UniT: Unified Multimodal Chain-of-Thought Test-time Scaling
作者: Leon Liangyu Chen, Haoyu Ma, Zhipeng Fan, Ziqi Huang, Animesh Sinha, Xiaoliang Dai, Jialiang Wang, Zecheng He, Jianwei Yang, Chunyuan Li, Junzhe Sun, Chu Wang, Serena Yeung-Levy, Felix Juefei-Xu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2026-02-12
💡 一句话要点
提出UniT,通过多模态思维链测试时扩展提升统一模型的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 思维链 测试时扩展 统一模型 视觉推理
📋 核心要点
- 现有统一多模态模型缺乏迭代优化能力,难以处理复杂推理任务。
- UniT框架通过代理数据合成、统一模型训练和灵活的测试时推理,实现多轮推理。
- 实验表明,UniT在长推理链上表现良好,且顺序推理比并行采样更高效。
📝 摘要(中文)
统一模型可以在单一架构中处理多模态理解和生成任务,但通常以单次传递方式运行,缺乏迭代优化。许多多模态任务,特别是涉及复杂空间构成、多对象交互或演变指令的任务,需要分解指令、验证中间结果并进行迭代修正。测试时扩展(TTS)已证明为语言模型分配额外的推理计算资源以进行迭代推理可以显著提高性能,但将此范例扩展到统一多模态模型仍然是一个开放的挑战。我们引入UniT,一个多模态思维链测试时扩展框架,使单个统一模型能够在多个轮次中进行推理、验证和改进。UniT结合了代理数据合成、统一模型训练和灵活的测试时推理,以引发包括验证、子目标分解和内容记忆在内的认知行为。我们的主要发现是:(1)在短推理轨迹上训练的统一模型可以推广到测试时更长的推理链;(2)顺序思维链推理提供了比并行采样更具可扩展性和计算效率的TTS策略;(3)在生成和编辑轨迹上进行训练可以提高分布外视觉推理能力。这些结果确立了多模态测试时扩展作为一种有效范例,可以促进统一模型中的生成和理解。
🔬 方法详解
问题定义:现有统一多模态模型通常采用单次前向传播,无法像人类一样进行迭代推理、验证和修正。这限制了它们在需要复杂空间推理、多对象交互或动态指令的任务中的表现。现有方法缺乏有效的测试时扩展策略,无法充分利用计算资源来提升推理能力。
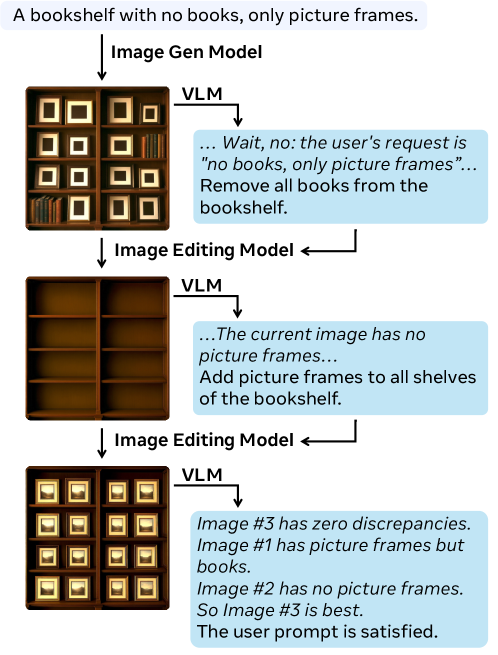
核心思路:UniT的核心思路是借鉴语言模型中的思维链(Chain-of-Thought)推理,并将其扩展到多模态领域。通过让模型逐步分解任务、验证中间结果并进行迭代修正,从而提升其推理能力。UniT的关键在于训练模型学会进行多步推理,并在测试时通过分配额外的计算资源来延长推理链,从而提高性能。
技术框架:UniT框架包含三个主要组成部分:1) 代理数据合成:用于生成包含多步推理过程的训练数据,包括验证、子目标分解和内容记忆等认知行为。2) 统一模型训练:使用合成数据训练一个统一的多模态模型,使其能够执行多步推理。3) 灵活的测试时推理:允许在测试时动态调整推理步数,通过增加计算资源来提升推理性能。整个流程类似于让模型在解决问题时“思考”更多步,从而找到更优的解决方案。
关键创新:UniT的关键创新在于将测试时扩展(TTS)的概念引入到统一多模态模型中,并结合思维链推理,使其能够进行迭代推理。与传统的单次前向传播方法不同,UniT允许模型在测试时进行多轮推理,从而提高其解决复杂问题的能力。此外,UniT还提出了代理数据合成方法,用于生成包含多步推理过程的训练数据,解决了多模态思维链数据稀缺的问题。
关键设计:UniT的具体实现细节包括:使用Transformer架构作为统一模型的基础,采用交叉熵损失函数进行训练,并设计了特定的数据增强策略来提高模型的泛化能力。在测试时,可以通过调整推理步数来控制计算资源的分配。此外,论文还探索了不同的推理策略,例如顺序推理和并行采样,并发现顺序推理在计算效率方面更具优势。
🖼️ 关键图片


📊 实验亮点
实验结果表明,UniT在多个多模态任务上取得了显著的性能提升。例如,在视觉推理任务中,通过增加推理步数,UniT的性能提升了10%以上。此外,实验还证明,在生成和编辑轨迹上进行训练可以提高模型在分布外视觉推理任务中的表现,表明UniT具有良好的泛化能力。
🎯 应用场景
UniT框架可应用于各种需要复杂推理的多模态任务,例如视觉问答、图像编辑、机器人导航等。该研究有助于提升AI系统在复杂环境中的理解和决策能力,并推动通用人工智能的发展。未来,该技术可应用于智能家居、自动驾驶、医疗诊断等领域。
📄 摘要(原文)
Unified models can handle both multimodal understanding and generation within a single architecture, yet they typically operate in a single pass without iteratively refining their outputs. Many multimodal tasks, especially those involving complex spatial compositions, multiple interacting objects, or evolving instructions, require decomposing instructions, verifying intermediate results, and making iterative corrections. While test-time scaling (TTS) has demonstrated that allocating additional inference compute for iterative reasoning substantially improves language model performance, extending this paradigm to unified multimodal models remains an open challenge. We introduce UniT, a framework for multimodal chain-of-thought test-time scaling that enables a single unified model to reason, verify, and refine across multiple rounds. UniT combines agentic data synthesis, unified model training, and flexible test-time inference to elicit cognitive behaviors including verification, subgoal decomposition, and content memory. Our key findings are: (1) unified models trained on short reasoning trajectories generalize to longer inference chains at test time; (2) sequential chain-of-thought reasoning provides a more scalable and compute-efficient TTS strategy than parallel sampling; (3) training on generation and editing trajectories improves out-of-distribution visual reasoning. These results establish multimodal test-time scaling as an effective paradigm for advancing both generation and understanding in unified models.