GigaBrain-0.5M*: a VLA That Learns From World Model-Based Reinforcement Learning
作者: GigaBrain Team, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Jie Li, Jindi Lv, Jingyu Liu, Lv Feng, Mingming Yu, Peng Li, Qiuping Deng, Tianze Liu, Xinyu Zhou, Xinze Chen, Xiaofeng Wang, Yang Wang, Yifan Li, Yifei Nie, Yilong Li, Yukun Zhou, Yun Ye, Zhichao Liu, Zheng Zhu
分类: cs.CV
发布日期: 2026-02-12
备注: https://gigabrain05m.github.io/
💡 一句话要点
GigaBrain-0.5M*:基于世界模型的强化学习VLA模型,提升长时程操作任务性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 世界模型 强化学习 机器人操作 长时程规划
📋 核心要点
- 现有VLA模型在场景理解和未来预测方面存在局限性,难以处理复杂操作任务。
- GigaBrain-0.5M*利用大规模视频预训练的世界模型,提升VLA模型的时空推理和未来预测能力。
- 通过RAMP框架,GigaBrain-0.5M*在多个复杂操作任务上显著优于基线方法,提升约30%。
📝 摘要(中文)
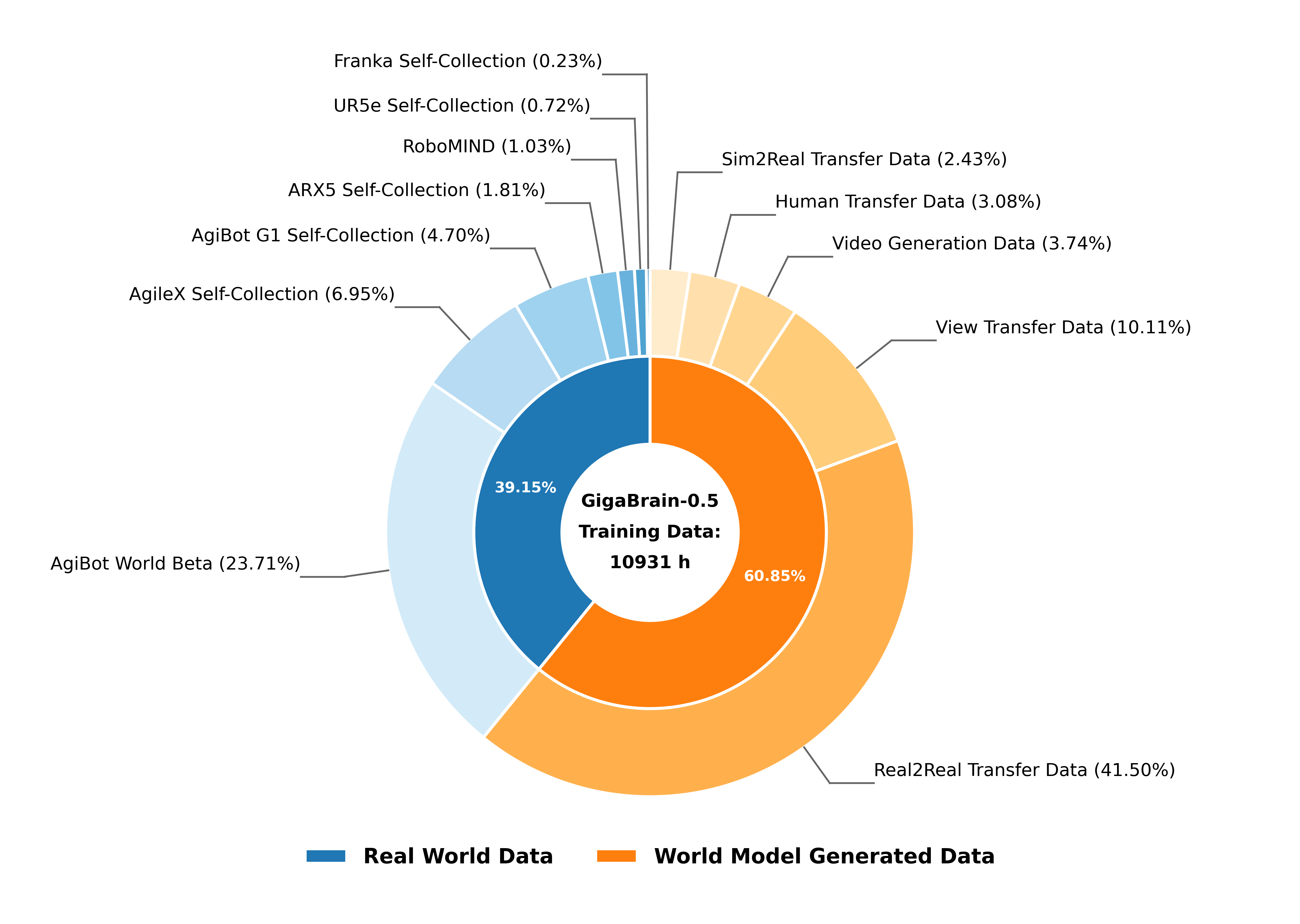
本文提出了GigaBrain-0.5M,一个通过基于世界模型的强化学习训练的视觉-语言-动作(VLA)模型。与直接预测多步动作块的VLA模型不同,GigaBrain-0.5M建立在预训练的GigaBrain-0.5之上,后者在超过10000小时的机器人操作数据上进行预训练,并在RoboChallenge基准测试中名列前茅。GigaBrain-0.5M进一步集成了基于世界模型的强化学习,通过RAMP(Reinforcement leArning via world Model-conditioned Policy)实现鲁棒的跨任务适应。实验结果表明,RAMP在包括洗衣折叠、盒子打包和浓缩咖啡制作等具有挑战性的任务上,相对于RECAP基线取得了显著的性能提升,提升幅度约为30%。GigaBrain-0.5M展现了可靠的长时程执行能力,能够持续完成复杂的操纵任务,这已通过项目页面上的真实部署视频得到验证。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在处理需要长时程规划和复杂操作的任务时,面临场景理解不足和未来动作预测能力弱的挑战。这些模型通常直接从当前观测预测多步动作块,缺乏对环境长期变化的建模能力,导致任务失败率较高。
核心思路:本文的核心思路是利用预训练的世界模型来增强VLA模型的时空推理和未来预测能力。世界模型通过学习大量视频数据,能够对环境的动态变化进行建模,从而为VLA模型提供更准确的未来状态预测,指导其进行更有效的动作规划。
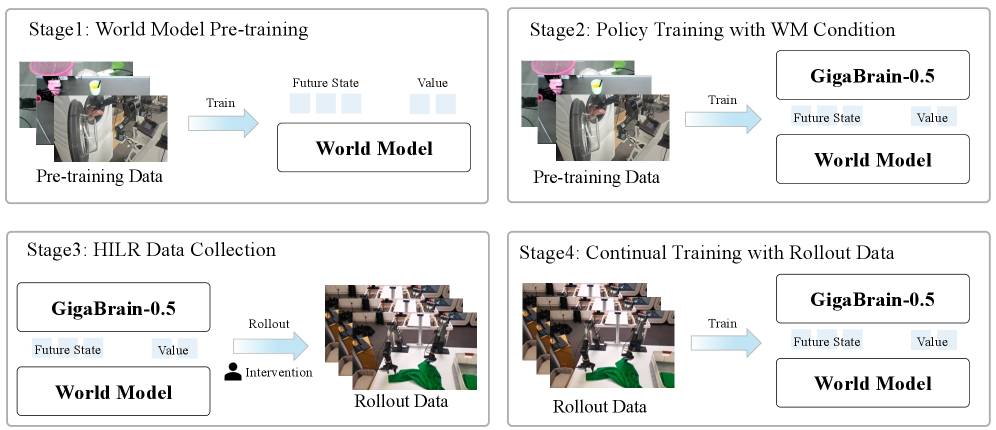
技术框架:GigaBrain-0.5M建立在预训练的GigaBrain-0.5之上,后者是一个在大量机器人操作数据上训练的VLA模型。GigaBrain-0.5M进一步集成了RAMP(Reinforcement leArning via world Model-conditioned Policy)框架,该框架利用世界模型来调节强化学习策略。具体而言,RAMP首先使用世界模型预测未来状态,然后基于预测的状态来优化动作策略,从而实现更鲁棒的跨任务适应。
关键创新:最重要的技术创新点在于将世界模型与强化学习相结合,通过世界模型来指导策略学习。与传统的强化学习方法相比,RAMP能够利用世界模型提供的未来信息,更有效地探索环境,学习到更优的策略。此外,RAMP还能够实现跨任务的知识迁移,从而提高VLA模型在不同任务上的泛化能力。
关键设计:RAMP框架的关键设计包括:1) 使用预训练的世界模型来预测未来状态;2) 设计一个基于预测状态的策略网络,用于生成动作;3) 使用强化学习算法(如PPO)来优化策略网络。具体的损失函数包括策略梯度损失、值函数损失和熵正则化损失。网络结构方面,使用了Transformer架构来处理视觉和语言输入,并使用MLP来生成动作。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GigaBrain-0.5M在洗衣折叠、盒子打包和浓缩咖啡制作等复杂操作任务上,相对于RECAP基线取得了显著的性能提升,提升幅度约为30%。此外,真实部署视频验证了GigaBrain-0.5M具有可靠的长时程执行能力,能够持续完成复杂的操纵任务。
🎯 应用场景
该研究成果可广泛应用于机器人自动化领域,例如智能家居服务机器人、工业自动化生产线、医疗辅助机器人等。通过提升机器人的操作能力和泛化性,可以实现更高效、更智能的自动化任务,从而提高生产效率和服务质量,并降低人力成本。
📄 摘要(原文)
Vision-language-action (VLA) models that directly predict multi-step action chunks from current observations face inherent limitations due to constrained scene understanding and weak future anticipation capabilities. In contrast, video world models pre-trained on web-scale video corpora exhibit robust spatiotemporal reasoning and accurate future prediction, making them a natural foundation for enhancing VLA learning. Therefore, we propose \textit{GigaBrain-0.5M}, a VLA model trained via world model-based reinforcement learning. Built upon \textit{GigaBrain-0.5}, which is pre-trained on over 10,000 hours of robotic manipulation data, whose intermediate version currently ranks first on the international RoboChallenge benchmark. \textit{GigaBrain-0.5M} further integrates world model-based reinforcement learning via \textit{RAMP} (Reinforcement leArning via world Model-conditioned Policy) to enable robust cross-task adaptation. Empirical results demonstrate that \textit{RAMP} achieves substantial performance gains over the RECAP baseline, yielding improvements of approximately 30\% on challenging tasks including \texttt{Laundry Folding}, \texttt{Box Packing}, and \texttt{Espresso Preparation}. Critically, \textit{GigaBrain-0.5M$^*$} exhibits reliable long-horizon execution, consistently accomplishing complex manipulation tasks without failure as validated by real-world deployment videos on our \href{https://gigabrain05m.github.io}{project page}.