Mask What Matters: Mitigating Object Hallucinations in Multimodal Large Language Models with Object-Aligned Visual Contrastive Decoding
作者: Boqi Chen, Xudong Liu, Jianing Qiu
分类: cs.CV, cs.CL
发布日期: 2026-02-12
💡 一句话要点
提出对象对齐视觉对比解码,缓解多模态大语言模型中的对象幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 对象幻觉 视觉对比解码 对象对齐 自监督学习
📋 核心要点
- 多模态大语言模型存在对象幻觉问题,即生成内容与图像不符,影响模型可靠性。
- 通过移除图像中显著的对象视觉证据,构建辅助视图,增强视觉对比解码的对比信号。
- 实验表明,该方法在对象幻觉基准测试中取得一致性提升,且计算开销小,易于集成。
📝 摘要(中文)
本文研究了多模态大语言模型(MLLM)中的对象幻觉问题,并通过构建对象对齐的辅助视图来改进视觉对比解码(VCD)。我们利用自监督视觉Transformer中的对象中心注意力。具体来说,我们移除最显著的视觉证据来构建辅助视图,从而扰乱不支持的token并产生更强的对比信号。我们的方法与prompt无关,与模型无关,并且可以无缝地插入到现有的VCD流程中,计算开销很小,即只需一次可缓存的前向传播。实验结果表明,我们的方法在两个流行的对象幻觉基准测试和两个MLLM上都表现出一致的提升。
🔬 方法详解
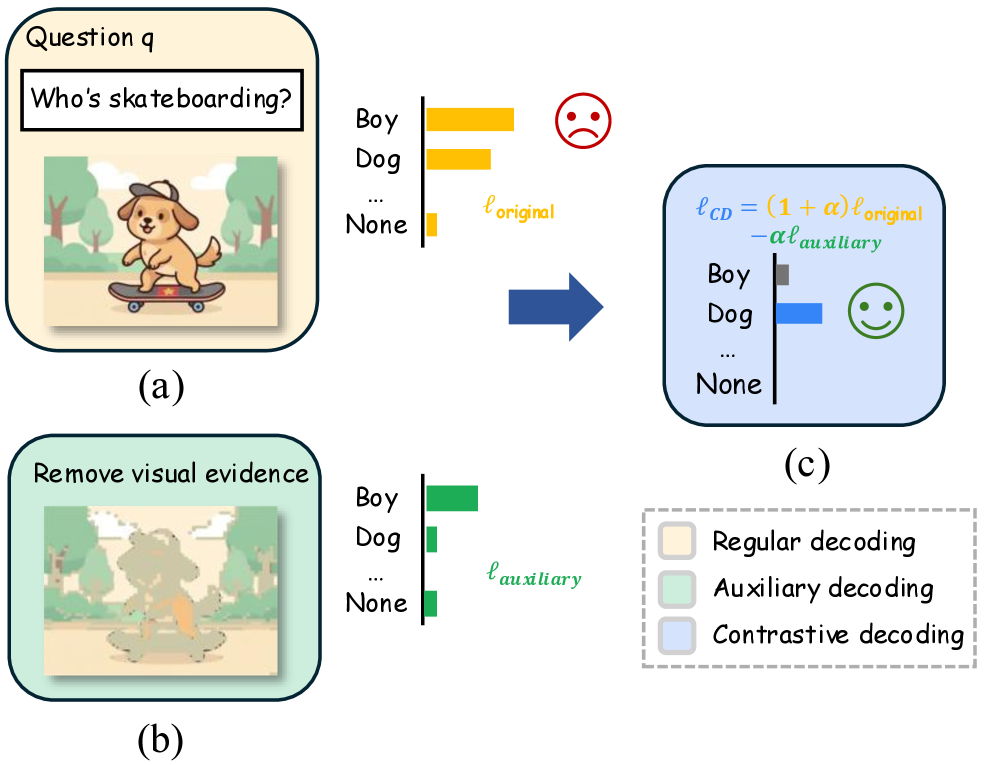
问题定义:多模态大语言模型(MLLMs)在生成描述图像内容的文本时,经常出现“对象幻觉”现象,即生成文本中包含图像中不存在的对象。现有方法,如视觉对比解码(VCD),试图通过对比不同视图来缓解这个问题,但效果有限,尤其是在缺乏明确prompt引导的情况下。
核心思路:论文的核心思路是构建一个“对象对齐”的辅助视图,该视图通过移除图像中最显著的视觉证据来扰乱那些基于幻觉的token。这样,在视觉对比解码过程中,可以产生更强的对比信号,从而抑制对象幻觉。这种方法的核心在于利用对象中心注意力机制来确定需要移除的视觉证据。
技术框架:整体框架是在现有的视觉对比解码(VCD)流程中加入一个对象对齐的辅助视图生成模块。首先,使用自监督视觉Transformer提取图像特征,并利用其对象中心注意力机制来确定图像中最重要的对象区域。然后,移除这些区域的视觉信息,生成辅助视图。最后,将原始图像和辅助视图输入MLLM,通过VCD来生成文本描述。
关键创新:关键创新在于对象对齐的辅助视图的构建方式。传统的VCD方法可能使用随机遮挡或其他方式生成辅助视图,但这些方法没有考虑到图像中不同区域的重要性。通过移除最显著的视觉证据,该方法能够更有效地扰乱那些基于幻觉的token,从而产生更强的对比信号。
关键设计:论文使用自监督视觉Transformer(例如DINO)来提取图像特征和对象中心注意力。具体来说,通过分析Transformer的注意力图,确定图像中注意力最高的区域,并将这些区域移除或遮挡,从而生成辅助视图。此外,该方法是prompt-agnostic和model-agnostic的,这意味着它可以应用于不同的prompt和MLLM,而无需进行特定的调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在两个流行的对象幻觉基准测试中,针对两个不同的MLLM(具体模型名称未知),均取得了持续的性能提升。由于论文中没有给出具体的数值,提升幅度未知。该方法的主要优势在于计算开销小,只需一次可缓存的前向传播,易于集成到现有系统中。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在图像描述、视觉问答等任务中的可靠性和准确性。在自动驾驶、医疗影像分析、智能客服等领域,减少对象幻觉可以提高系统的安全性和可信度,避免因错误信息导致的决策失误。未来,该方法可以进一步扩展到视频理解等更复杂的场景。
📄 摘要(原文)
We study object hallucination in Multimodal Large Language Models (MLLMs) and improve visual contrastive decoding (VCD) by constructing an object-aligned auxiliary view. We leverage object-centric attention in self-supervised Vision Transformers. In particular, we remove the most salient visual evidence to construct an auxiliary view that disrupts unsupported tokens and produces a stronger contrast signal. Our method is prompt-agnostic, model-agnostic, and can be seamlessly plugged into the existing VCD pipeline with little computation overhead, i.e., a single cacheable forward pass. Empirically, our method demonstrates consistent gains on two popular object hallucination benchmarks across two MLLMs.