Efficient Segment Anything with Depth-Aware Fusion and Limited Training Data
作者: Yiming Zhou, Xuenjie Xie, Panfeng Li, Albrecht Kunz, Ahmad Osman, Xavier Maldague
分类: cs.CV, eess.IV
发布日期: 2026-02-12
💡 一句话要点
提出深度感知融合的轻量级RGB-D分割框架,提升小样本下Segment Anything模型的性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 图像分割 深度学习 RGB-D融合 单目深度估计 几何先验 小样本学习 Segment Anything
📋 核心要点
- 现有Segment Anything模型依赖大规模RGB数据,计算成本高,且忽略了深度信息。
- 提出一种轻量级RGB-D融合框架,利用单目深度估计作为几何先验,增强分割性能。
- 实验表明,在极少量数据下,该方法优于EfficientViT-SAM,验证了深度信息的重要性。
📝 摘要(中文)
本文提出了一种轻量级的RGB-D融合框架,旨在提升Segment Anything模型(SAM)的效率。尽管SAM在通用分割任务中表现出色,但它依赖于庞大的数据集(例如,1100万张图像)并且仅使用RGB输入。现有的高效变体虽然降低了计算成本,但仍然需要大规模的训练数据。本文提出的方法通过单目深度先验增强了EfficientViT-SAM。利用预训练的深度估计器生成深度图,并通过专门的深度编码器将其与RGB特征进行中层融合。仅使用1.12万个样本(不到SA-1B的0.1%)进行训练,该方法就实现了比EfficientViT-SAM更高的精度,表明深度线索为分割提供了强大的几何先验。
🔬 方法详解
问题定义:Segment Anything Model (SAM) 虽然在图像分割领域表现出色,但其依赖于大规模的RGB图像数据集进行训练,计算资源消耗巨大。同时,SAM 忽略了深度信息这一重要的几何先验,限制了其在某些场景下的性能。现有的EfficientViT-SAM等方法虽然降低了计算成本,但仍然需要大量的训练数据。
核心思路:本文的核心思路是利用单目深度估计作为几何先验,通过深度信息增强EfficientViT-SAM的分割能力。通过将深度信息与RGB特征进行融合,模型可以更好地理解场景的几何结构,从而提高分割精度,尤其是在训练数据有限的情况下。
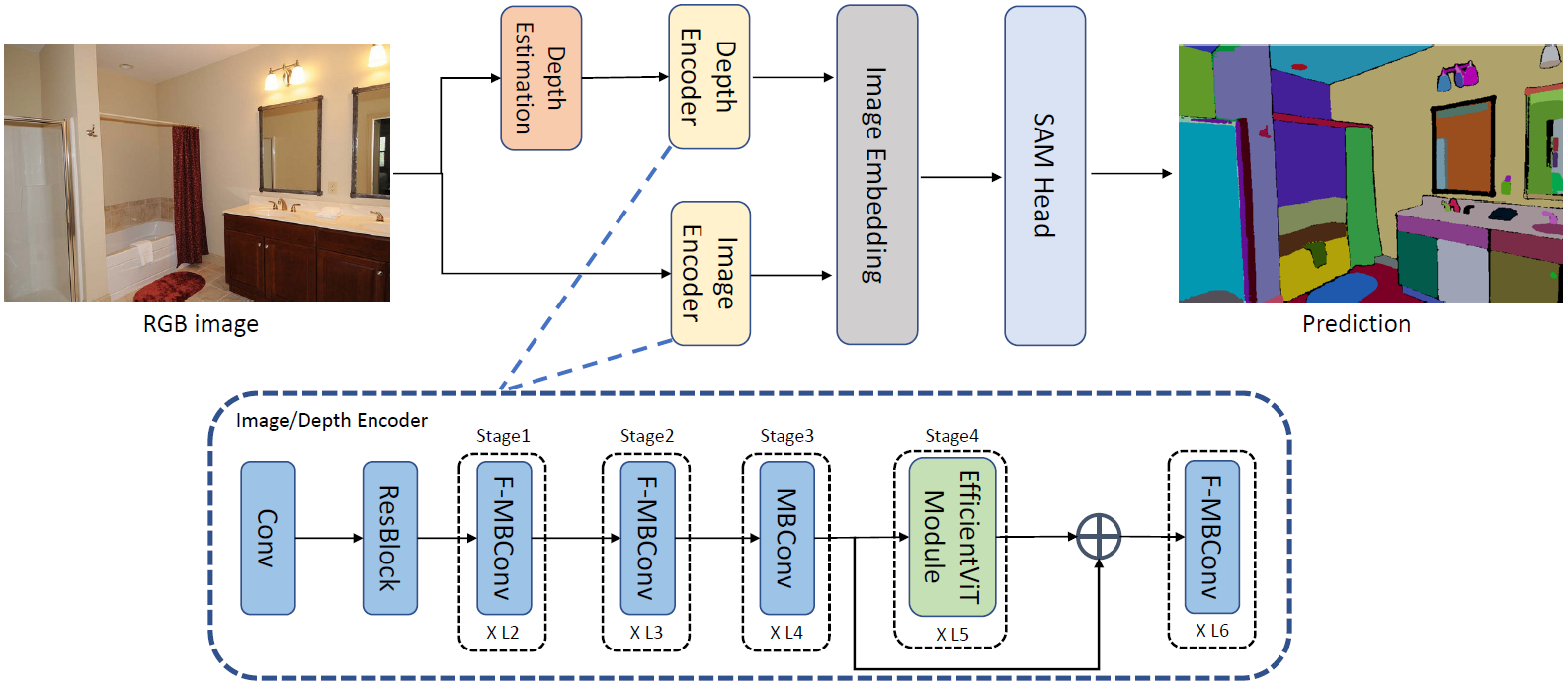
技术框架:该方法主要包含三个模块:RGB特征提取模块、深度估计模块和融合模块。首先,使用EfficientViT提取RGB图像的特征。然后,利用预训练的单目深度估计器生成深度图。最后,通过一个专门设计的深度编码器将深度图编码成特征,并与RGB特征进行中层融合。融合后的特征被送入分割头进行分割预测。
关键创新:该方法最重要的创新点在于将深度信息以一种高效的方式融入到EfficientViT-SAM中。与直接将深度图作为额外的通道输入不同,该方法使用深度编码器提取深度特征,并将其与RGB特征进行融合,从而更好地利用深度信息。此外,该方法仅需少量训练数据即可达到较好的性能,降低了训练成本。
关键设计:深度编码器采用轻量级卷积神经网络结构,以减少计算量。深度特征与RGB特征的融合方式采用简单的通道拼接或加权融合。损失函数采用标准的交叉熵损失函数,并可能加入深度一致性损失,以约束深度估计的准确性。训练过程中,采用数据增强技术,如随机裁剪、旋转和颜色抖动,以提高模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在仅使用SA-1B数据集0.1%的数据量(11.2k samples)进行训练的情况下,该方法在分割精度上优于EfficientViT-SAM。这表明深度信息能够为分割任务提供有效的几何先验,并且该方法能够有效地利用深度信息来提高分割性能。具体的性能提升数据(例如,mIoU指标)需要在论文中查找。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、三维重建、增强现实等领域。通过融合深度信息,可以提高场景理解的准确性和鲁棒性,尤其是在光照条件差或纹理信息不足的情况下。此外,该方法在小样本下的优越性能使其在数据获取成本高的场景中具有重要的应用价值。
📄 摘要(原文)
Segment Anything Models (SAM) achieve impressive universal segmentation performance but require massive datasets (e.g., 11M images) and rely solely on RGB inputs. Recent efficient variants reduce computation but still depend on large-scale training. We propose a lightweight RGB-D fusion framework that augments EfficientViT-SAM with monocular depth priors. Depth maps are generated with a pretrained estimator and fused mid-level with RGB features through a dedicated depth encoder. Trained on only 11.2k samples (less than 0.1\% of SA-1B), our method achieves higher accuracy than EfficientViT-SAM, showing that depth cues provide strong geometric priors for segmentation.