模型可以灵活地适应各种预定义的比特宽度。此外,引入多比特Token融合(MB-ToMe)和多比特级联低秩适配器(MB-CLoRA)来提高模型在比特宽度切换时的鲁棒性和整体性能。
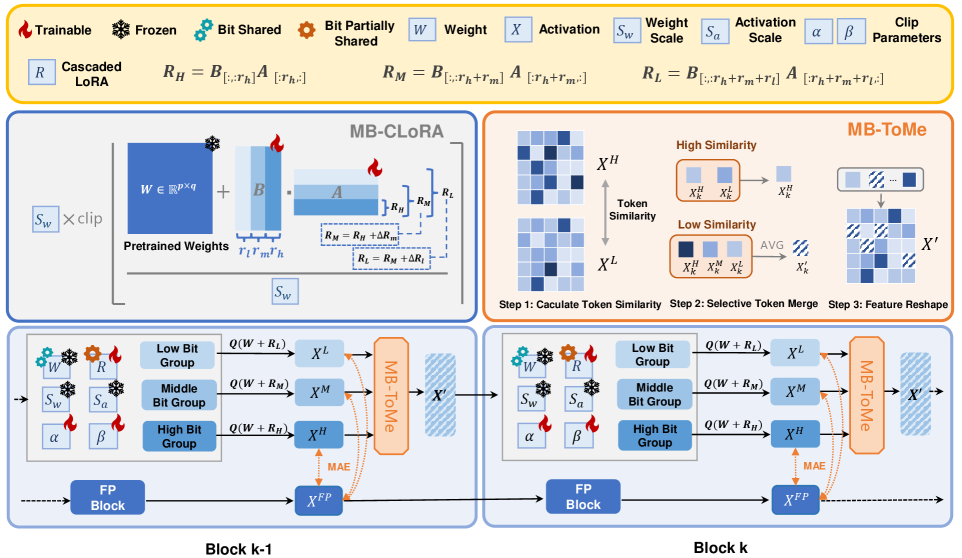
技术框架:QuEPT的整体框架包括以下几个主要模块:1) 量化模块:对Transformer模型的权重进行量化,支持均匀量化和混合精度量化。2) 单次校准模块:使用少量数据进行校准,重建分块多比特误差。3) 低秩适配器模块:级联不同的低秩适配器,以适应不同的比特宽度。4) 多比特Token融合(MB-ToMe)模块:动态融合跨不同比特宽度的token特征。5) 多比特级联低秩适配器(MB-CLoRA)模块:加强比特宽度组之间的相关性。
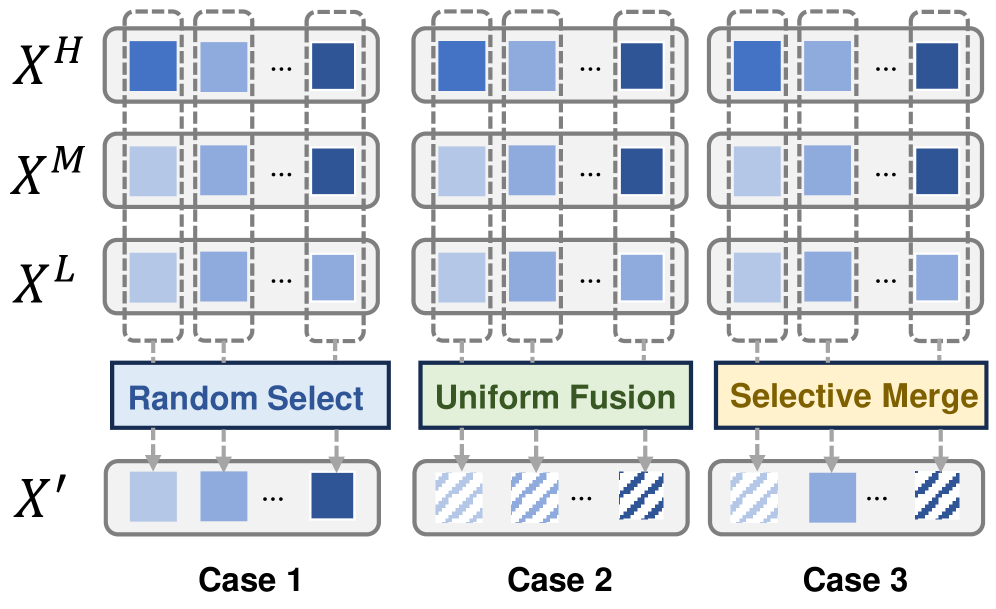
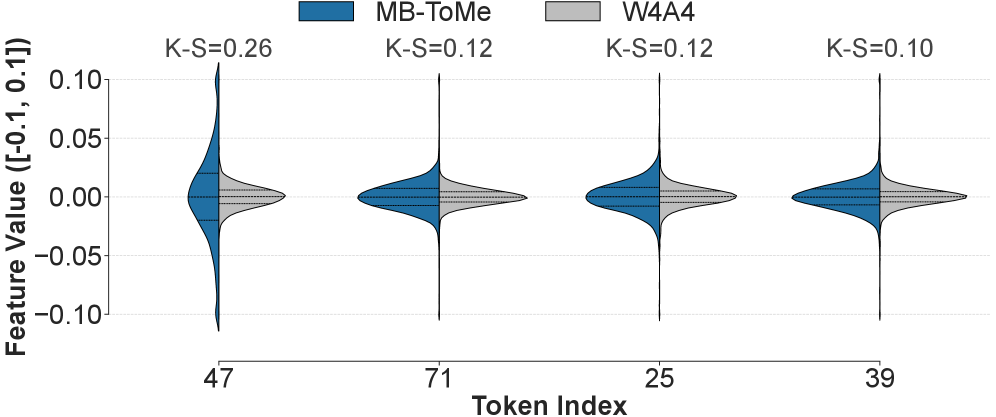
关键创新:QuEPT的关键创新在于:1) 单次校准的多比特误差重建:通过单次校准,模型可以快速适应不同的比特宽度,无需重复优化。2) 多比特Token融合(MB-ToMe):通过动态融合不同比特宽度的token特征,提高模型在比特宽度切换时的鲁棒性。3) 多比特级联低秩适配器(MB-CLoRA):通过加强比特宽度组之间的相关性,进一步提高模型的整体性能。
关键设计:QuEPT的关键设计包括:1) 分块量化:将Transformer模型分成多个块,对每个块进行独立的量化和校准。2) 低秩适配器的级联方式:通过精心设计的级联方式,模型可以灵活地适应不同的比特宽度。3) MB-ToMe的融合策略:采用动态加权的方式融合不同比特宽度的token特征,以提高鲁棒性。4) MB-CLoRA的连接方式:通过特定的连接方式,加强比特宽度组之间的相关性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,QuEPT在多个NLP任务上取得了与现有最先进的后训练量化方法相当或更好的性能。例如,在某些任务上,QuEPT的性能甚至超过了全精度模型。此外,QuEPT还展示了良好的比特宽度切换能力,可以在不同的比特宽度之间快速切换,而不会显著降低模型性能。这些结果表明,QuEPT是一种高效且实用的弹性精度量化方案。
🎯 应用场景
QuEPT具有广泛的应用前景,尤其是在资源受限的设备上部署大型语言模型。例如,它可以应用于移动设备、边缘计算设备和嵌入式系统中,以降低模型的存储和计算成本,同时保持较高的性能。此外,QuEPT还可以用于云端推理服务,以提高推理效率和降低运营成本。该研究的未来影响在于推动大型语言模型在更多场景下的应用。
📄 摘要(原文)
Elastic precision quantization enables multi-bit deployment via a single optimization pass, fitting diverse quantization scenarios.Yet, the high storage and optimization costs associated with the Transformer architecture, research on elastic quantization remains limited, particularly for large language models.This paper proposes QuEPT, an efficient post-training scheme that reconstructs block-wise multi-bit errors with one-shot calibration on a small data slice. It can dynamically adapt to various predefined bit-widths by cascading different low-rank adapters, and supports real-time switching between uniform quantization and mixed precision quantization without repeated optimization. To enhance accuracy and robustness, we introduce Multi-Bit Token Merging (MB-ToMe) to dynamically fuse token features across different bit-widths, improving robustness during bit-width switching. Additionally, we propose Multi-Bit Cascaded Low-Rank adapters (MB-CLoRA) to strengthen correlations between bit-width groups, further improve the overall performance of QuEPT. Extensive experiments demonstrate that QuEPT achieves comparable or better performance to existing state-of-the-art post-training quantization methods.Our code is available at https://github.com/xuke225/QuEPT