Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception
作者: Lai Wei, Liangbo He, Jun Lan, Lingzhong Dong, Yutong Cai, Siyuan Li, Huijia Zhu, Weiqiang Wang, Linghe Kong, Yue Wang, Zhuosheng Zhang, Weiran Huang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2026-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出区域到图像蒸馏方法,提升多模态大模型在细粒度感知任务上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 细粒度感知 知识蒸馏 视觉问答 区域到图像 ZoomBench 大语言模型
📋 核心要点
- 现有MLLM在细粒度感知上表现不足,关键信息易被全局信息淹没,影响性能。
- 提出区域到图像蒸馏方法,将推理时的缩放操作转化为训练时的原语,提升模型性能。
- 实验表明,该方法在细粒度感知基准测试中表现领先,并提升了多模态认知能力。
📝 摘要(中文)
多模态大型语言模型(MLLM)擅长广泛的视觉理解,但在细粒度感知方面仍然存在困难,因为关键证据很小,容易被全局上下文淹没。最近的“图像思考”方法通过在推理过程中迭代地放大和缩小感兴趣区域来缓解这个问题,但由于重复的工具调用和视觉重新编码而导致高延迟。为了解决这个问题,我们提出了区域到图像蒸馏,将缩放从推理时工具转换为训练时原语,从而将代理缩放的优势内化到MLLM的单次前向传递中。具体来说,我们首先放大微裁剪区域,让强大的教师模型生成高质量的VQA数据,然后将这种区域相关的监督知识蒸馏回完整图像。在这样的数据上训练后,较小的学生模型提高了“单次浏览”的细粒度感知能力,而无需使用工具。为了严格评估这种能力,我们进一步提出了ZoomBench,这是一个混合注释的基准测试,包含845个VQA数据,涵盖六个细粒度感知维度,以及一个量化全局-区域“缩放差距”的双视图协议。实验表明,我们的模型在多个细粒度感知基准测试中取得了领先的性能,并且还提高了视觉推理和GUI代理等基准测试中的一般多模态认知能力。我们进一步讨论了何时需要“图像思考”,以及何时可以将其收益提炼到单次前向传递中。
🔬 方法详解
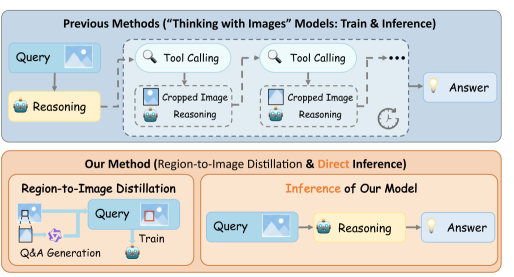
问题定义:现有的多模态大语言模型(MLLM)在处理细粒度视觉感知任务时面临挑战。这些任务通常需要模型关注图像中的微小区域以提取关键信息,而全局上下文容易淹没这些局部细节。为了解决这个问题,一些方法采用“图像思考”策略,即在推理时迭代地放大和缩小感兴趣区域,但这会导致高延迟,因为需要重复调用工具和重新编码视觉信息。
核心思路:本文的核心思路是将推理时的“缩放”操作转化为训练时的原语。通过在训练阶段模拟缩放过程,让模型学习如何关注图像中的关键区域,从而在推理时无需进行额外的缩放操作,实现高效的细粒度感知。这种方法通过知识蒸馏,将从局部区域获得的知识迁移到全局图像,使得模型能够“一眼”识别出细粒度特征。
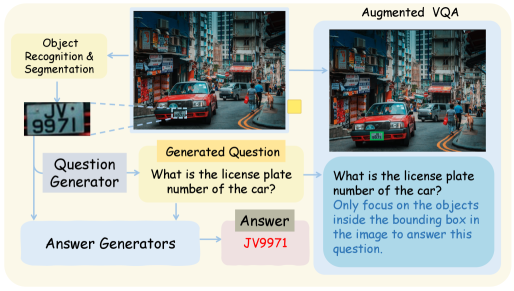
技术框架:该方法主要包含两个阶段:教师模型数据生成阶段和学生模型蒸馏训练阶段。在教师模型数据生成阶段,首先对图像进行微裁剪,得到一系列局部区域。然后,使用强大的教师模型(如大型MLLM)对这些局部区域进行视觉问答(VQA),生成高质量的VQA数据。在学生模型蒸馏训练阶段,使用生成的VQA数据对学生模型进行训练。训练目标是让学生模型能够从完整图像中预测出与教师模型在局部区域中预测的相同答案。
关键创新:该方法最重要的创新点在于将推理时的缩放操作转化为训练时的原语。与传统的“图像思考”方法相比,该方法无需在推理时进行额外的计算,从而大大提高了推理效率。此外,该方法还提出了一种新的数据生成方法,通过使用教师模型对局部区域进行VQA,生成高质量的训练数据。
关键设计:在数据生成阶段,需要选择合适的裁剪策略和教师模型。裁剪策略需要保证能够覆盖图像中的所有关键区域,而教师模型需要具有强大的视觉理解能力。在蒸馏训练阶段,可以使用各种损失函数来衡量学生模型和教师模型之间的差异,例如交叉熵损失或KL散度。此外,还可以使用一些正则化技术来防止学生模型过拟合。
🖼️ 关键图片
📊 实验亮点
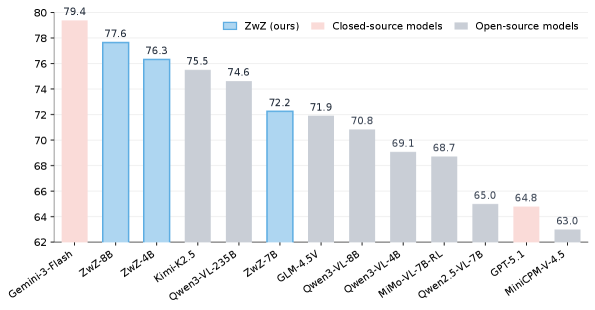
实验结果表明,该方法在多个细粒度感知基准测试中取得了领先的性能。例如,在ZoomBench基准测试中,该方法显著优于现有的MLLM模型。此外,该方法还提高了模型在视觉推理和GUI代理等任务中的性能,证明了其泛化能力。
🎯 应用场景
该研究成果可应用于需要细粒度视觉感知的领域,例如医学图像分析(检测病灶)、遥感图像分析(识别地物)、工业质检(检测缺陷)等。通过提升模型对局部细节的关注能力,可以提高这些应用场景中的准确性和效率,具有重要的实际应用价值。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) excel at broad visual understanding but still struggle with fine-grained perception, where decisive evidence is small and easily overwhelmed by global context. Recent "Thinking-with-Images" methods alleviate this by iteratively zooming in and out regions of interest during inference, but incur high latency due to repeated tool calls and visual re-encoding. To address this, we propose Region-to-Image Distillation, which transforms zooming from an inference-time tool into a training-time primitive, thereby internalizing the benefits of agentic zooming into a single forward pass of an MLLM. In particular, we first zoom in to micro-cropped regions to let strong teacher models generate high-quality VQA data, and then distill this region-grounded supervision back to the full image. After training on such data, the smaller student model improves "single-glance" fine-grained perception without tool use. To rigorously evaluate this capability, we further present ZoomBench, a hybrid-annotated benchmark of 845 VQA data spanning six fine-grained perceptual dimensions, together with a dual-view protocol that quantifies the global--regional "zooming gap". Experiments show that our models achieve leading performance across multiple fine-grained perception benchmarks, and also improve general multimodal cognition on benchmarks such as visual reasoning and GUI agents. We further discuss when "Thinking-with-Images" is necessary versus when its gains can be distilled into a single forward pass. Our code is available at https://github.com/inclusionAI/Zooming-without-Zooming.