DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation
作者: Xu Guo, Fulong Ye, Qichao Sun, Liyang Chen, Bingchuan Li, Pengze Zhang, Jiawei Liu, Songtao Zhao, Qian He, Xiangwang Hou
分类: cs.CV
发布日期: 2026-02-12
备注: Project: https://guoxu1233.github.io/DreamID-Omni/
💡 一句话要点
DreamID-Omni:统一可控的以人为中心的音视频生成框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频生成 扩散模型 Transformer 多模态学习 人像生成 解耦表示 多任务学习
📋 核心要点
- 现有音视频生成方法通常将人像相关的任务孤立看待,缺乏统一框架,且难以对人物身份和音色进行精细解耦控制。
- DreamID-Omni通过对称条件扩散Transformer集成异构信号,并采用双层解耦策略解决身份-音色绑定问题,实现可控生成。
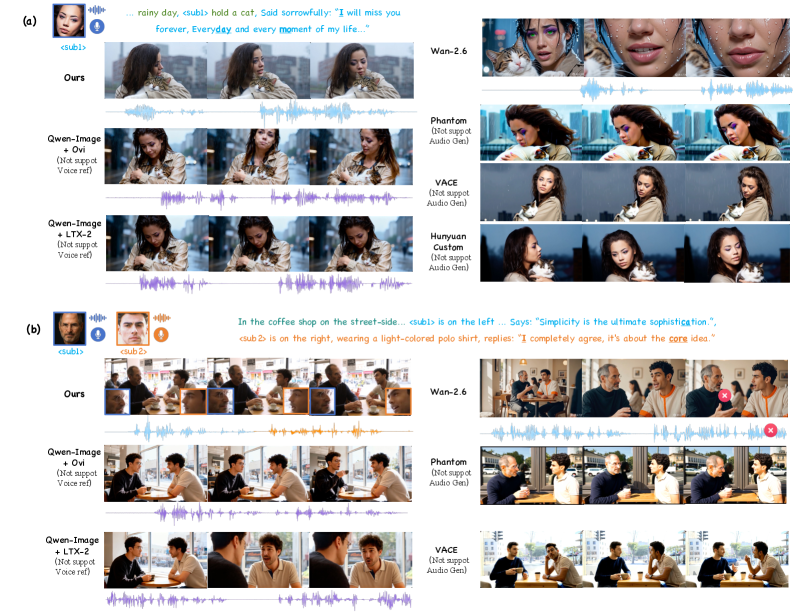
- 实验表明,DreamID-Omni在视频、音频和音视频一致性方面均达到SOTA,甚至超越商业模型,具有显著的性能提升。
📝 摘要(中文)
本文提出DreamID-Omni,一个统一的可控的以人为中心的音视频生成框架。现有方法通常将基于参考的音视频生成(R2AV)、视频编辑(RV2AV)和音频驱动的视频动画(RA2V)等任务视为孤立的目标。此外,在单个框架内实现对多个角色身份和声音音色的精确、解耦控制仍然是一个开放的挑战。DreamID-Omni设计了一个对称条件扩散Transformer,通过对称条件注入方案集成异构条件信号。为了解决多人场景中普遍存在的身份-音色绑定失败和说话人混淆问题,引入了双层解耦策略:信号层面的同步RoPE,以确保刚性的注意力空间绑定;语义层面的结构化字幕,以建立显式的属性-主体映射。此外,设计了一种多任务渐进训练方案,利用弱约束生成先验来规范强约束任务,防止过拟合并协调不同的目标。大量实验表明,DreamID-Omni在视频、音频和音视频一致性方面取得了全面的最先进的性能,甚至优于领先的专有商业模型。我们将发布我们的代码,以弥合学术研究和商业级应用之间的差距。
🔬 方法详解
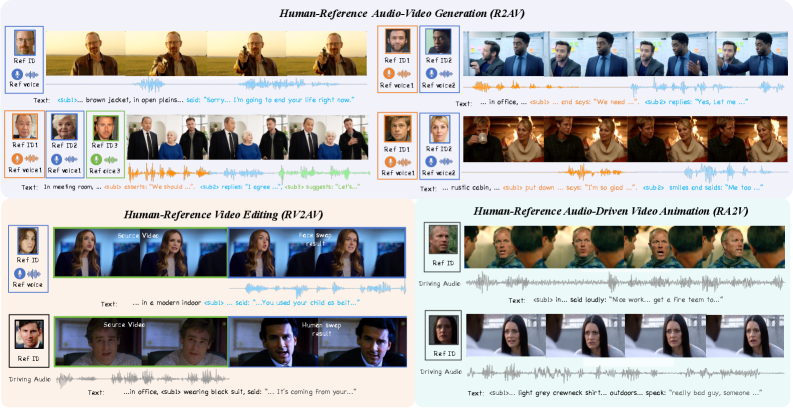
问题定义:现有音视频生成方法通常将参考音视频生成(R2AV)、视频编辑(RV2AV)和音频驱动的视频动画(RA2V)等任务孤立地处理,缺乏统一的框架。此外,在多人场景下,如何精确且解耦地控制多个角色的身份和声音音色是一个尚未解决的难题,容易出现身份-音色绑定失败和说话人混淆的问题。
核心思路:DreamID-Omni的核心思路是构建一个统一的框架,能够同时处理多种人像相关的音视频生成任务,并实现对人物身份和音色的精细控制。通过对称条件扩散Transformer集成异构条件信号,并引入双层解耦策略,解决身份-音色绑定问题,从而实现可控的音视频生成。
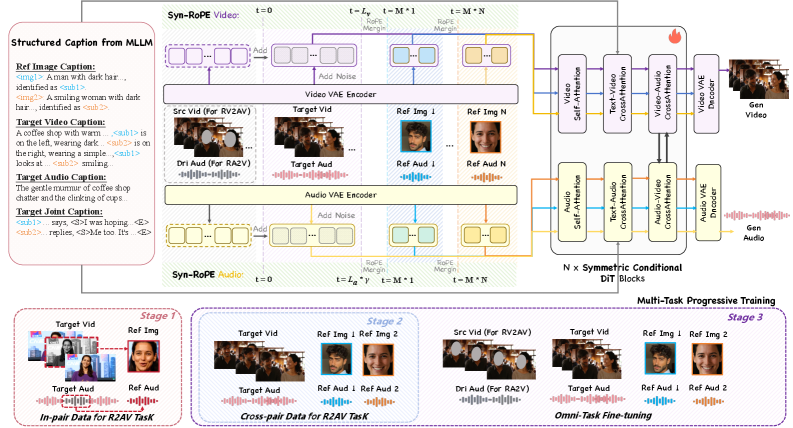
技术框架:DreamID-Omni的整体框架包含以下几个主要模块:1) 对称条件扩散Transformer:用于集成异构的条件信号,如参考图像、音频等。2) 双层解耦策略:包括信号层面的同步RoPE(Rotary Position Embedding)和语义层面的结构化字幕,用于解耦人物身份和音色。3) 多任务渐进训练方案:利用弱约束的生成先验来规范强约束的任务,防止过拟合,并协调不同的目标。
关键创新:DreamID-Omni的关键创新在于其统一的框架设计和双层解耦策略。传统的音视频生成方法通常针对特定任务进行设计,缺乏通用性。而DreamID-Omni通过统一的框架,可以同时处理多种任务。双层解耦策略则有效地解决了身份-音色绑定问题,使得可以独立控制人物的身份和音色。
关键设计:在信号层面,采用了同步RoPE来确保刚性的注意力空间绑定,从而区分不同人物的身份。在语义层面,使用了结构化字幕,通过显式的属性-主体映射来明确人物身份和音色之间的关系。此外,多任务渐进训练方案通过弱约束任务来正则化强约束任务,防止过拟合,并平衡不同任务之间的优化目标。具体的损失函数和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
DreamID-Omni在多个音视频生成任务上取得了SOTA性能,包括R2AV、RV2AV和RA2V。实验结果表明,该方法在视频质量、音频质量和音视频一致性方面均优于现有方法,甚至超越了领先的商业模型。具体的性能提升幅度和对比基线在论文中进行了详细描述(未知)。
🎯 应用场景
DreamID-Omni具有广泛的应用前景,包括虚拟偶像生成、电影制作、游戏开发、社交媒体内容创作等。它可以用于创建逼真且可控的虚拟角色,为用户提供个性化的音视频内容体验。该研究的突破将推动音视频生成技术的发展,并为相关产业带来巨大的商业价值。
📄 摘要(原文)
Recent advancements in foundation models have revolutionized joint audio-video generation. However, existing approaches typically treat human-centric tasks including reference-based audio-video generation (R2AV), video editing (RV2AV) and audio-driven video animation (RA2V) as isolated objectives. Furthermore, achieving precise, disentangled control over multiple character identities and voice timbres within a single framework remains an open challenge. In this paper, we propose DreamID-Omni, a unified framework for controllable human-centric audio-video generation. Specifically, we design a Symmetric Conditional Diffusion Transformer that integrates heterogeneous conditioning signals via a symmetric conditional injection scheme. To resolve the pervasive identity-timbre binding failures and speaker confusion in multi-person scenarios, we introduce a Dual-Level Disentanglement strategy: Synchronized RoPE at the signal level to ensure rigid attention-space binding, and Structured Captions at the semantic level to establish explicit attribute-subject mappings. Furthermore, we devise a Multi-Task Progressive Training scheme that leverages weakly-constrained generative priors to regularize strongly-constrained tasks, preventing overfitting and harmonizing disparate objectives. Extensive experiments demonstrate that DreamID-Omni achieves comprehensive state-of-the-art performance across video, audio, and audio-visual consistency, even outperforming leading proprietary commercial models. We will release our code to bridge the gap between academic research and commercial-grade applications.