Adapting Vision-Language Models for E-commerce Understanding at Scale
作者: Matteo Nulli, Vladimir Orshulevich, Tala Bazazo, Christian Herold, Michael Kozielski, Marcin Mazur, Szymon Tuzel, Cees G. M. Snoek, Seyyed Hadi Hashemi, Omar Javed, Yannick Versley, Shahram Khadivi
分类: cs.CV, cs.AI
发布日期: 2026-02-12
💡 一句话要点
针对电商场景,提出一种有效适配视觉-语言模型的大规模方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 电商理解 多模态学习 模型适配 大规模实验
📋 核心要点
- 通用视觉-语言模型在电商场景应用受限,缺乏针对属性、多图和噪声数据的有效适配策略。
- 论文提出一种针对性适配方法,旨在提升VLM在电商领域的性能,同时保持其通用多模态能力。
- 通过大规模实验,验证了该方法在电商任务上的有效性,并构建了新的评估基准。
📝 摘要(中文)
电子商务产品理解天然需要对文本、图像和结构化属性进行强大的多模态理解。通用视觉-语言模型(VLM)能够实现可泛化的多模态潜在建模,但目前还没有明确的策略,能够在不牺牲通用性能的情况下,将其适配到以属性为中心、多图像和嘈杂的电子商务数据。在这项工作中,我们通过大规模的实验研究表明,有针对性地调整通用VLM可以显著提高电子商务性能,同时保持广泛的多模态能力。此外,我们提出了一个新颖的广泛评估套件,涵盖深度产品理解、严格的指令遵循和动态属性提取。
🔬 方法详解
问题定义:电子商务产品理解需要强大的多模态理解能力,包括文本描述、产品图像和结构化属性。现有的通用视觉-语言模型(VLMs)虽然具有一定的多模态建模能力,但直接应用于电商场景时,由于电商数据的特殊性(属性驱动、多图关联、数据噪声大),往往表现不佳。缺乏一种有效的、针对电商数据的VLM适配策略,如何在提升电商任务性能的同时,避免牺牲VLM的通用能力,是一个关键问题。
核心思路:论文的核心思路是针对电商数据的特点,对通用的VLMs进行有针对性的适配。这种适配并非完全从头训练,而是利用预训练VLMs的知识,通过微调等方式,使其更好地适应电商场景。关键在于找到合适的适配策略,既能提升电商任务的性能,又能保留VLMs的通用多模态能力。
技术框架:论文构建了一个大规模的实验框架,用于评估不同VLM适配策略在电商场景下的性能。该框架包括:1)选择合适的预训练VLMs作为基础模型;2)设计不同的适配策略,例如微调特定层、引入特定任务的损失函数等;3)构建包含深度产品理解、严格指令遵循和动态属性提取等任务的评估套件;4)在大规模电商数据集上进行实验,比较不同适配策略的性能。
关键创新:论文的关键创新在于提出了一种针对电商场景的VLM适配方法,该方法能够在提升电商任务性能的同时,保持VLMs的通用多模态能力。此外,论文还构建了一个新的、全面的电商领域评估套件,为后续研究提供了基准。
关键设计:论文的具体技术细节未知,摘要中未提及具体的参数设置、损失函数或网络结构。但可以推测,关键设计可能包括:1)选择合适的预训练VLM架构(例如,CLIP、ALIGN等);2)设计针对电商属性预测或检索任务的损失函数;3)探索不同的微调策略,例如只微调特定层或引入adapter模块;4)数据增强策略,以应对电商数据的噪声问题。
🖼️ 关键图片
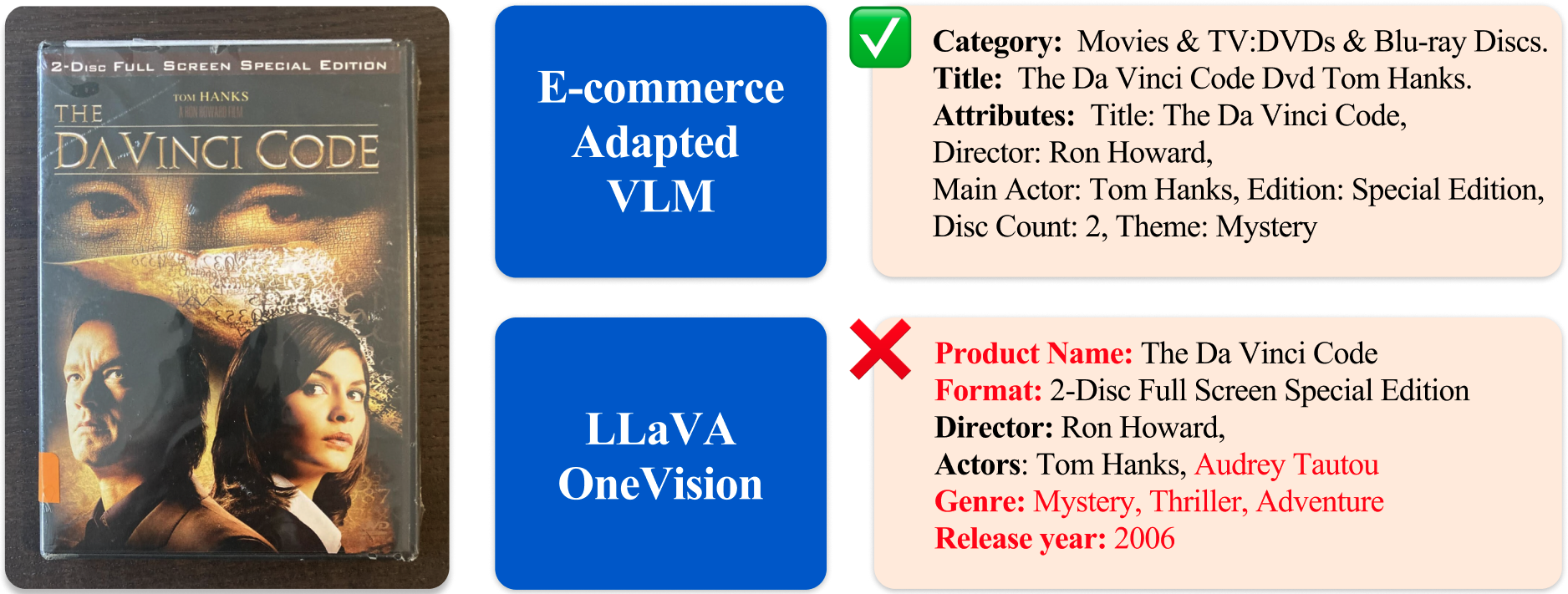

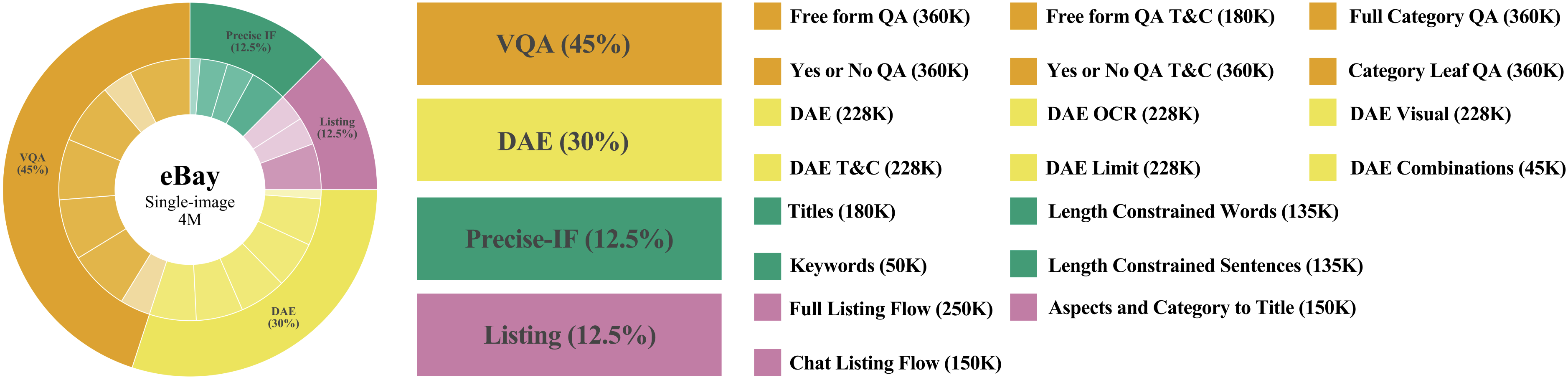
📊 实验亮点
论文通过大规模实验验证了所提出的VLM适配方法在电商场景下的有效性。具体性能数据未知,但摘要强调该方法能够在显著提高电商性能的同时,保持VLM的通用多模态能力。此外,论文构建的评估套件也为后续研究提供了重要的基准。
🎯 应用场景
该研究成果可广泛应用于电商领域的商品搜索、推荐、智能客服等场景。通过提升VLM对电商产品的理解能力,可以提高搜索结果的相关性、推荐的准确性,并实现更智能的客户服务。未来,该技术有望进一步推动电商领域的智能化升级,提升用户体验和运营效率。
📄 摘要(原文)
E-commerce product understanding demands by nature, strong multimodal comprehension from text, images, and structured attributes. General-purpose Vision-Language Models (VLMs) enable generalizable multimodal latent modelling, yet there is no documented, well-known strategy for adapting them to the attribute-centric, multi-image, and noisy nature of e-commerce data, without sacrificing general performance. In this work, we show through a large-scale experimental study, how targeted adaptation of general VLMs can substantially improve e-commerce performance while preserving broad multimodal capabilities. Furthermore, we propose a novel extensive evaluation suite covering deep product understanding, strict instruction following, and dynamic attribute extraction.