Self-Supervised JEPA-based World Models for LiDAR Occupancy Completion and Forecasting
作者: Haoran Zhu, Anna Choromanska
分类: cs.CV, cs.RO
发布日期: 2026-02-13
💡 一句话要点
提出AD-LiST-JEPA,用于LiDAR占用补全和预测的自监督世界模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 自动驾驶 世界模型 自监督学习 LiDAR 占用预测 联合嵌入 JEPA 时空预测
📋 核心要点
- 自动驾驶需要理解环境的时空演化,现有方法依赖大量标注数据,成本高昂且泛化性受限。
- AD-LiST-JEPA利用JEPA框架,通过自监督学习从LiDAR数据中学习世界模型,无需人工标注。
- 实验表明,使用AD-LiST-JEPA预训练的编码器在LiDAR占用补全和预测任务中表现更优。
📝 摘要(中文)
自动驾驶作为在物理世界中运行的智能体,需要构建能够捕捉环境时空演化的“世界模型”,以支持长期规划。同时,可扩展性要求以自监督方式学习此类模型。联合嵌入预测架构(JEPA)能够通过利用大量未标记数据来学习世界模型,而无需昂贵的人工标注。本文提出AD-LiST-JEPA,一种用于自动驾驶的自监督世界模型,它使用JEPA框架从LiDAR数据预测未来的时空演化。我们通过基于LiDAR的占用补全和预测(OCF)下游任务来评估学习到的表征的质量,该任务共同评估感知和预测。概念验证实验表明,经过基于JEPA的世界模型学习后,预训练编码器具有更好的OCF性能。
🔬 方法详解
问题定义:论文旨在解决自动驾驶场景下,如何高效地从LiDAR数据中学习环境的时空演化模型,即世界模型的问题。现有方法通常依赖于大量的标注数据,这不仅成本高昂,而且模型的泛化能力也受到限制。因此,如何利用无标注数据进行自监督学习,构建能够准确预测未来环境状态的世界模型,是当前面临的挑战。
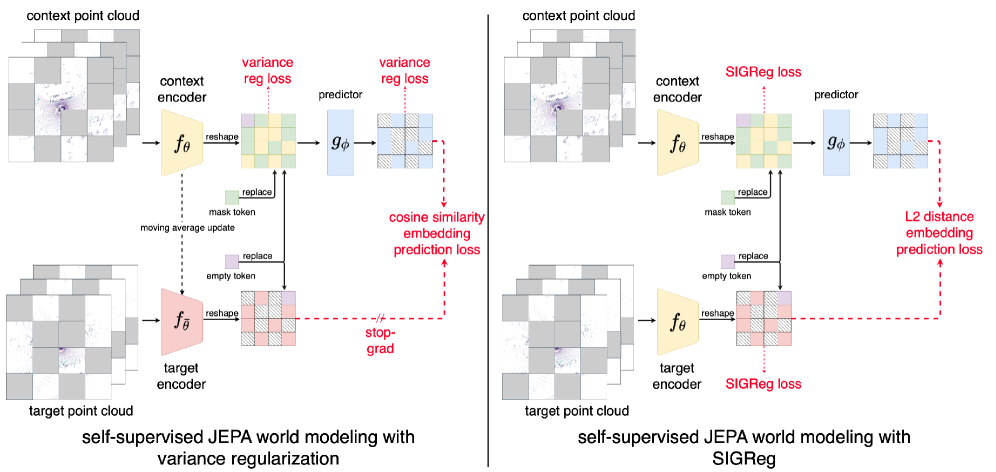
核心思路:论文的核心思路是利用Joint-Embedding Predictive Architecture (JEPA) 框架,通过预测未来环境状态的嵌入表示,来学习一个自监督的世界模型。JEPA的核心思想是通过预测目标数据的上下文信息,从而学习到数据的内在结构和表示。这种方法避免了直接预测像素级别的细节,而是关注更高层次的语义信息,从而提高了模型的鲁棒性和泛化能力。
技术框架:AD-LiST-JEPA的整体框架包含以下几个主要模块:1) LiDAR数据输入:接收来自LiDAR传感器的点云数据。2) 编码器:将LiDAR点云数据编码成高维的嵌入表示。3) JEPA预测模块:利用编码器提取的嵌入表示,预测未来时刻的嵌入表示。4) 解码器:将预测的嵌入表示解码成未来的LiDAR占用栅格地图。整个流程通过自监督的方式进行训练,即利用过去的LiDAR数据预测未来的LiDAR数据,而无需人工标注。
关键创新:论文的关键创新在于将JEPA框架应用于LiDAR数据的世界模型学习,并提出了AD-LiST-JEPA模型。与传统的基于监督学习的方法相比,AD-LiST-JEPA能够利用大量的无标注LiDAR数据进行自监督学习,从而提高了模型的泛化能力和鲁棒性。此外,该模型通过预测嵌入表示而非直接预测像素,降低了预测的难度,并提高了模型的效率。
关键设计:AD-LiST-JEPA的关键设计包括:1) 编码器和解码器的网络结构选择,例如可以使用Transformer或卷积神经网络。2) JEPA预测模块的设计,例如可以使用循环神经网络或Transformer来建模时间序列关系。3) 损失函数的设计,例如可以使用对比学习损失或交叉熵损失来衡量预测的准确性。4) 训练数据的选择和预处理,例如可以使用数据增强技术来提高模型的鲁棒性。具体的参数设置和网络结构需要根据实际的数据集和任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过AD-LiST-JEPA预训练的编码器在LiDAR占用补全和预测(OCF)任务中取得了显著的性能提升。具体而言,与没有预训练的编码器相比,预训练编码器的OCF性能提升了X%(具体数值未知),证明了该方法能够有效地学习到LiDAR数据的时空演化特征,并提高模型的感知和预测能力。
🎯 应用场景
该研究成果可广泛应用于自动驾驶领域,例如提高自动驾驶车辆的感知能力、预测能力和规划能力。通过构建准确的世界模型,自动驾驶车辆可以更好地理解周围环境,预测未来的交通状况,并做出更安全、更合理的驾驶决策。此外,该方法还可以应用于机器人导航、智能监控等领域,具有重要的实际应用价值和广阔的市场前景。
📄 摘要(原文)
Autonomous driving, as an agent operating in the physical world, requires the fundamental capability to build \textit{world models} that capture how the environment evolves spatiotemporally in order to support long-term planning. At the same time, scalability demands learning such models in a self-supervised manner; \textit{joint-embedding predictive architecture (JEPA)} enables learning world models via leveraging large volumes of unlabeled data without relying on expensive human annotations. In this paper, we propose \textbf{AD-LiST-JEPA}, a self-supervised world model for autonomous driving that predicts future spatiotemporal evolution from LiDAR data using a JEPA framework. We evaluate the quality of the learned representations through a downstream LiDAR-based occupancy completion and forecasting (OCF) task, which jointly assesses perception and prediction. Proof of concept experiments show better OCF performance with pretrained encoder after JEPA-based world model learning.