PLLM: Pseudo-Labeling Large Language Models for CAD Program Synthesis
作者: Yuanbo Li, Dule Shu, Yanying Chen, Matt Klenk, Daniel Ritchie
分类: cs.CV
发布日期: 2026-02-13
💡 一句话要点
提出PLLM,利用伪标签自训练CAD程序生成,解决无配对数据问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CAD程序合成 自训练 伪标签 大型语言模型 无监督学习
📋 核心要点
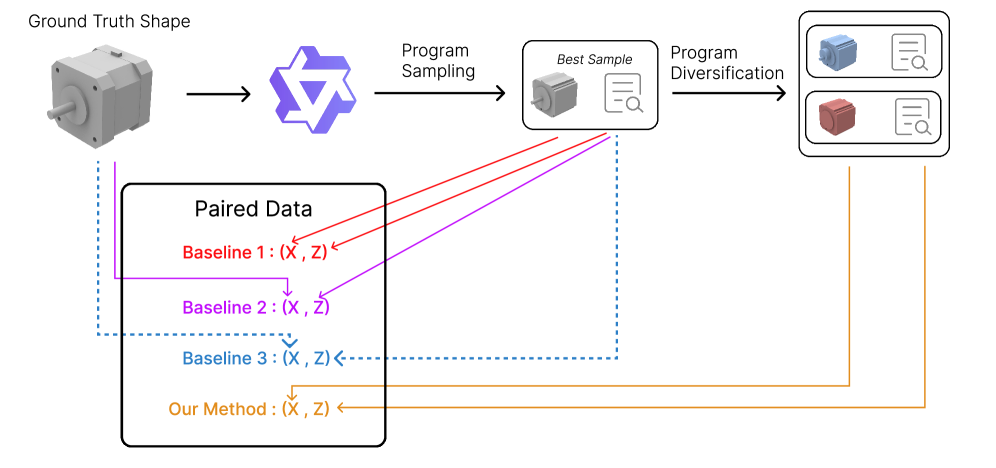
- 现有CAD程序合成方法依赖配对的形状-程序数据进行监督训练,但此类数据难以获取,限制了模型应用。
- PLLM通过自训练框架,迭代采样、选择和增强程序,构建合成数据对,从而在无标签数据上微调LLM。
- 实验表明,PLLM在几何保真度和程序多样性上均有提升,验证了其在无监督CAD程序合成中的有效性。
📝 摘要(中文)
本文提出了一种名为PLLM的自训练框架,用于从无标签3D形状数据集中合成CAD程序。该方法旨在解决现有CAD程序合成方法依赖于配对形状-程序数据进行监督训练的问题,而这种数据通常难以获取。PLLM框架利用预训练的、具备CAD能力的LLM,迭代地采样候选程序,选择高保真度的执行结果,并通过增强程序来构建合成的程序-形状对,用于微调LLM。在将DeepCAD中的CAD-Recode适配到无标签ABC数据集上的实验表明,PLLM在几何保真度和程序多样性方面均实现了持续改进。
🔬 方法详解
问题定义:论文旨在解决从3D几何形状恢复CAD程序的问题,现有方法主要依赖于有监督学习,需要大量的配对的形状-程序数据。然而,获取这种配对数据成本高昂,限制了这些方法在实际应用中的可行性。因此,如何在缺乏配对数据的情况下,有效地合成CAD程序是一个关键挑战。
核心思路:论文的核心思路是利用自训练方法,通过伪标签的方式,从无标签的3D形状数据中学习CAD程序的生成。具体来说,利用预训练的CAD-capable LLM生成候选程序,然后通过某种方式评估这些程序的质量,选择高质量的程序作为伪标签,并利用这些伪标签来微调LLM。这样,就可以在没有真实标签的情况下,提升LLM的CAD程序生成能力。
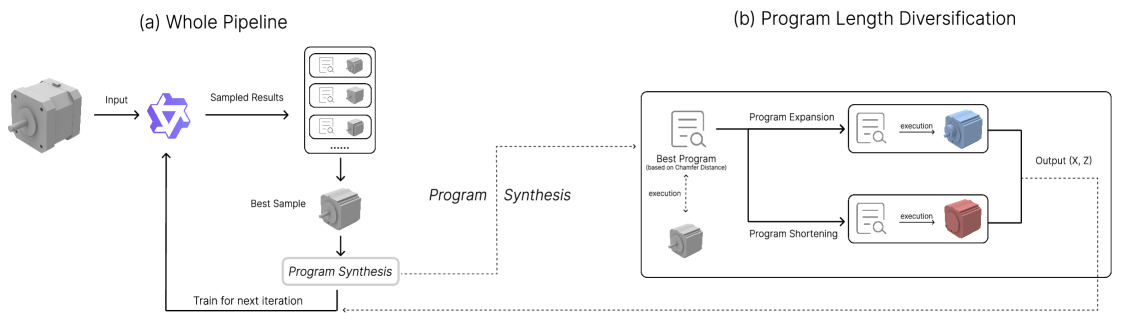
技术框架:PLLM的整体框架是一个迭代的自训练过程,主要包含以下几个阶段:1) 程序采样:利用预训练的LLM,从给定的3D形状中采样候选程序。2) 程序执行与评估:执行采样得到的程序,并评估其生成的3D形状与原始形状的相似度。3) 伪标签选择:根据评估结果,选择高保真度的程序作为伪标签。4) 数据增强:对选择的程序进行增强,生成更多的训练数据。5) 模型微调:利用生成的伪标签数据微调LLM。这个过程会迭代进行,直到模型收敛或达到预定的迭代次数。
关键创新:PLLM的关键创新在于它提出了一种有效的自训练框架,用于在无标签数据上进行CAD程序合成。与传统的有监督学习方法相比,PLLM不需要配对的形状-程序数据,从而大大降低了数据获取的成本。此外,PLLM通过迭代地采样、选择和增强程序,逐步提升LLM的CAD程序生成能力。
关键设计:在程序执行与评估阶段,需要设计合适的相似度度量指标,来评估生成形状与原始形状的相似度。在数据增强阶段,可以采用多种数据增强方法,例如随机改变程序的参数、添加噪声等。在模型微调阶段,可以选择合适的损失函数和优化器,来训练LLM。
🖼️ 关键图片
📊 实验亮点
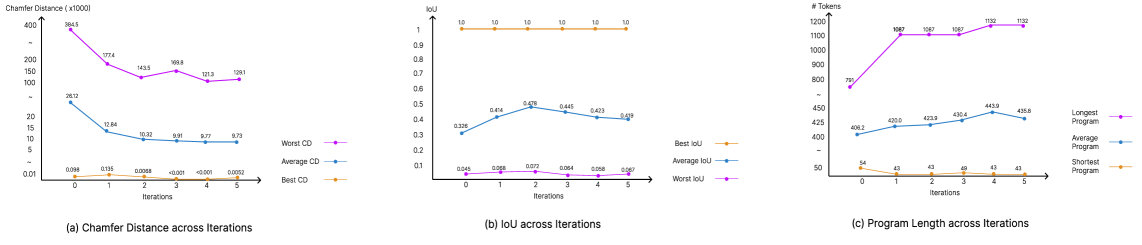
实验结果表明,PLLM能够有效地利用无标签的ABC数据集,提升CAD-Recode模型的性能。在几何保真度和程序多样性方面均取得了显著的改进。具体来说,PLLM能够生成更接近原始形状的CAD模型,并且生成的程序更加多样化,表明模型学习到了更丰富的CAD程序知识。
🎯 应用场景
该研究成果可应用于自动化CAD模型重建、逆向工程、以及基于草图的CAD模型生成等领域。通过自动生成CAD程序,可以大幅提高设计效率,降低设计成本,并促进CAD技术在更广泛领域的应用。未来,该技术有望应用于智能制造、建筑设计、游戏开发等多个行业。
📄 摘要(原文)
Recovering Computer-Aided Design (CAD) programs from 3D geometries is a widely studied problem. Recent advances in large language models (LLMs) have enabled progress in CAD program synthesis, but existing methods rely on supervised training with paired shape-program data, which is often unavailable. We introduce PLLM, a self-training framework for CAD program synthesis from unlabeled 3D shapes. Given a pre-trained CAD-capable LLM and a shape dataset, PLLM iteratively samples candidate programs, selects high-fidelity executions, and augments programs to construct synthetic program-shape pairs for fine-tuning. We experiment on adapting CAD-Recode from DeepCAD to the unlabeled ABC dataset show consistent improvements in geometric fidelity and program diversity.